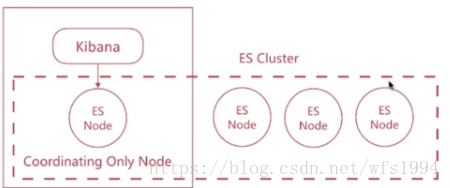
多个Elasticsearch节点间的负载均衡
如果 Elasticsearch 集群有多个节点,分发 Kibana 节点之间请求的最简单的方法就是在 Kibana 机器上运行一个 Elasticsearch 协调(Coordinating only node) 的节点。Elasticsearch 协调节点本质上是智能负载均衡器,也是集群的一部分,如果有需要,这些节点会处理传入 HTTP 请求,重定向操作给集群中其它节点,收集并返回结果。更多详细内容可以参考生产环境中使用kibana
创建Kibana可视化图表
kibana可视化图标的创建是基于Elasticsearch的Aggregations的,所以掌握Elasticsearch的聚合分析之后在创建可视化图形还是很简单的。
官网示例数据下载与导入
Kibana可视化中文文档
Elasticsearch 聚合分析详解
简单示例:
Timelion
基于自定义查询表达式的方式分析数据;相关函数可以进行链式调用。
Timelion表达式 -定义数据来源
Elasticsearch:.es(index=metricbeat-*)World Bank:.wbi(country=CN,indicator=NY.GDP.MKTP.CD),注意时间跨度选择大于1年,比如最近50年QuandlGraphite
.es():
index:指明查询的索引q:指明查询条件metric:指明展示指标,默认是个数split:按照某字段分组数据offset:设定时间便宜值,比如 -1d,将昨天的数据展示到当前值
