1 Redis集群的介绍
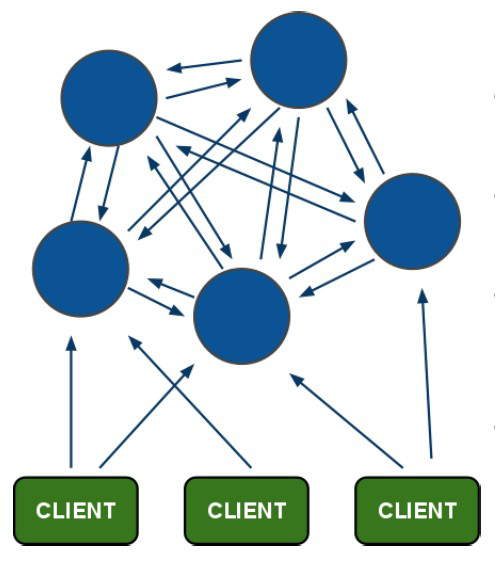
1.1 redis-cluster(集群)架构图
架构细节:
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail(失败)是通过集群中超过半数的节点检测失效时才生效.(那么要求集群最少三台服务器,每台在带一个备份,则最少6台服务器)
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot(槽)上,cluster负责维护node<->slot<->value
Redis集群中内置了 16384 个哈希槽,当需要在 Redis集群中放置一个 key-value时,redis先对 key使用 crc16算法算出一个结果,然后把结果对 16384求余数,这样每个 key都会对应一个编号在 0-16383之间的哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点
1.2 redis-cluster投票:容错
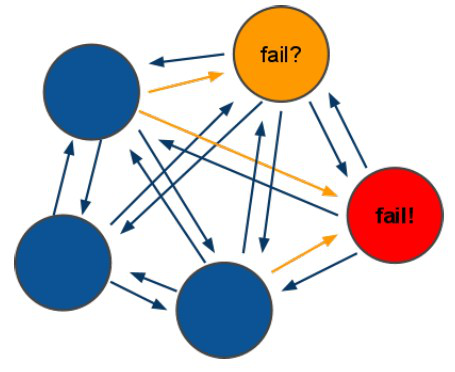

(1)领着投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态. ps : redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
b:如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误
2 Redis集群的搭建
2.1 集群搭建环境(ruby环境)
redis集群管理工具redis-trib.rb依赖ruby环境,首先需要安装ruby环境:
第一步:安装ruby
yum install ruby
yum install rubygems
第二步:安装ruby和redis的接口程序
拷贝redis-3.0.0.gem至/usr/local下
执行:gem install /usr/local/redis-3.0.0.gem
ruby的脚本在哪呢?在我们redis下的src源码下。
[root@localhost ~]# cd redis-3.0.0/src
[root@localhost src]# ll *.rb
-rwxrwxr-x. 1 root root 48141 Apr 1 2015 redis-trib.rb
需要将此脚本复制到我们的安装环境中。第一步:在我们安装redis中的bin目录下创建一个redis-cluster文件夹
[root@bogon src]# mkdir /usr/local/redis-cluster
第二步:将redis-trib.rb复制到创建的redis-cluster文件夹下
[root@bogon src]# cp redis-trib.rb /usr/local/redis-cluster/
然后用此脚本搭建集群
2.2 搭建步骤
集群中至少有三个节点。每个节点都需要有一个从节点。至少需要6台服务器(一主一备)。
因为笔者服务器有限,所以搭建一个伪分布式:
需要6个redis实例,运行在同一台服务器。端口号7001-7006。
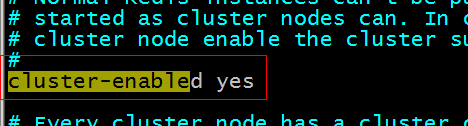
第一步:创建6个redis实例,每个实例运行在不同的端口。需要修改redis.conf配置文件。配置文件中还需要把cluster-enabled yes前的注释去掉。
在创建的目录中/user/local/redis下,一个bin就是一个redis实例,也就是一个redis服务器。所以复制/user/local/redis/bin 到 /user/local/redis-cluster/redis01 因为需要6个所以同理到06(注意将bin改名为redis0x了) 。
[root@bogon src]# cd /usr/local/redis
[root@bogon redis]# cp -r bin /usr/local/redis-cluster/redis01
[root@bogon redis]# cp -r bin /usr/local/redis-cluster/redis02
[root@bogon redis]# cp -r bin /usr/local/redis-cluster/redis03
[root@bogon redis]# cp -r bin /usr/local/redis-cluster/redis04
[root@bogon redis]# cp -r bin /usr/local/redis-cluster/redis05
[root@bogon redis]# cp -r bin /usr/local/redis-cluster/redis06
[root@bogon redis]#
更改每个redis0x下的redis.conf的端口号port并去掉cluster-enabled yes前的注释去掉
第二步:启动每个redis实例。这里启动每一个很麻烦,可以写一个启动这6个的脚本(创建一个start-all.sh)注意:这个脚本所在的位置!
