I. Solr
Solr简介
Solr是Apache的顶级开源项目,使用java开发 ,基于Lucene的全文检索服务器。 Solr比Lucene提供了更多的查询语句,而且它可扩展、可配置,同时它对Lucene的性能进行了优化。
Solr的全文检索流程
- 索引流程: Solr客户端(浏览器、java程序)可以向Solr服务端发送POST请求,请求内容是包含Field等信息的一个xml文档,通过该文档,Solr实现对索引的维护(增删改)。
- 搜索流程: Solr客户端(浏览器、java程序)可以向Solr服务端发送GET请求,Solr服务器返回一个xml文档。
Solr同样没有视图渲染的功能。
与Lucence区别
Lucene是一个全文检索引擎工具包,它只是一个jar包,不能独立运行,对外提供服务。
Solr是一个全文检索服务器,它可以单独运行在servlet容器,可以单独对外提供搜索和索引功能。Solr比Lucene在开发全文检索功能时,更快捷、更方便。
II. Solr安装配置
环境依赖
- Solr7.4.0:http://archive.apache.org/dist/lucene/solr/
- Lucence7.4.0:http://archive.apache.org/dist/lucene/java/
- MySQL5
- Tomcat8.5
Solr目录结构
这里选择的是Windows平台的软件包,Solr7.4.0解压目录如下:
Solr的启动和关闭
启动:cmd进入bin目录后
solr start启动完成即可访问:http://localhost:8983/solr/
solr stop -p 8983创建Solr Core
两种方法:
通过dos命令创建,进入bin目录,输入:solr create -c corename
使用该命令会在/server/solr下就会出现新的文件夹corename(就是新创建的core)。
直接在/server/solr下创建新文件夹,自定义文件夹名称作为新的core。将/server/solr/configsets/_default目录下的conf文件夹,然后拷贝一份至自定义文件夹目录。
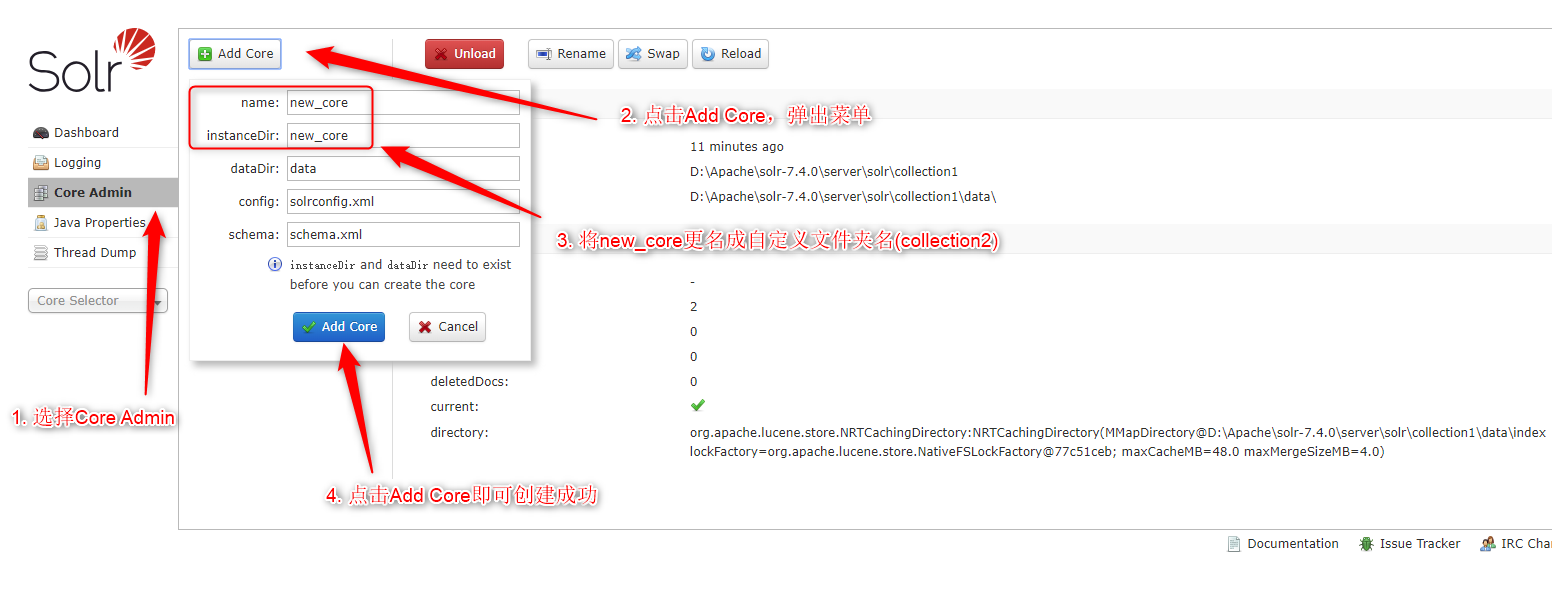
打开Solr面板,按照图中指示操作则可以添加新创建的collection2的Solr Core。
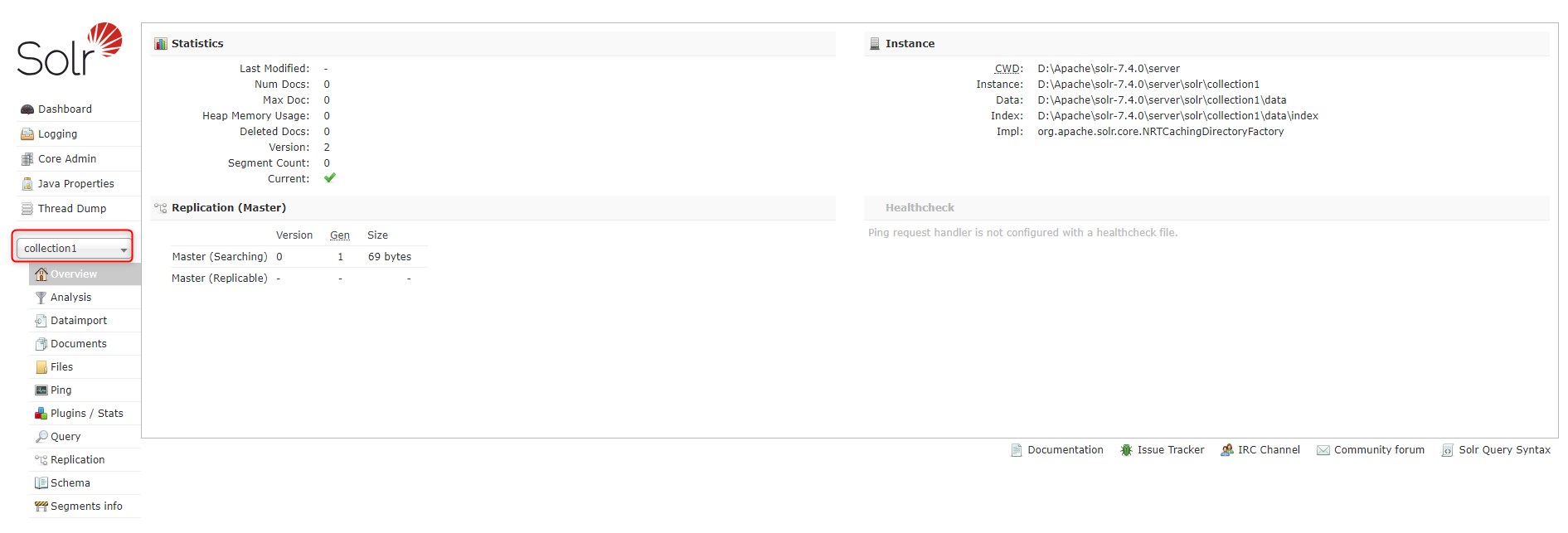
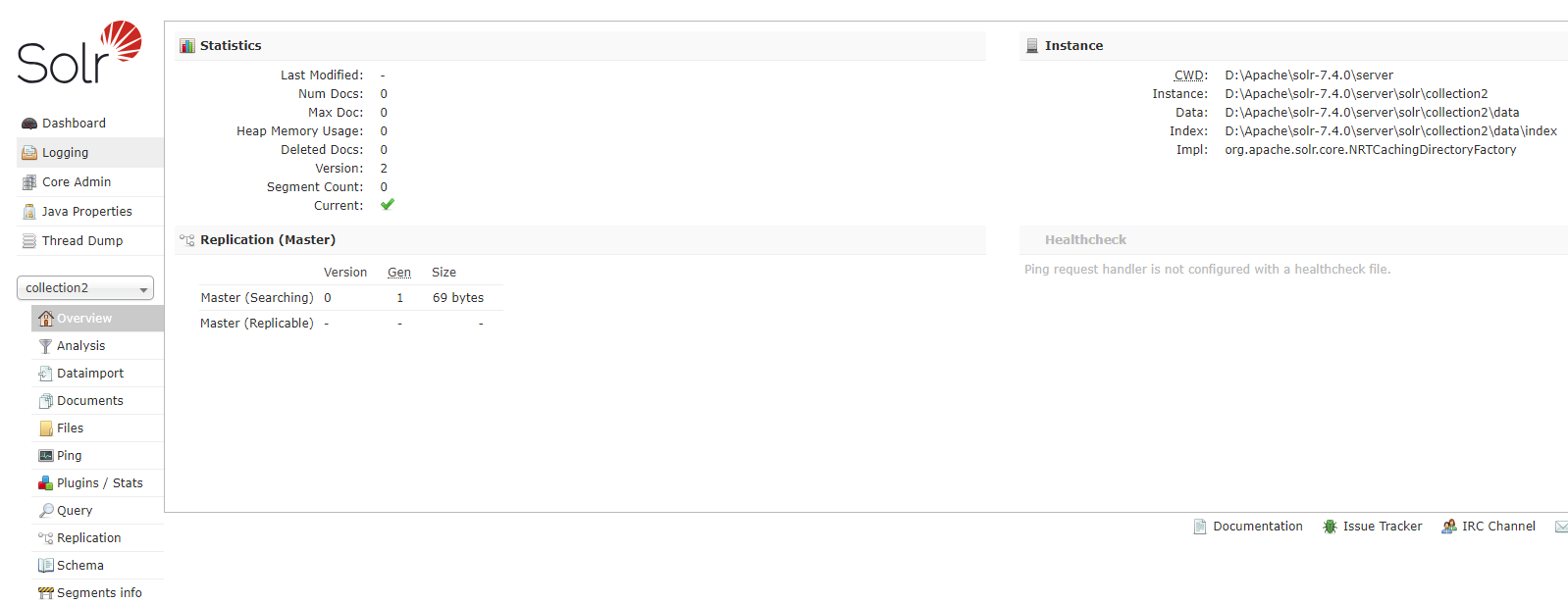
III. Solr面板
基础面板
Dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
Logging
Solr运行日志信息。
Cloud
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单。
Core Admin
Solr Core的管理界面,在这里可以添加SolrCore实例。
Java Properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
Core Selector
选择一个SolrCore进行详细操作。
Core Selector
Analysis
通过Analysis界面可以测试索引分析器和搜索分析器的执行情况。在Solr中,分析器是绑定在域的类型中的。
Dataimport
可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。默认没有配置,需要手工配置。
Documents
通过/update表示更新索引,Solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
通过此菜单可以创建索引、更新索引、删除索引等操作。
Query
通过/select执行搜索索引,必须指定“q”查询条件方可搜索。