.es(index=logstash-*,q=geo.src.keyword:CN,metric=sum:bytes,split=machine.os.keyword:3,offset=-1d)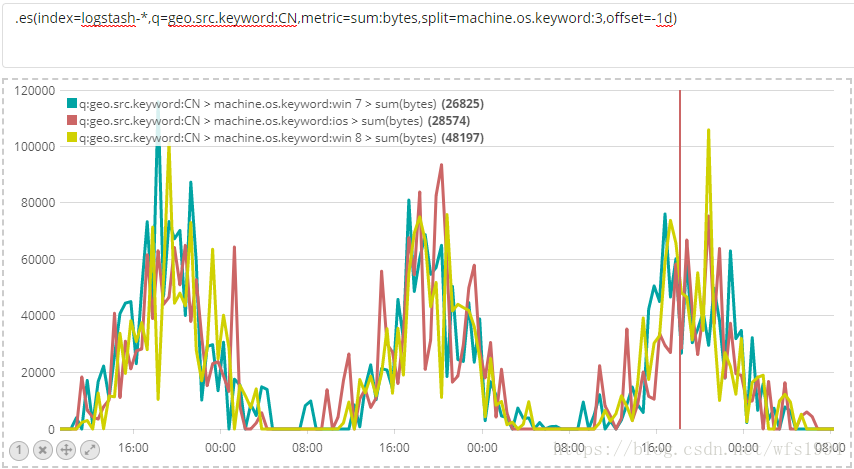
.es(index=logstash-*,q=geo.src.keyword:CN,metric=sum:bytes,offset=-1d).label(yesterday),.es(index=logstash-*,q=geo.src.keyword:CN,metric=sum:bytes).label(today)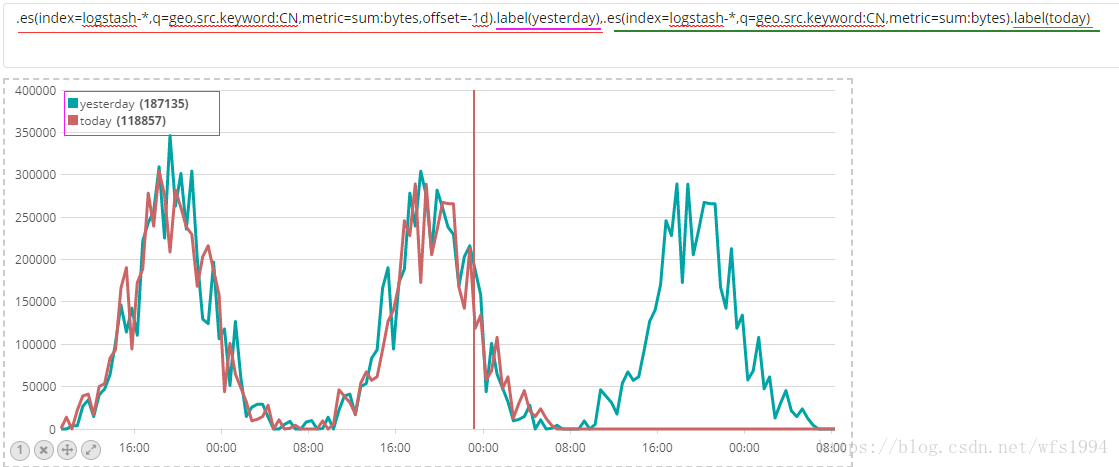
展示相关函数:
.title:设定该图标的名称.label:设定该组数据的图例名称.legend:设定图例的展示样式和位置.yaxis:设定y轴个数和样式.color:颜色设置- 数据展现样式:
.lines: 线、.points: 点、.bars
.es().label('cpu').points().color(red).legend(columns=2).yaxis(2).title('cpu info')计算相关函数:
对.es()查询出的数据进行统一的运算处理
abs: 绝对值log: 对数cusum: 累加derivative: 求导mvavg: 移动平均trend: 趋势值
.es().abs().cusum()范围控制相关函数:
range: 控制坐标轴范围,方便比较不同计量单位的数据yaxis(2): 添加新坐标scaled_interval: 修改计算间隔到指定的单位,比较方便
(.es(),.es(metric=sum:bytes)).range(0,1000)
.es(),.es(metric=sum:bytes).yaxis(2)
