Zookeeper简介
打开Zookeeper的官网,http://zookeeper.apache.org/,可以看到这样一句话
ZooKeeper是一种集中式服务,用于维护配置信息,命名,提供分布式同步和提供组服务。所有这些类型的服务都以分布式应用程序的某种形式使用。每次实施它们都需要做很多工作来修复不可避免的错误和竞争条件。由于难以实现这些类型的服务,应用程序最初通常会吝啬它们,这使得它们在变化的情况下变得脆弱并且难以管理。即使正确完成,这些服务的不同实现也会在部署应用程序时导致管理复杂性。
注红的一句话基本上概括了Zookeeper可以提供什么功能.
1.命名服务 2.配置管理 3.集群管理 4.分布式锁 5.队列管理
Zookeeper数据结构
1.Zookeeper维护一个类似文件系统的数据结构:

图中的每个节点称为一个znode. 每个znode由3部分组成:
1.stat:此为状态信息, 描述该znode的版本, 权限等信息.
2.data:与该znode关联的数据.
3.children:该znode下的子节点.
每个子目录项如 NameService 都被称作为 znode,和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
有四种类型的znode:
1、PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
2、 PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
3、EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
4、EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
另外,需要注意是,ZooKeeper的临时节点不允许拥有子节点。
2.通知机制(watch)
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
3.znode节点操作
在ZooKeeper中有9个基本操作,如下图所示:
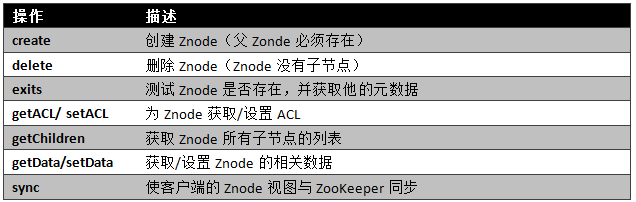
更新ZooKeeper操作是有限制的。delete或setData必须明确要更新的Znode的版本号,我们可以调用exists找到。如果版本号不匹配,更新将会失败。
更新ZooKeeper操作是非阻塞式的。因此客户端如果失去了一个更新(由于另一个进程在同时更新这个Znode),他可以在不阻塞其他进程执行的情况下,选择重新尝试或进行其他操作。
尽管ZooKeeper可以被看做是一个文件系统,但是处于便利,摒弃了一些文件系统地操作原语。因为文件非常的小并且使整体读写的,所以不需要打开、关闭或是寻地的操作。
Zookeeper可以实现的功能
从简介里面已经大致概括了Zookeeper提供的功能.
1.命名服务.
通过四种类型的znode节点了解,我们可以通过约定在同一个/path 目录下创建顺序编号的节点,通过path即能探索发现.
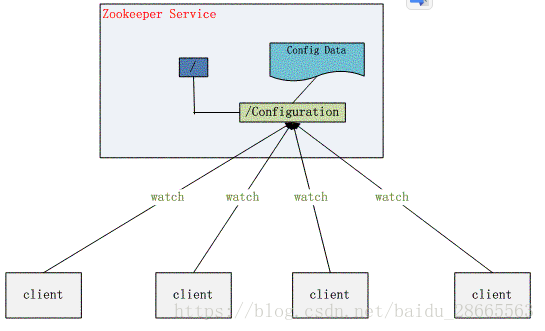
2.统一配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难.约定把所有需要配置的信息存放到某一节点下,然后所有相关应用程序对这个目录节点进行监听,通过Zookeeper的通知机制,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
3.集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。(同样也是利用Zookeeper的znode的特性判断某个znode是否存在.)
所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知.master的选举约定创建临时顺序编号目录节点,每次选取编号最小的机器作为master。
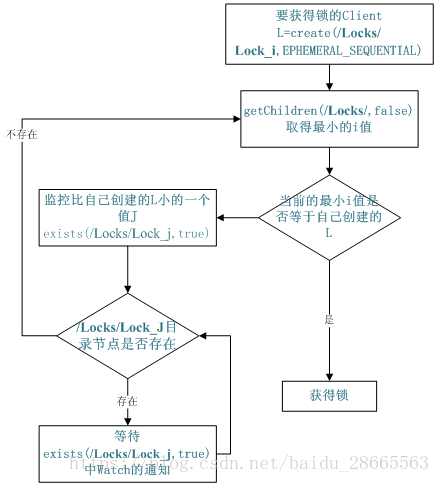
4.Zookeeper分布式锁
1: 当这两个线程去mysql更新数据之前, 先到zookeeper的/locks(永久节点)下面注册一个临时有序节点, 这样每个线程都注册了一个临时节点, 两个临时节点肯定是有序的。
线程1: /locks/000000002 线程2: /locks/000000001
2: 当每个线程注册完节点之后, 需要尝试获取锁, 这个时候, 哪个节点最小, 哪个线程就获取到锁, 这个时候, 线程2注册的节点最小, 所以线程2 就获取到锁, 执行更新数据库的代码, 更新完
成之后, 删除自己注册的临时节点。同时线程1会判断自己不是最小的, 所以就会监控比自己小1的那个节点, 当发现那个节点消失的话, 也就意味着它的节点就是最小的节点, 获取锁, 执行更新数据库的代码 .
5.Zookeeper队列管理
两种类型的队列:1、同步队列,当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达。
2、队列按照 FIFO(先进xian) 方式进行入队和出队操作。
第一类,在约定目录下创建临时目录节点,监听节点数目是否是我们要求的数目。
Zookeeper的选举机制及工作流程可以参考末尾的文章连接,在此不做赘述.
Zookeeper的安装
windows下安装比较简单,官网下载压缩包解压即可.这里介绍下linux下安装Zookeeper.
下载压缩包
[root@localhost home]# wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
解压:
解压之后进入conf目录修改配置文件
[root@localhost home]# cd zookeeper-3.4.12/conf
[root@localhost home]# cp zoo_sample.cfg zoo.cfg
修改内容:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/usr/zookeeper
dataLogDir=/usr/zookeeper/log
# the port at which the clients will connect
clientPort=2181 其中主要修改的是端口号和serverid.
然后就是启动客户端:
[root@localhost home]# cd /home/zookeeper-3.4.12/bin
[root@localhost home]# ./zkServer.sh start
参考文献:
更详细的介绍及应用建议参考:
https://blog.csdn.net/tswisdom/article/details/41522069
https://www.cnblogs.com/zlslch/p/7242381.html?utm_source=itdadao&utm_medium=referral