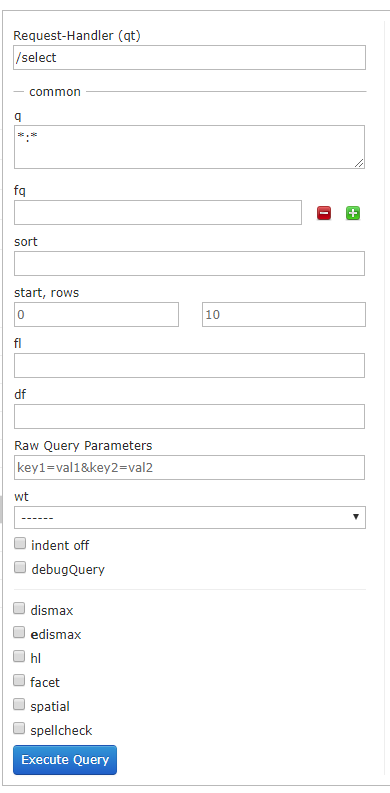
IV. Solr的基本使用
在新建的slor core的conf文件夹里,存在重要的配置文件。
V. managed-schema
field
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />Field节点指定建立索引和查询数据的字段。
- name:指定域的名称
- type:指定域的类型
- indexed:是否索引
- stored:是否存储
- required:是否必须
- multiValued:是否多值,比如商品信息中,一个商品有多张图片,一个Field想存储多个值的话,必须将multiValued设置为true
dynamicField
<dynamicField name="*_i" type="pint" indexed="true" stored="true"/>dynamicField 表示动态字段,可以动态定义一个字段,只要符合规则的字段都可以。
name:指定动态域的命名规则,*_i只要以_i结尾的字段都满足这个定义。
type:指定域的类型
- indexed:是否索引
- stored:是否存储
uniqueKey
<uniqueKey>id</uniqueKey>指定唯一键。其中的id是在Field标签中已经定义好的域名,而且该域要设置为required为true。 一个managed-schema文件中必须有且仅有一个唯一键。
copyField
<copyField source="cat" dest="_text_"/>通过copyField,可以把一个字段的值复制到另一个字段中,也可以把多个字段的值同时复制到另一个字段中,这样搜索的时候都可以根据一个字段来进行搜索。
- source:要复制的源Field域的域名
- dest:目标Field域的域名
- 由dest指的的目标Field域,必须设置multiValued为true。
fieldType
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
fieldType节点主要用来定义域的类型。
- name:指定域类型的名称
- class:指定该域类型对应的solr的类型
- analyzer:指定分析器
- type:index、query,分别指定搜索和索引时的分析器
- tokenizer:指定分词器
- filter:指定过滤器
- positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误
VI. solrconfig.xml
datadir
<dataDir>${solr.data.dir:}</dataDir>每个SolrCore都有自己的索引文件目录 ,默认在SolrCore目录下的data中。
luceneMatchVersion
<luceneMatchVersion>7.4.0</luceneMatchVersion>表示solr底层使用的是Lucene7.4.0版本
lib
<lib dir="${solr.install.dir:../../../..}/contrib/extraction/lib" regex=".*\.jar" />表示Solr引用包的位置,当dir对应的目录不存在时候,会忽略此属性。
solr.install.dir:表示solrcore的安装目录。
requestHandler
<requestHandler name="/query" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicit</str>
<str name="wt">json</str>
<str name="indent">true</str>
</lst>