.es(metric=sum:bytes).scaled_interval(1s)
系列数据运算相关函数:
add/plus: 相加substract: 相减multiply: 相乘divide: 相除
.es(CN).divide(.es()).multiply(100) #计算百分比
条件判断相关函数:
min/max: 对数据进行截断处理if: 条件判断
.es().bars(stack=false).color(#F44336),min(.es(),200).bars(stack=false).color(#8BC34A)
.es(),.es().if(lt,500,0,800).points()
实例:
.es(index=logstash-*,q='geo.src.keyword:CN').label('CN'),.es(index=logstash-*,q='geo.src.keyword:US').label('US').title('request count of CN and US')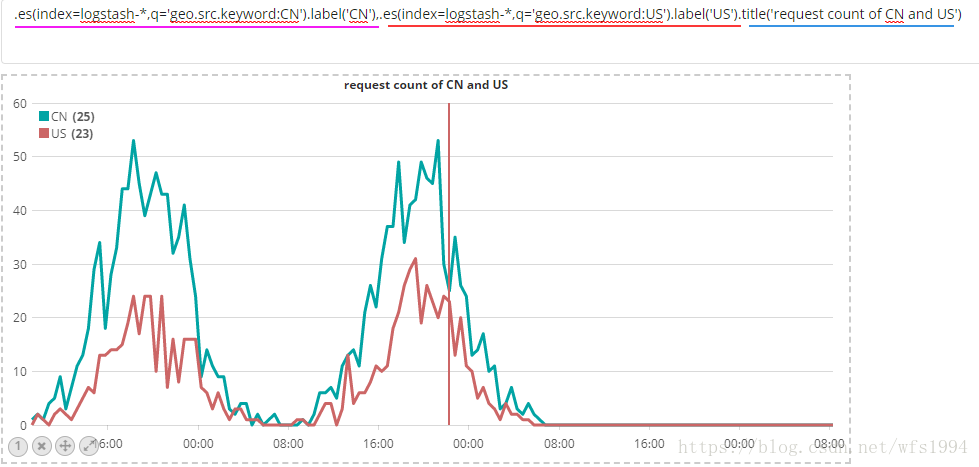
.es(index=logstash-*,split='geo.src.keyword:5',metric=sum:bytes).label(label="$1",regex=".*geo.src.keyword\:(\w+).*").title("split example")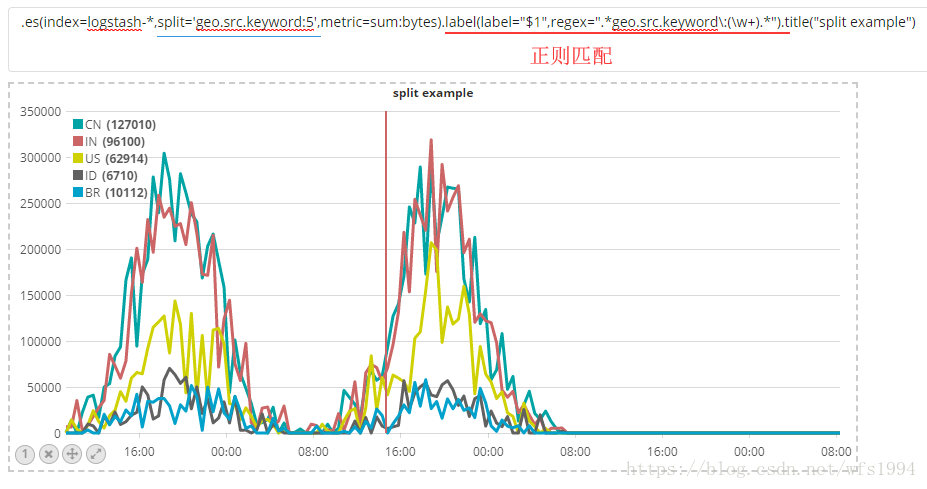