[root@bogon redis-cluster]# vim start-all.sh输入:
cd redis01
./redis-server redis.conf
cd ..
cd redis02
./redis-server redis.conf
cd ..
cd redis03
./redis-server redis.conf
cd ..
cd redis04
./redis-server redis.conf
cd ..
cd redis05
./redis-server redis.conf
cd ..
cd redis06
./redis-server redis.conf
保存之后不能执行,需要修改权限
输入:chmod u+x start-all.sh
[root@bogon redis-cluster]# chmod u+x start-all.sh
修改完权限之后,输入./start-all.sh
[root@bogon redis-cluster]# ./start-all.sh
启动完毕!此时看一下进程确定启动成功
输入:ps aux|grep redis
[root@bogon redis-cluster]# ps aux|grep redis
能够看到
root 31635 0.0 0.1 33936 1988 ? Ssl 06:33 0:00 ./redis-server *:7001 [cluster]
root 31637 0.0 0.1 33936 1988 ? Ssl 06:33 0:00 ./redis-server *:7002 [cluster]
root 31641 0.0 0.1 33936 1988 ? Ssl 06:33 0:00 ./redis-server *:7003 [cluster]
root 31647 0.0 0.1 33936 1988 ? Ssl 06:33 0:00 ./redis-server *:7004 [cluster]
root 31649 0.0 0.1 33936 1984 ? Ssl 06:33 0:00 ./redis-server *:7005 [cluster]
root 31653 0.0 0.1 33936 1988 ? Ssl 06:33 0:00 ./redis-server *:7006 [cluster]
证明启动成功!
第三步:使用ruby脚本搭建集群。
编写脚本命令:
./redis-trib.rb create --replicas 1 192.168.204.134:7001 192.168.204.134:7002 192.168.204.134:7003 192.168.204.134:7004 192.168.204.134:7005 192.168.204.134:7006输入:脚本命令。
[root@bogon redis-cluster]# ./redis-trib.rb create --replicas 1 192.168.204.134:7001 192.168.204.134:7002 192.168.204.134:7003 192.168.204.134:7004 192.168.204.134:7005 192.168.204.134:7006
注意:这里因为拷贝的时候在第一章用过,导致有数据,不是新的,它会抛一个错,这个错是[ERR] Node 192.168.204.134:7001 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
这时:解决需要将集群关闭掉,然后每一个集群下的dump.rdb 和 nodes.conf删掉。在将集群从新启动。
1、编写关闭集群的批量脚本 创建关闭集群的脚本: [root@localhost redis-cluster]# vim shutdow-all.sh2、编写内容:
redis01/redis-cli -p 7001 shutdown
redis01/redis-cli -p 7002 shutdown
redis01/redis-cli -p 7003 shutdown
redis01/redis-cli -p 7004 shutdown
redis01/redis-cli -p 7005 shutdown
redis01/redis-cli -p 7006 shutdown
注意:(因为客户端可以连接所有的服务,所以只用redis01/redis-cli 关闭就可以)
3、更改关闭脚本的权限:[root@localhost redis-cluster]# chmod u+x shutdow-all.sh
4、执行关闭集群:./shutdow-all.sh
5、查看进程 ps aux|grep redis、关闭成功。
然后删除所有0x下的dump.rdb 执行批量命令:rm -f redis0*/dump.rdb
[root@bogon redis-cluster]# rm -f redis0*/dump.rdb
同理删除nodes.conf
[root@bogon redis-cluster]# rm -f redis0*/nodes.conf
删除成功!接下来重新启动
[root@bogon redis-cluster]# ./start-all.sh
[root@bogon redis-cluster]# ./redis-trib.rb create --replicas 1 192.168.204.134:7001 192.168.204.134:7002 192.168.204.134:7003 192.168.204.134:7004 192.168.204.134:7005 192.168.204.134:7006
-
>>> Performing hash slots allocation on 6 nodes... Using 3 masters: 192.168.204.134:7001 192.168.204.134:7002 192.168.204.134:7003 Adding replica 192.168.204.134:7004 to 192.168.204.134:7001 Adding replica 192.168.204.134:7005 to 192.168.204.134:7002 Adding replica 192.168.204.134:7006 to 192.168.204.134:7003 M: 6c011939ded42f173718917ed44d1da7476b9d5b 192.168.204.134:7001 slots:0-5460 (5461 slots) master M: f82a8527c278572b6d7957e0be0bb9360a85d957 192.168.204.134:7002 