</requestHandler>requestHandler请求处理器,定义了索引和搜索的访问方式。 通过/update维护索引,可以完成索引的添加、修改、删除操作;通过/select搜索索引。
设置搜索参数完成搜索,搜索参数也可以设置一些默认值,如下:
<requestHandler name="/select" class="solr.SearchHandler">
<!-- 设置默认的参数值,可以在请求地址中修改这些参数-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int><!--显示数量-->
<str name="wt">json</str><!--显示格式-->
<str name="df">text</str><!--默认搜索字段-->
</lst>
</requestHandler>directoryFactory
<directoryFactory name="DirectoryFactory"
class="${solr.directoryFactory:solr.NRTCachingDirectoryFactory}"/>定义索引的存储方案,共有以下存储方案:
- solr.StandardDirectoryFactory——这是一个基于文件系统存储目录的工厂,它会试图选择最好的实现基于你当前的操作系统和Java虚拟机版本。
- solr.SimpleFSDirectoryFactory——适用于小型应用程序,不支持大数据和多线程。
- solr.NIOFSDirectoryFactory——适用于多线程环境,但是不适用在windows平台(很慢),是因为JVM还存在bug。
- solr.MMapDirectoryFactory——这个是solr3.1到4.0版本在linux64位系统下默认的实现。它是通过使用虚拟内存和内核特性调用mmap去访问存储在磁盘中的索引文件。它允许lucene或solr直接访问I/O缓存。如果不需要近实时搜索功能,使用此工厂是个不错的方案。
- solr.NRTCachingDirectoryFactory——此工厂设计目的是存储部分索引在内存中,从而加快了近实时搜索的速度。
- solr.RAMDirectoryFactory——这是一个内存存储方案,不能持久化存储,在系统重启或服务器crash时数据会丢失。且不支持索引复制。
VII. Solr发布至Tomcat
从Solr5.0.0版本开始,Solr不提供可供直接发布的war包,需要我们自己重新整合。
在将Solr发布至Tomcat之前,我们需要了解solrhome和solrcore的概念。
- solrhome:solrhome是solr服务运行的主目录,一个solrhome目录里面包含多个solrcore目录 ;
- solrcore:solrcore目录里面了一个solr实例运行时所需要的配置文件和数据文件,每一个solrcore都可以单独对外提供搜索和索引服务,多个solrcore之间没有关系;
拷贝工程文件夹
将 solr-7.1.0\server\solr-webapp 下的webapp复制到 tomcat\webapps,并改名为solr;
定义我们的solr_home,这里定义在D:\Apache\apache-tomcat-8.5.11\solr_home位置;
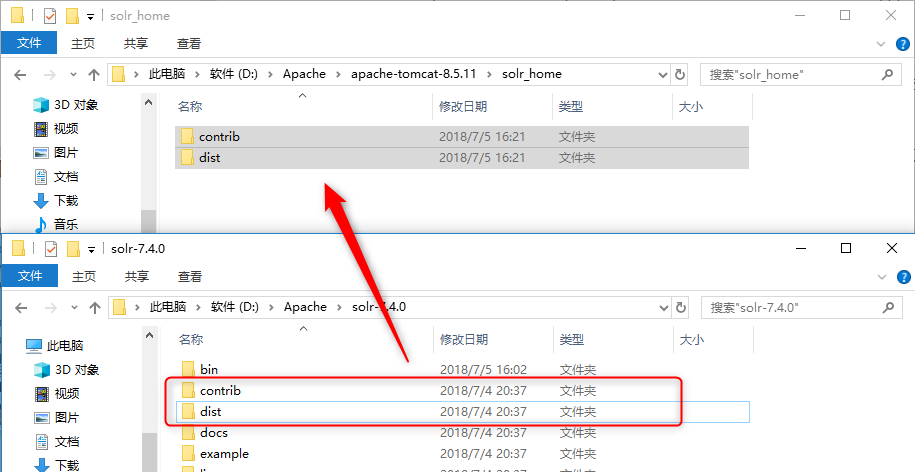
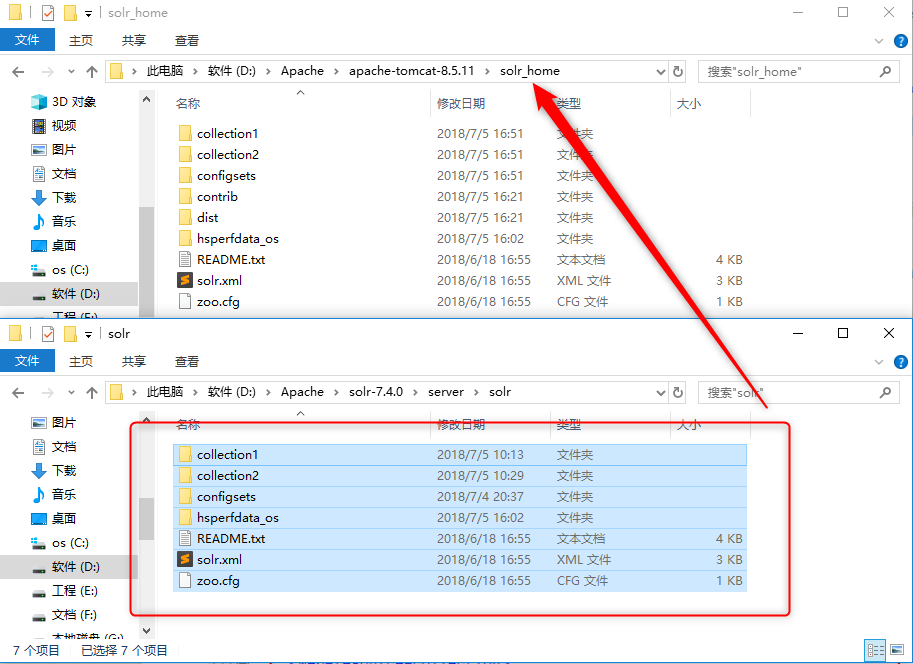
将 solr-7.1.0 下的contrib和dist文件夹复制到指定的solrhome目录下;
将 solr-7.1.0\server\solr下的文件复制到solrhome目录下。
复制相关的jar包
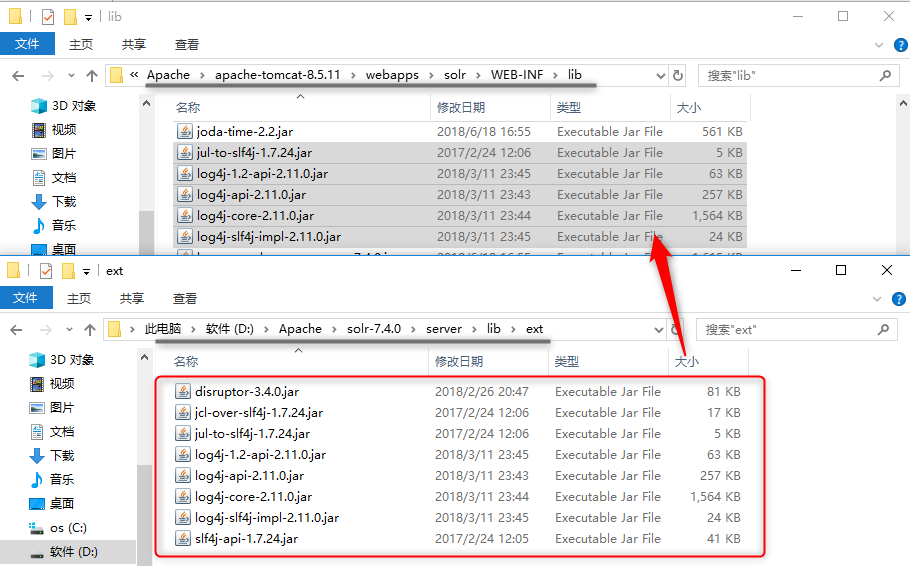
将\server\lib\ext中所有的.jar文件复制到tomcat\webapps\solr\WEB-INF\lib中;
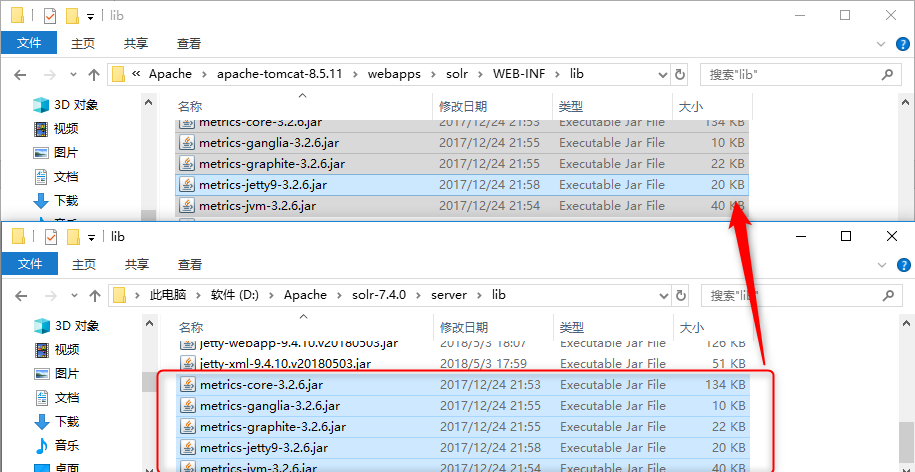