.es(index=logstash-*,split='geo.src.keyword:1',split='machine.os.keyword:2',metric=count,metric=sum:bytes).label(label="$1-$2-$3",regex=".*geo.src.keyword:([^>]+) > machine.os.keyword:([^>]+) > (.*)"),.static(50000).label("alerting line").color("red").title("multi split and metrics")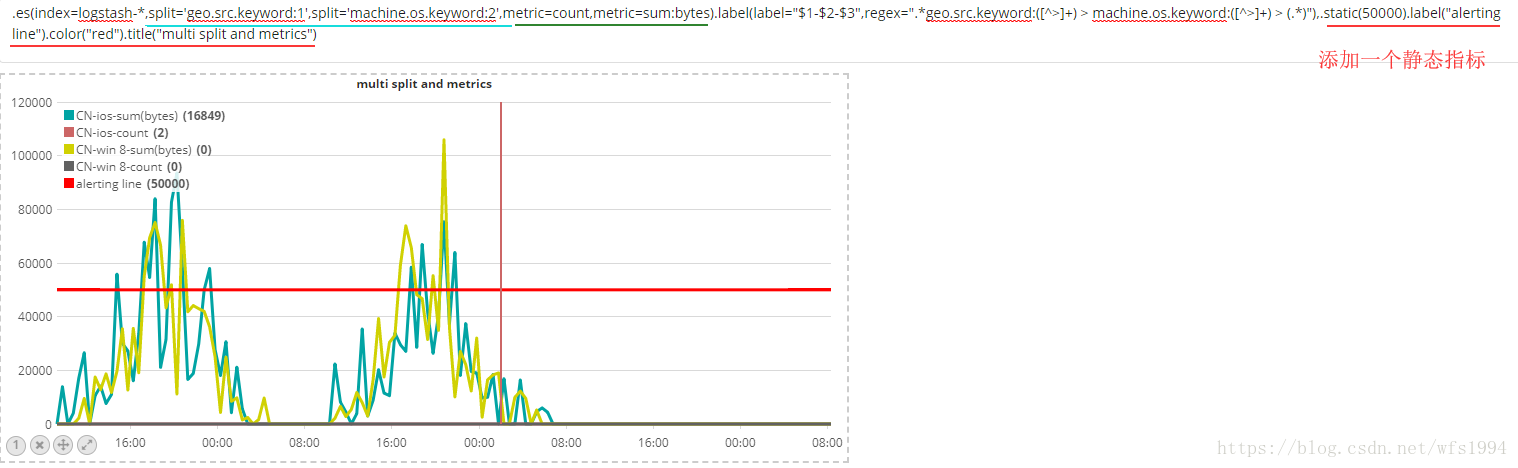
.es(index=logstash-*,metric=sum:bytes).cusum().label('total traffic'),.es(index=logstash-*,metric=sum:bytes).cusum().trend().label("trend").title('cusum and trend line')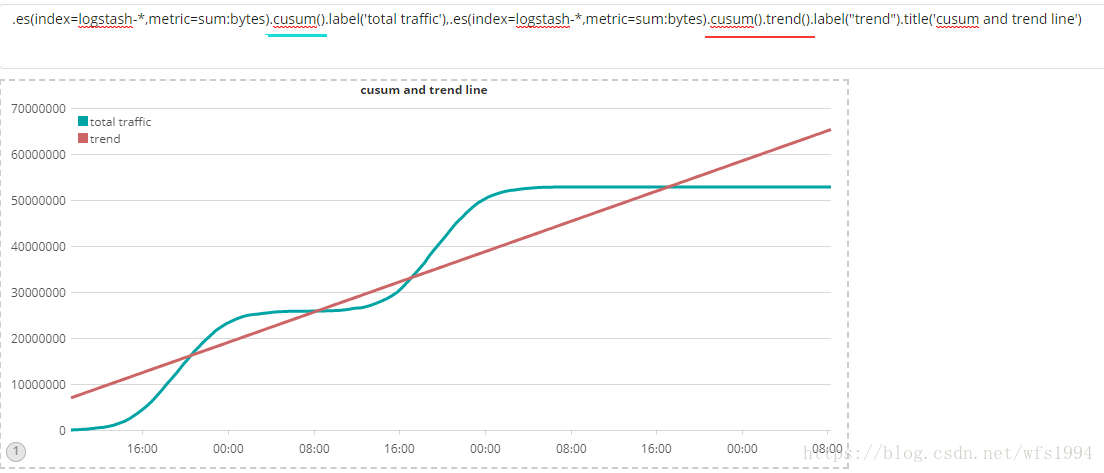
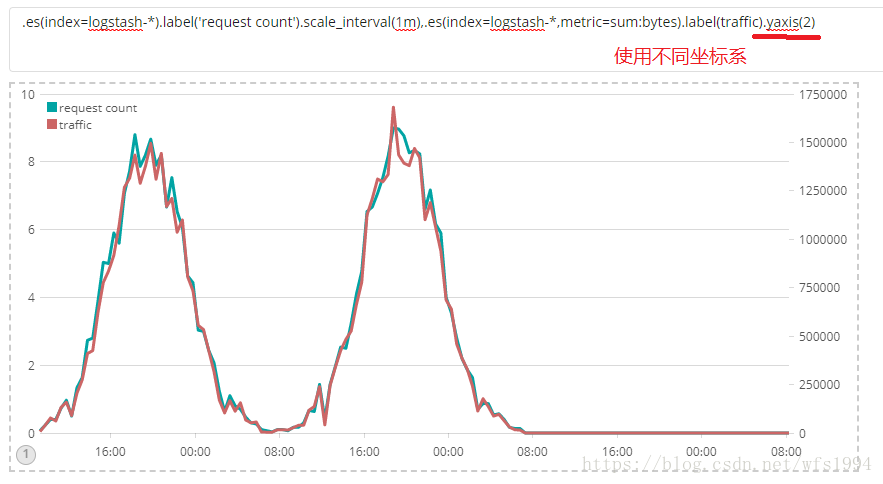
(.es(index=logstash-*).label('request count'),.es(index=logstash-*,metric=sum:bytes).label(traffic)).range(0,10000)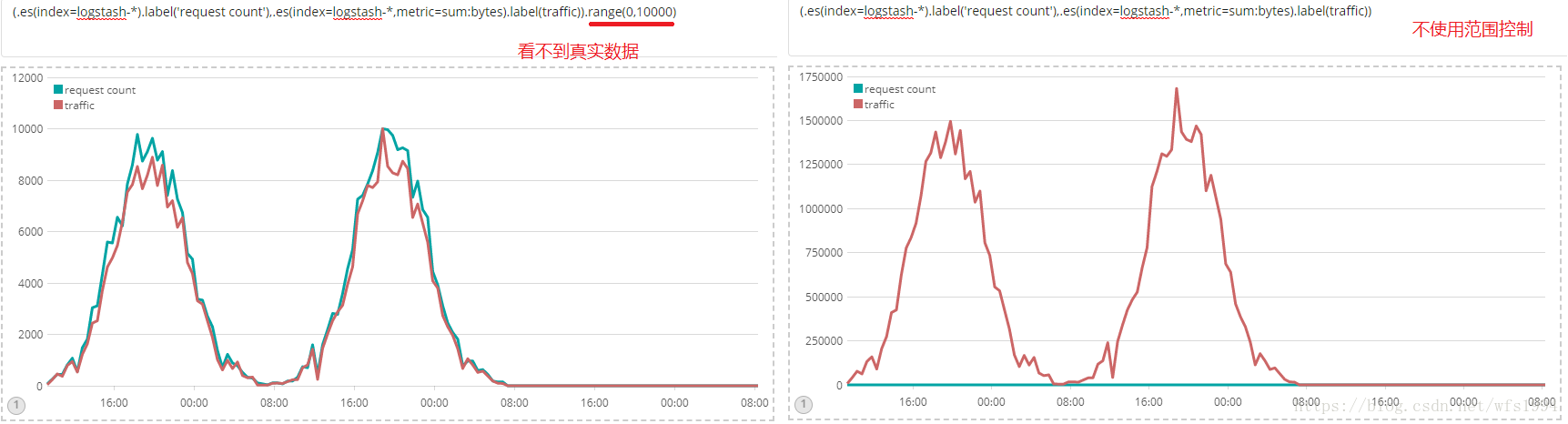
.es(index=logstash-*).label('request count').scale_interval(1m),.es(index=logstash-*,metric=sum:bytes).label(traffic).yaxis(2)