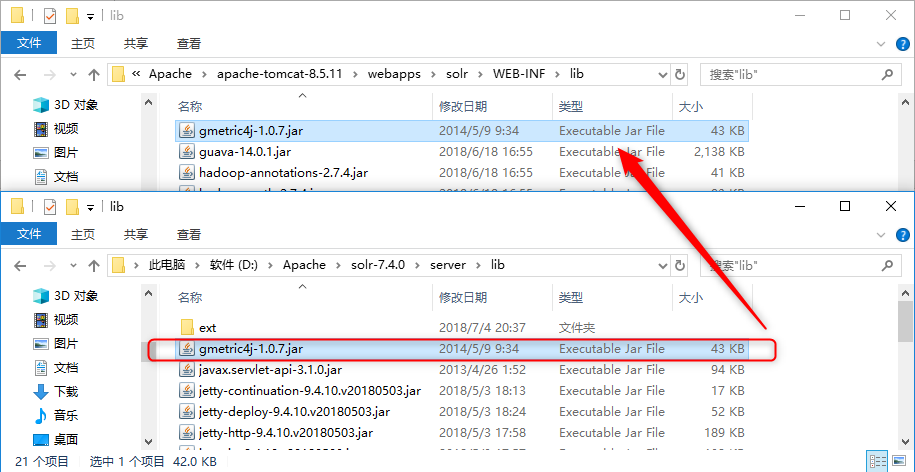
将\server\lib下的metrics-*.jar复制到tomcat\webapps\solr-7.1.0\WEB-INF\lib中;
将\server\lib下的gmetric4j-1.0.7.jar复制到tomcat\webapps\solr-7.1.0\WEB-INF\lib中;
修改web.xml文件
配置solrhome;
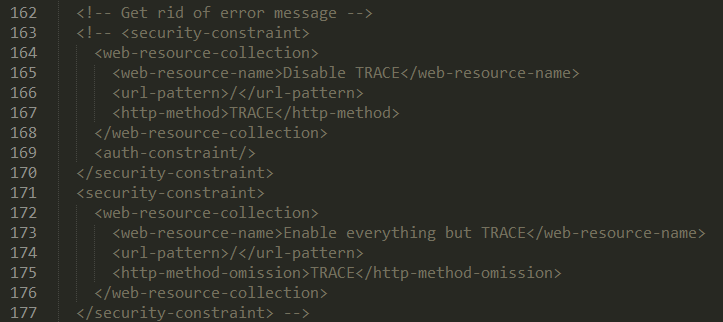
修改授权信息:找到标签,位置在文件最后,将的内容注释掉,大概意思就是开放solr权限。

日志配置
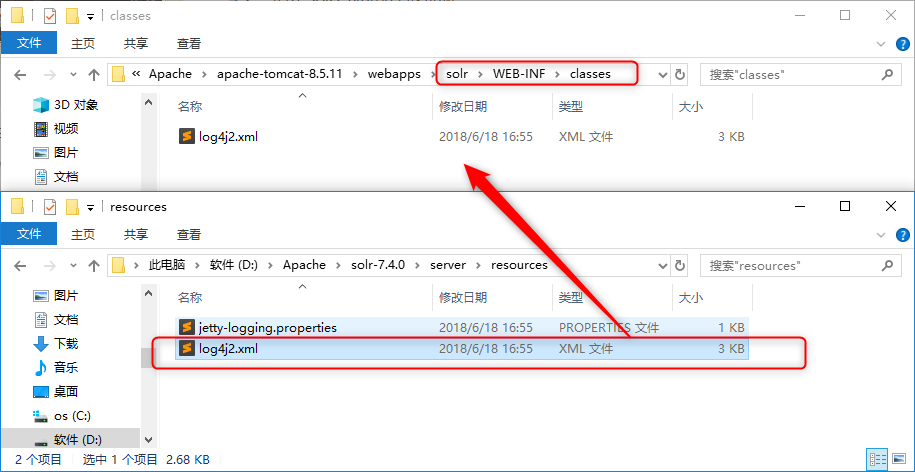
在tomcat\webapps\solr\WEB-INF目录下新建目录classes ,并将\server\resources下的log4j2.xml复制到新建的classes文件夹中;
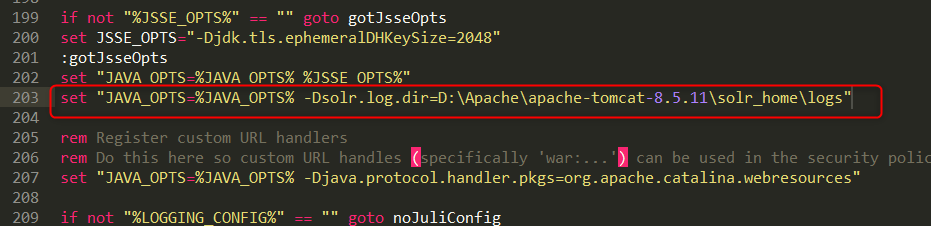
修改tomcat的bin目录下catalina.bat脚本,增加solr.log.dir系统变量,指定solr日志记录存放地址。
启动测试
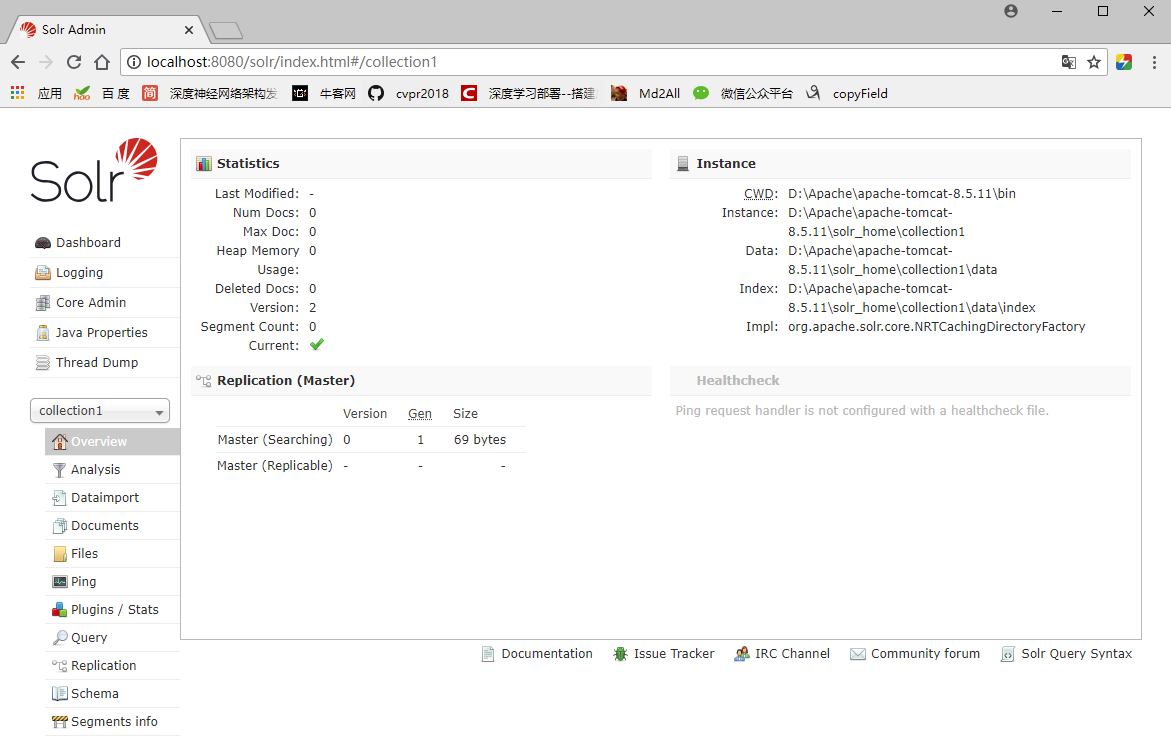
启动Tomcat,访问http://localhost:8080/solr/index.html
VIII. 连接MySQL
利用slor core的Dataimport面板可以将数据库中指定的sql语句的结果导入到solr索引库中。
选定Core
可以重新定义一个新的Core,也可以选择现有的core(这里选择collection1,并改名为tb_item)
在solrcore的conf目录下,有一个solrconfig.xml的配置文件,该配置文件用于配置solrcore的运行信息;
修改lib标签设置的路径;
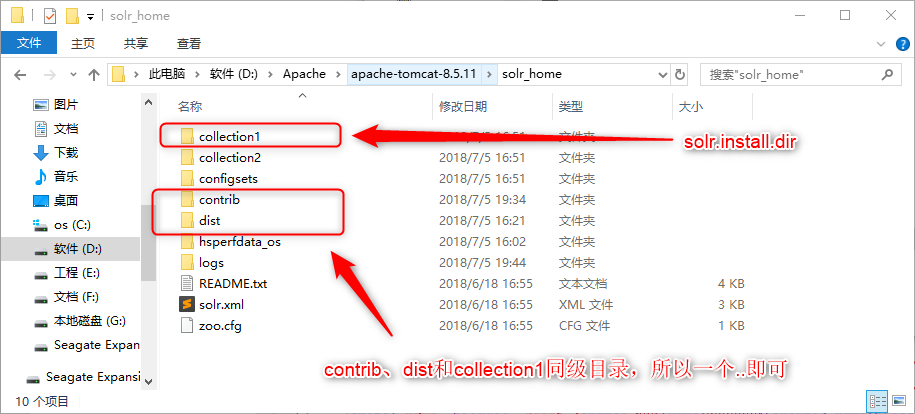
导入依赖包
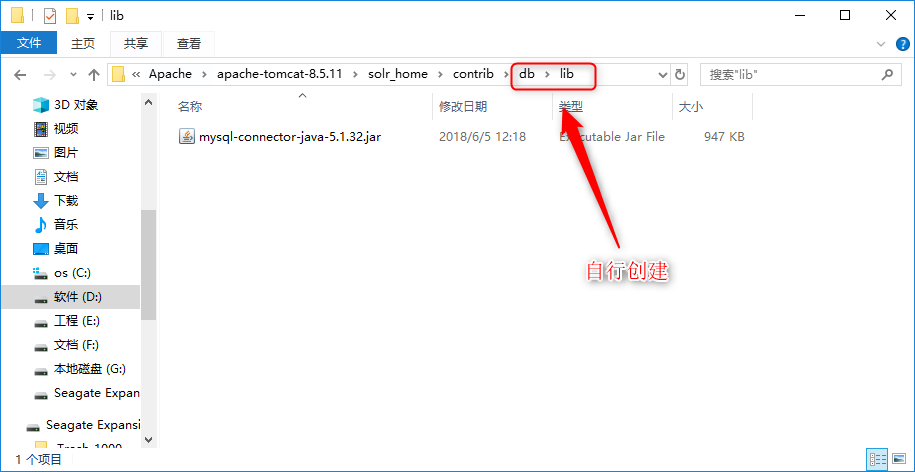
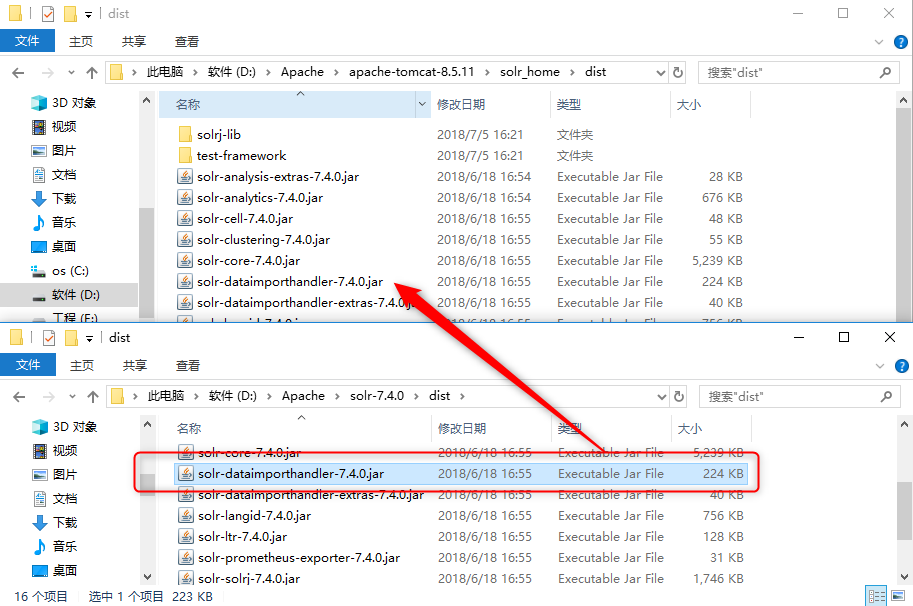
将mysql-connector-java-x.x.x.jar拷贝到…\solr_home\contrib\db下;
查看…\solr_home\dist下有没有 solr-dataimporthandler-7.4.0.jar,如果没有则去下载的代码拷贝一份;
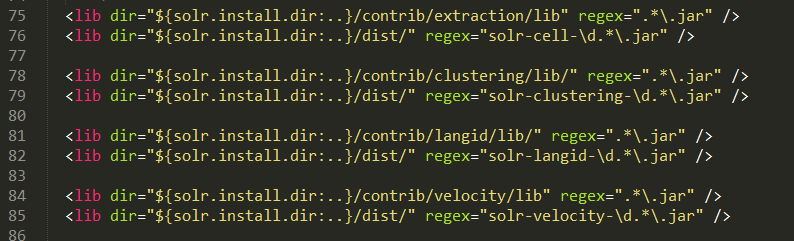
在solrconfig.xml中配置jar包的lib标签;
<!-- 配置dataimport和mysql --> <lib dir="${solr.install.dir:..}/contrib/db/lib" regex=".*\.jar" /> <lib dir="${solr.install.dir:..}/dist/" regex="solr-dataimporthandler-7.4.0.jar" />

配置连接信息
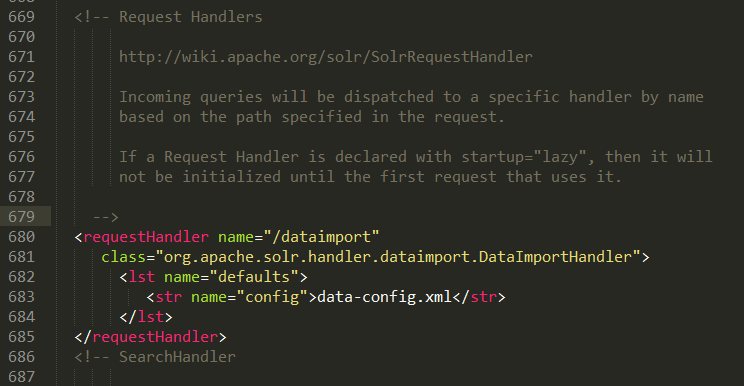
找到选定的Core(tb_item)下的solrconfig.xml文件,在solrconfig.xml中,添加一个dataimport的requestHandler;
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
在solrconfig.xml同一位置下创建data-config.xml 文件;
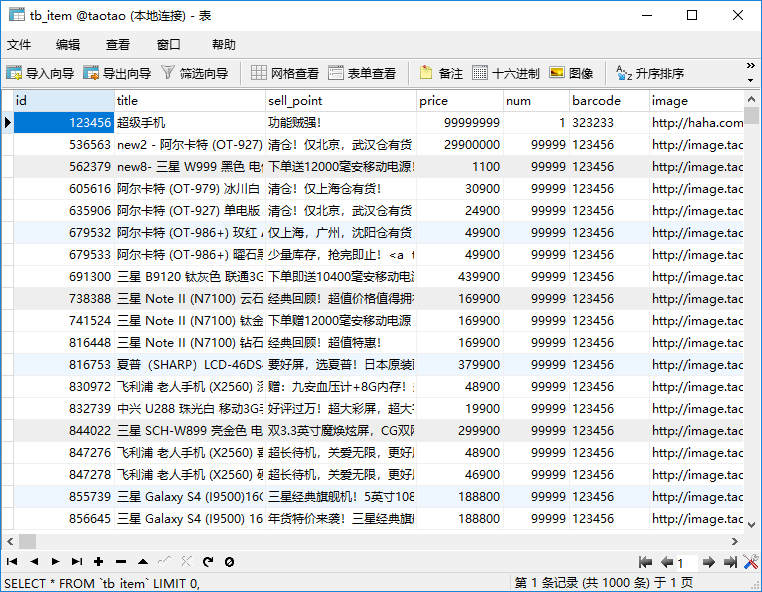
<?xml version="1.0" encoding="UTF-8" ?> <dataConfig> <dataSource type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/taotao" user="root" password="1234" /> <document> <entity name="tb_item" query="select * from tb_item"> <field column="id" name="id" /> <field column="title" name="title" /> <field column="sell_point" name="sellPoint" /> <field column="barcode" name="barcode" /> <field column="image" name="image" /> <field column="price" name="price" /> <field column="cid" name="cid" /> <field column="num" name="num" /> <field column="status" name="status" /> <field column="created" name="created" /> <field column="updated" name="updated" /> </entity> </document> </dataConfig>对应的数据库商品表为:
配置Field域
tb_item的表结构:
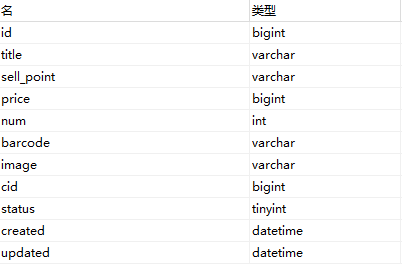
在选定的Core(tb_item)的conf下,打开managed-schema文件,在其中定义Field域。Field域的name属性需要和data-config.xml 的一致。
<!-- 配置商品表的Field -->
<!-- 商品id -->
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<!-- 商品名称 -->
<field name="title" type="string" indexed="true" stored="true" />
<!-- 商品卖点 -->
<field name="sellPoint" type="string" indexed="true" stored="true" />
<!-- 商品条形码 -->
<field name="barcode" type="string" indexed="true" stored="true" />
<!-- 图片地址 -->
<field name="image" type="string" indexed="false" stored="true" />
<!-- 价格 -->
<field name="price" type="string" indexed="false" stored="true" />
<!-- 类别id -->
<field name="cid" type="string" indexed="false" stored="true" />
<!-- 数量 -->
<field name="num" type="string" indexed="false" stored="true" />
<!-- 状态 -->
<field name="status" type="string" indexed="false" stored="true" />
<!-- 创建时间 -->
<field name="created" type="string" indexed="false" stored="true" />
<!-- 更新时间 -->
<field name="updated" type="string" indexed="false" stored="true" />
<!-- 目标域 -->
<field name="tb_item_keywords" type="string" indexed="true" stored="true" multiValued="true" />
<!-- 将商品名称和卖点加入目标域 -->
<copyField source="title" dest="tb_item_keywords" />
<copyField source="sellPoint" dest="tb_item_keywords" />启动测试
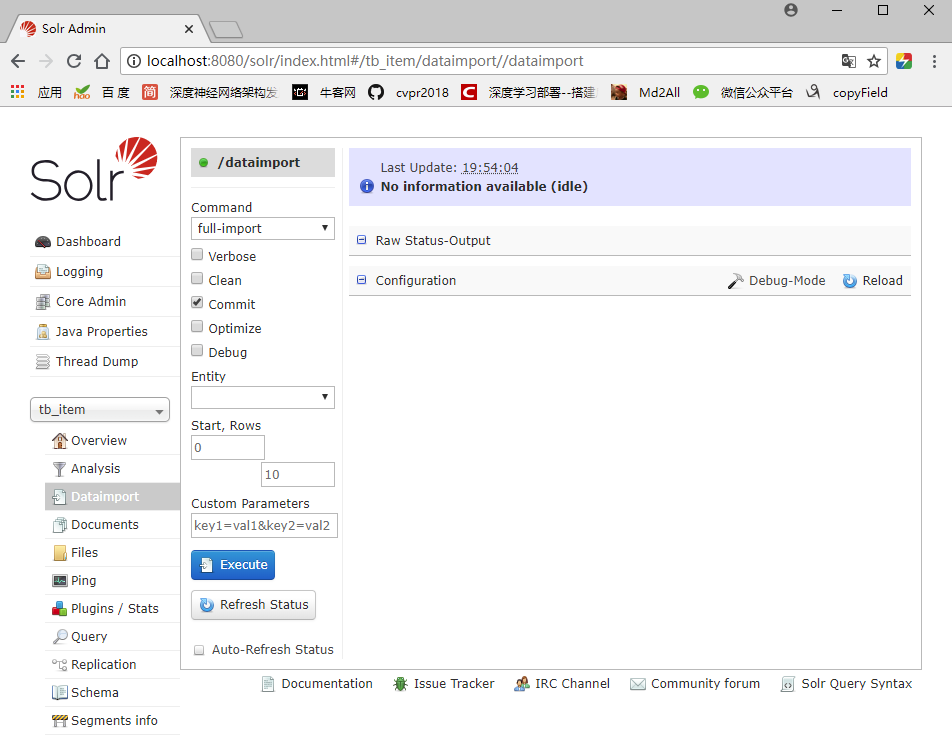
重启Tomcat,打开Solr的Dataimport面板;
选择entity,点击Execute执行。
IX. 中文分词
找到Solr7自带的中文分词器,solr_home\contrib\analysis-extras\lucene-libs下的lucene-analyzers-smartcn-7.4.0.jar。
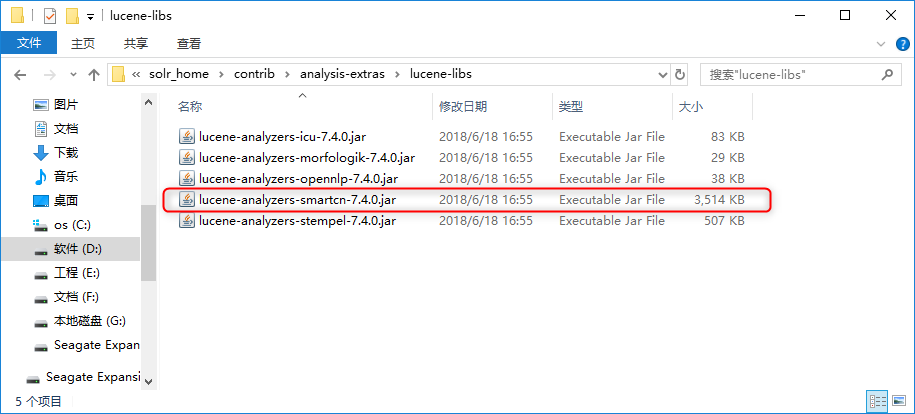
配置solrconfig.xml中配置jar包的lib标签:

在managed-shchema添加中文分词的FieldType:
<!-- 中文分词 -->
<fieldType name="cn_text" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>修改商品名称、卖点以及目标域的Type为新定义的cn_text:
<!-- 商品名称 -->
<field name="title" type="cn_text" indexed="true" stored="true" />
<!-- 商品卖点 -->
<field name="sellPoint" type="cn_text" indexed="true" stored="true" />
<!-- 目标域 -->
<field name="tb_item_keywords" type="cn_text" indexed="true" stored="true" multiValued="true" />删除之前导入的索引:
<delete><query>*:*</query></delete><commit/> 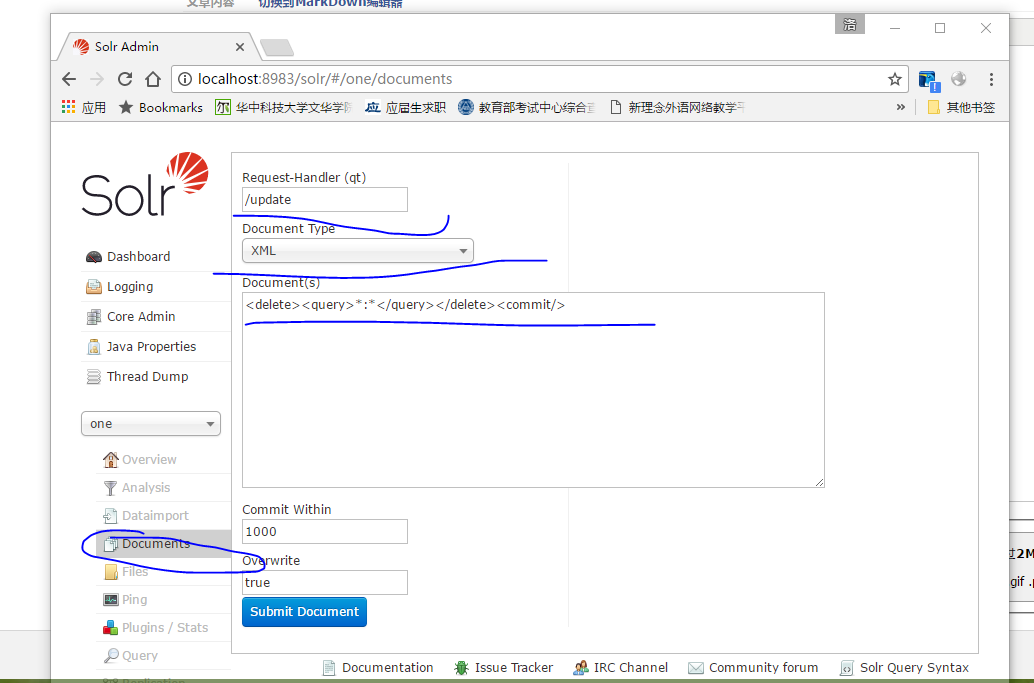
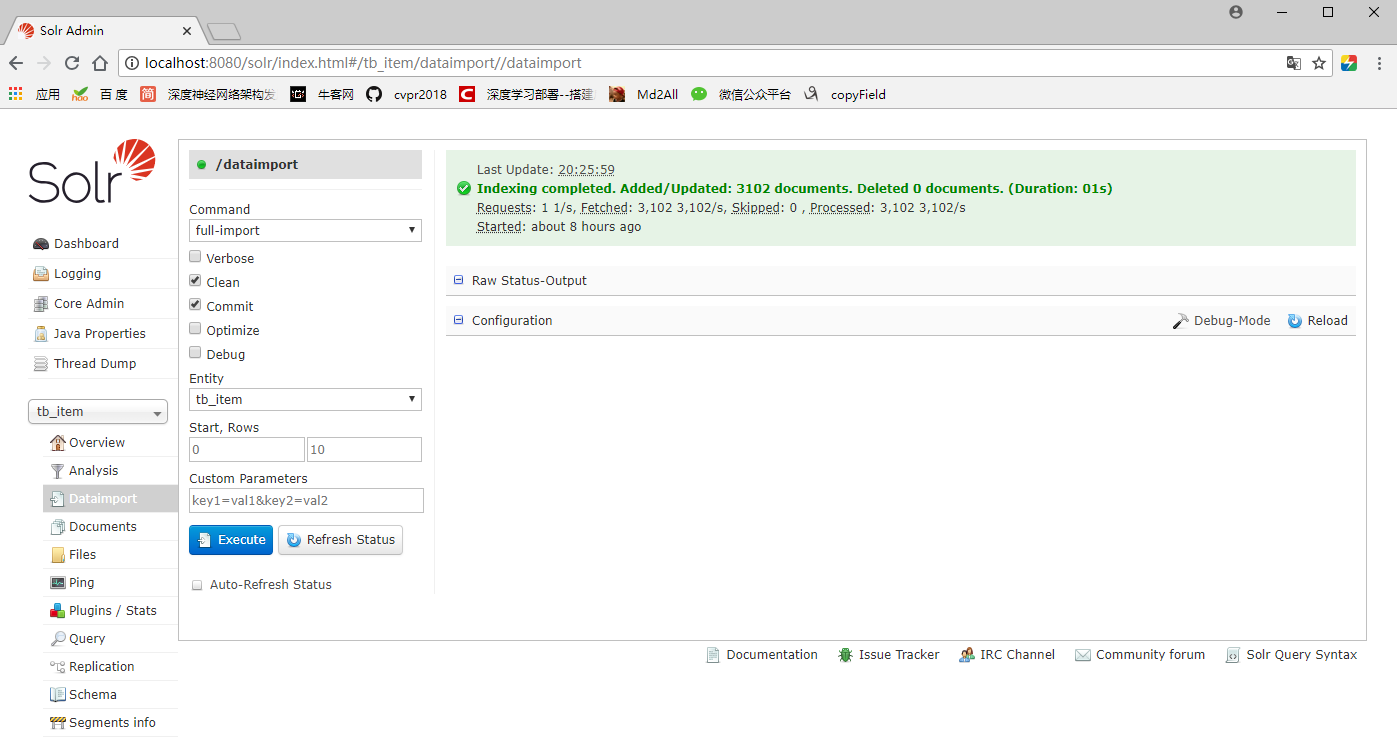
重启solr服务,导入数据。利用Query面板,查询sellPoint:卖点,得到155条结果表明分词成功。
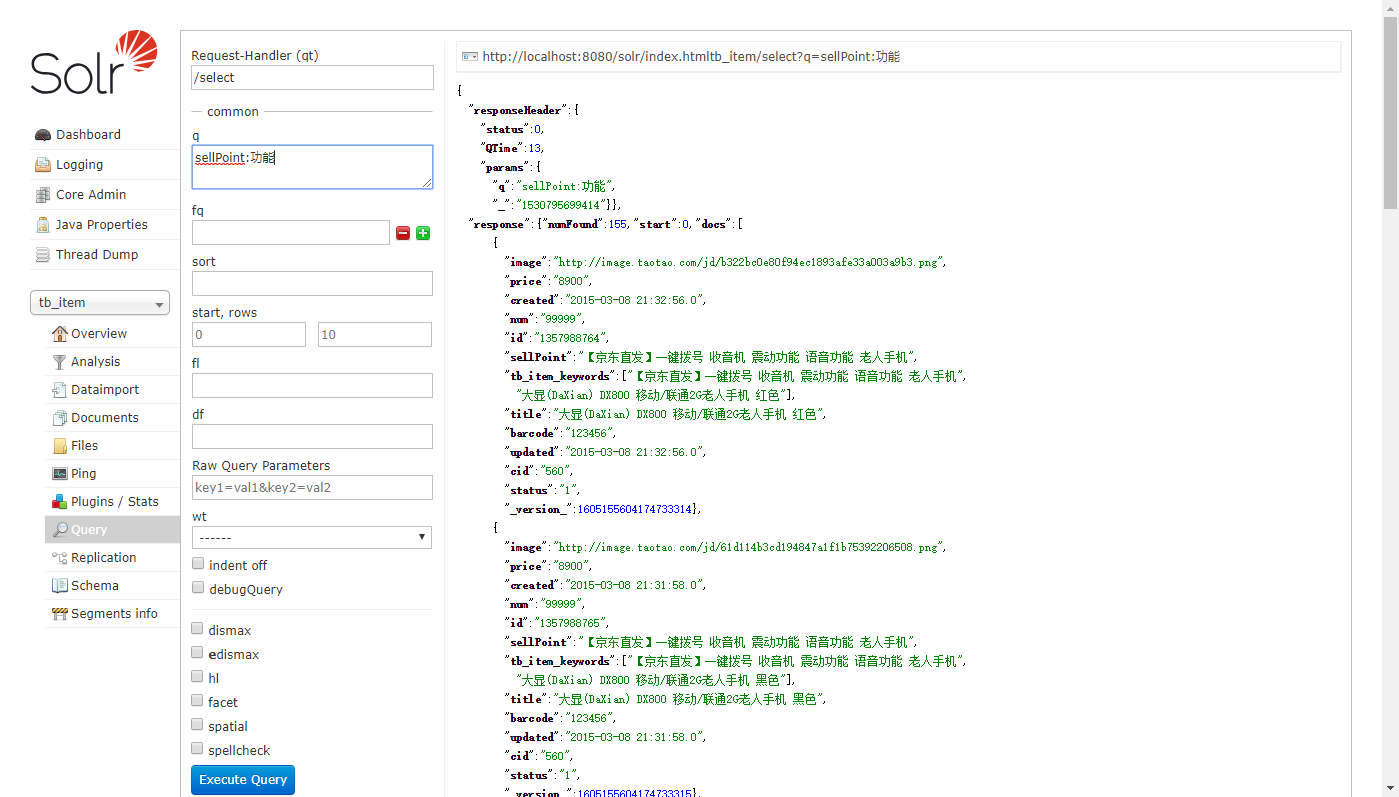
X. SolrJ客户端
SolrJ简介
Solrj就是Solr服务器的java客户端,提供索引和搜索的请求方法。SolrJ通常嵌入在业务系统中,通过solrJ的API接口操作Solr服务。
搭建工程
拷贝Jar包,共有三处:
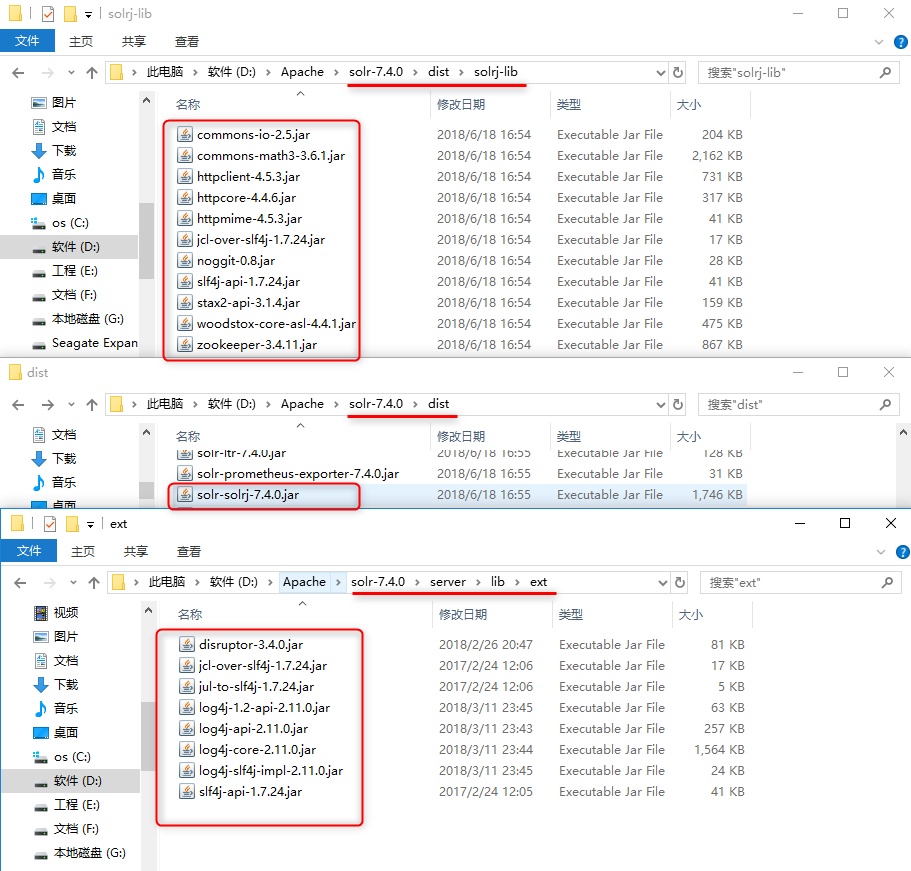
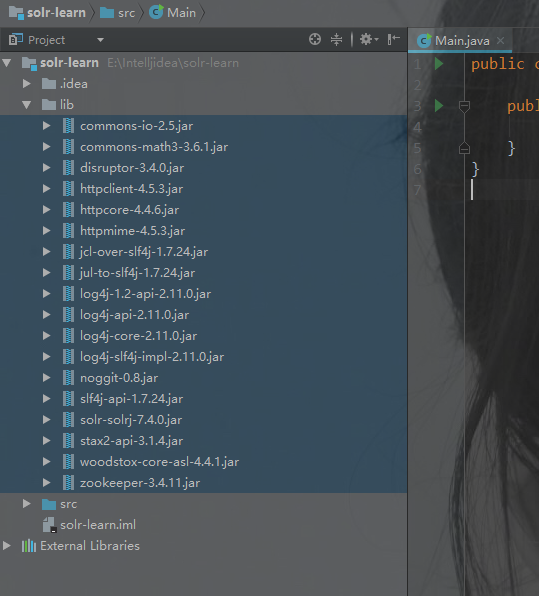
添加/修改索引
在solr中,索引库中都会存在一个唯一键。如果一个Document的id存在,则执行修改操作,如果不存在,则执行添加操作。
@Test
public void insertOrUpdateIndex() throws IOException, SolrServerException {
// solr服务的url,tb_item是前面创建的solr core
String url = "http://localhost:8080/solr/tb_item";
// 创建HttpSolrClient
HttpSolrClient client = new HttpSolrClient.Builder(url)
.withConnectionTimeout(5000)
.withSocketTimeout(5000)
.build();
// 创建Document对象
SolrInputDocument document = new SolrInputDocument();
document.addField("id", "1111");
document.addField("title", "Solr入门");
document.addField("sellPoint", "Solr版本差异也太大了");
client.add(document);
client.commit();
}查询插入结果:
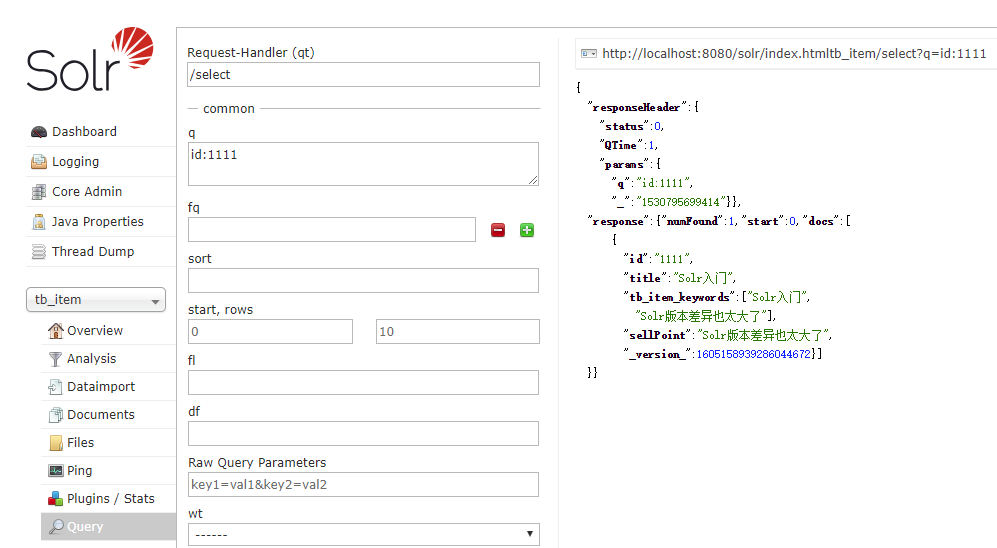
修改titile为Solr进阶,再次运行代码,查询结果:
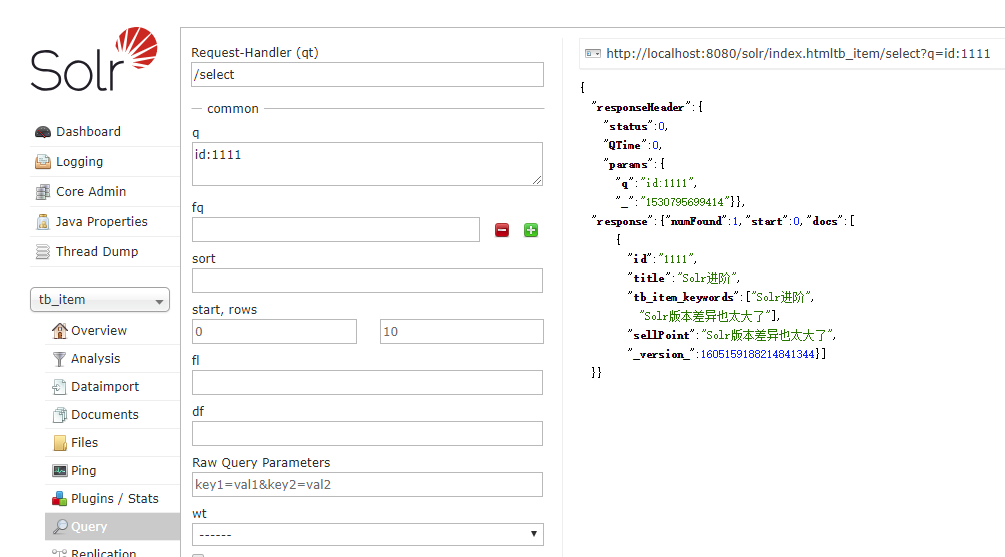
删除索引
根据指定ID来删除
@Test public void deleteIndex() throws IOException, SolrServerException { String url = "http://localhost:8080/solr/tb_item"; HttpSolrClient client = new HttpSolrClient.Builder(url) .withConnectionTimeout(5000) .withSocketTimeout(5000) .build(); client.deleteById("1111"); client.commit(); }根据条件删除
// 根据条件删除 client.deleteByQuery("id:1111"); // 全部删除 client.deleteByQuery("*:*");
简单查询
@Test
public void simpleSearch() throws IOException, SolrServerException {
String url = "http://localhost:8080/solr/tb_item";
HttpSolrClient client = new HttpSolrClient.Builder(url)
.withConnectionTimeout(5000)
.withSocketTimeout(5000)
.build();
// 创建SolrQuery
SolrQuery query = new SolrQuery();
// 输入查询条件
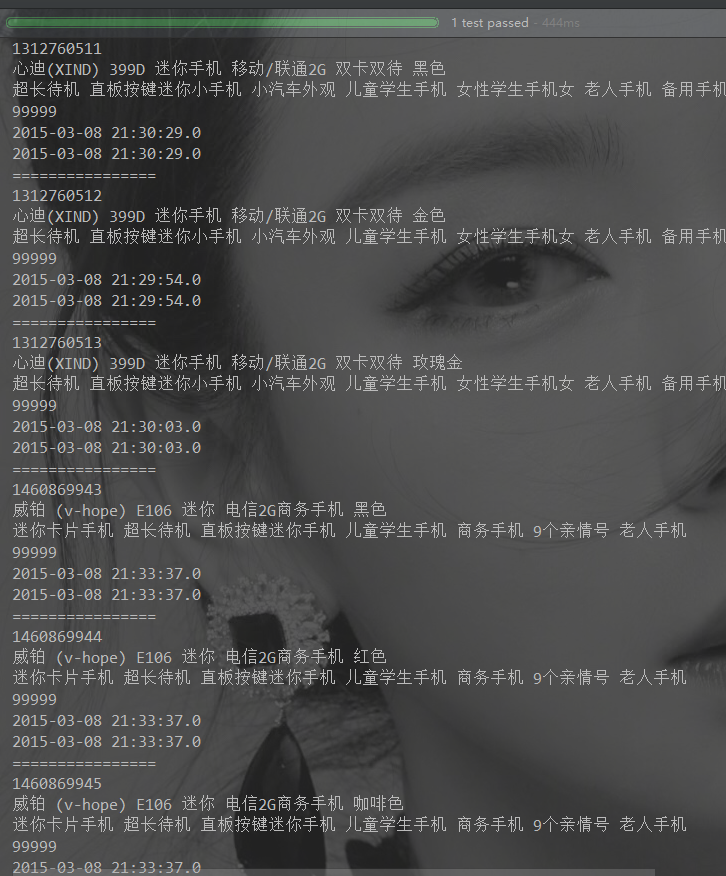
query.setQuery("sellPoint:手机");
// 执行查询并返回结果
QueryResponse response = client.query(query);
// 获取匹配的所有结果
SolrDocumentList list = response.getResults();
// 匹配结果总数
long count = list.getNumFound();
System.out.println("总结果数:" + count);
for (SolrDocument document : list) {
System.out.println(document.get("id"));
System.out.println(document.get("title"));
System.out.println(document.get("sellPoint"));
System.out.println(document.get("num"));
System.out.println(document.get("created"));
System.out.println(document.get("updated"));
System.out.println("================");
}
}
条件查询
- q - 查询关键字,必须的,如果查询所有使用*:*。请求的q是字符串;
- fq - (filter query)过虑查询,在q查询符合结果中同时是fq查询符合的。例如:请求fq是一个数组(多个值);
- sort - 排序;
- start - 分页显示使用,开始记录下标,从0开始;
- rows - 指定返回结果最多有多少条记录,配合start来实现分页;
- fl - 指定返回那些字段内容,用逗号或空格分隔多个 ;
- df-指定一个搜索Field;
- wt - (writer type)指定输出格式,可以有 xml, json, php, phps;
- hl 是否高亮,设置高亮Field,设置格式前缀和后缀。
SolrJ实现复杂条件查询:
@Test
public void complexSearch() throws IOException, SolrServerException {
String url = "http://localhost:8080/solr/tb_item";
HttpSolrClient client = new HttpSolrClient.Builder(url)
.withConnectionTimeout(5000)
.withSocketTimeout(5000)
.build();
SolrQuery query = new SolrQuery();
// 输入查询条件
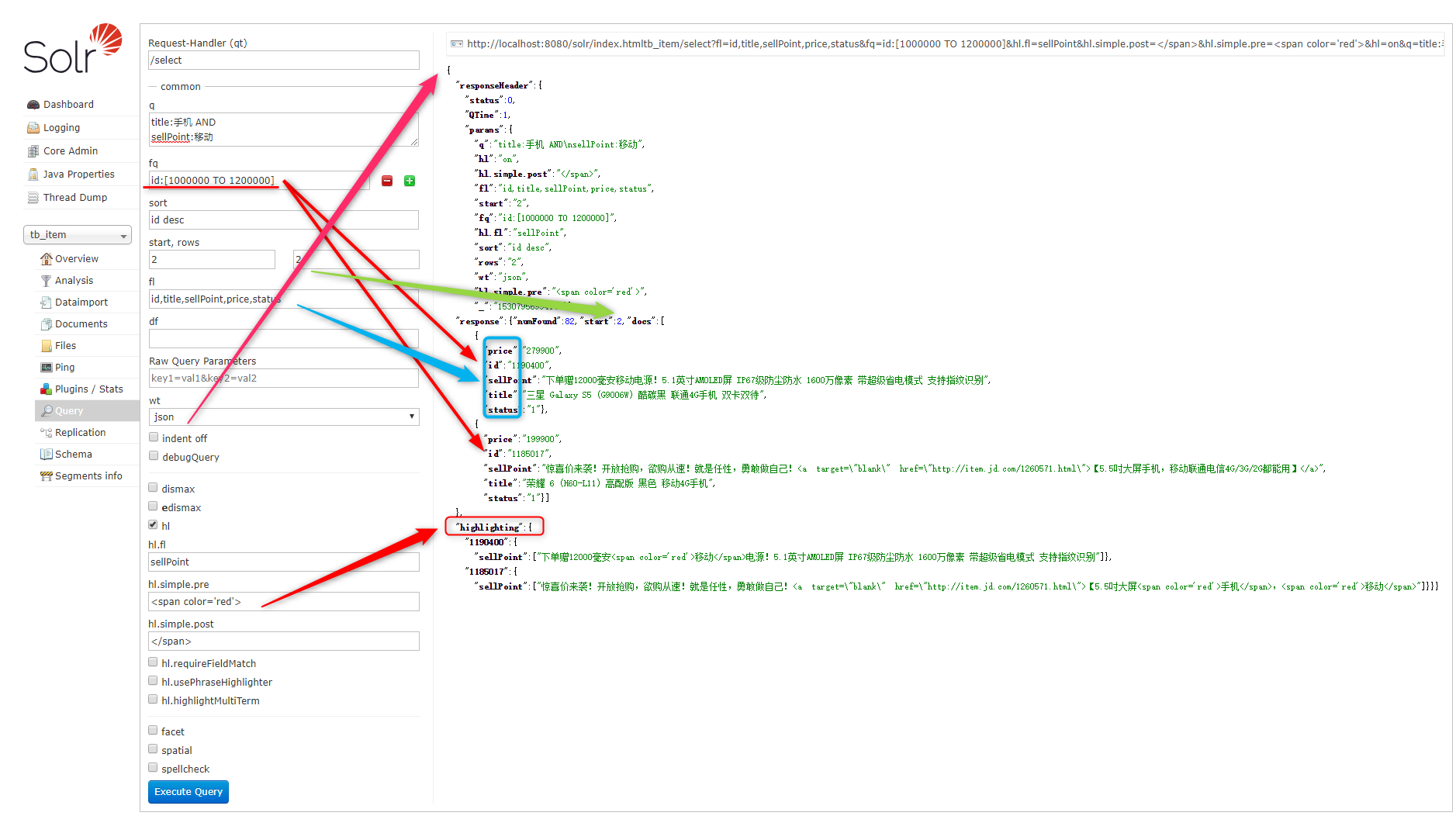
query.setQuery("title:手机 AND sellPoint:移动");
// 设置过滤条件
query.setFilterQueries("id:[1000000 TO 1200000]");
// 设置排序
query.addSort("id", SolrQuery.ORDER.desc);
// 设置分页信息(使用默认的)
query.setStart(2);
query.setRows(2);
// 设置显示的Field的域集合(两种方式二选一)
// query.setFields(new String[]{"id", "title", "sellPoint", "price", "status" });
query.setFields("id,title,sellPoint,price,status");
// 设置默认域
// query.set("df", "product_keywords");
// 设置高亮信息
query.setHighlight(true);
query.addHighlightField("title");
query.setHighlightSimplePre("<span color='red'>");
query.setHighlightSimplePost("</span>");
// 执行查询并返回结果
QueryResponse response = client.query(query);
// 获取匹配的所有结果
SolrDocumentList list = response.getResults();
// 匹配结果总数
long count = list.getNumFound();
System.out.println("总结果数:" + count);
// 获取高亮显示信息
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
for (SolrDocument document : list) {
System.out.println(document.get("id"));
List<String> list2 = highlighting.get(document.get("id")).get("title");
if (list2 != null)
System.out.println("高亮显示的商品名称:" + list2.get(0));
else {
System.out.println(document.get("title"));
}
}
}