slots:5461-10922 (5462 slots) master M: 422b498bc52837b0125d74721466a207b8e9ce4d 192.168.204.134:7003 slots:10923-16383 (5461 slots) master S: d8092f56af3206899cb54ff4acb14bc8b13fd640 192.168.204.134:7004 replicates 6c011939ded42f173718917ed44d1da7476b9d5b S: 7d63094e086a0488ecbf0904092ca901fdfb3f16 192.168.204.134:7005 replicates f82a8527c278572b6d7957e0be0bb9360a85d957 S: 46f016bde6a8eef81697f6c75e1a8a74f7f415fc 192.168.204.134:7006 replicates 422b498bc52837b0125d74721466a207b8e9ce4d Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join... >>> Performing Cluster Check (using node 192.168.204.134:7001) M: 6c011939ded42f173718917ed44d1da7476b9d5b 192.168.204.134:7001 slots:0-5460 (5461 slots) master M: f82a8527c278572b6d7957e0be0bb9360a85d957 192.168.204.134:7002 slots:5461-10922 (5462 slots) master M: 422b498bc52837b0125d74721466a207b8e9ce4d 192.168.204.134:7003 slots:10923-16383 (5461 slots) master M: d8092f56af3206899cb54ff4acb14bc8b13fd640 192.168.204.134:7004 slots: (0 slots) master replicates 6c011939ded42f173718917ed44d1da7476b9d5b M: 7d63094e086a0488ecbf0904092ca901fdfb3f16 192.168.204.134:7005 slots: (0 slots) master replicates f82a8527c278572b6d7957e0be0bb9360a85d957 M: 46f016bde6a8eef81697f6c75e1a8a74f7f415fc 192.168.204.134:7006 slots: (0 slots) master replicates 422b498bc52837b0125d74721466a207b8e9ce4d [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
3 集群的使用方法
3.1 Redis-cli连接集群。
[root@localhost redis-cluster]# redis01/redis-cli -p 7002 -c
-c:代表连接的是redis集群
或者指定ip和端口的连接
[root@localhost redis-cluster]# redis01/redis-cli -h 192.168.25.174 -p 7006 -c
连接集群需要添加-c 参数。否则节点之间跳转失败。
集群版只有一个库。
使用的方法同单机版,见上一章。
3.2 查看集群状态
连接之后输入命令:cluster info
192.168.204.134:7006> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:10
cluster_my_epoch:8
cluster_stats_messages_sent:778
cluster_stats_messages_received:772
3.3 查看集群节点
连接之后输入命令:cluster nodes
192.168.204.134:7006> cluster nodes
f82a8527c278572b6d7957e0be0bb9360a85d957 192.168.204.134:7002 slave 7d63094e086a0488ecbf0904092ca901fdfb3f16 0 1497743623527 10 connected
6c011939ded42f173718917ed44d1da7476b9d5b 192.168.204.134:7001 slave d8092f56af3206899cb54ff4acb14bc8b13fd640 0 1497743622518 7 connected
46f016bde6a8eef81697f6c75e1a8a74f7f415fc 192.168.204.134:7006 myself,master - 0 0 8 connected 10923-16383
7d63094e086a0488ecbf0904092ca901fdfb3f16 192.168.204.134:7005 master - 0 1497743618478 10 connected 5461-10922
d8092f56af3206899cb54ff4acb14bc8b13fd640 192.168.204.134:7004 master - 0 1497743617468 7 connected 0-5460
422b498bc52837b0125d74721466a207b8e9ce4d 192.168.204.134:7003 slave 46f016bde6a8eef81697f6c75e1a8a74f7f415fc 0 1497743619488 8 connected
图形工具不支持集群。
说明:
./redis-cli -c -h 192.168.204.134 -p 7001 ,其中-c表示以集群方式连接redis,-h指定ip地址,-p指定端口号
cluster nodes 查询集群结点信息
cluster info 查询集群状态信息
3.4 jedis连接集群版。(重点)
3.4.1 jedis连接集群不使用连接池
jedis的详解见上一章。
导入的jar包和上一章一样,是那两个jar包(commons-pool2-2.3.jar和jedis-2.7.0.jar)
如何连接集群版,
第一步:使用JedisCluster对象。需要一个Set<HostAndPort>参数。Redis节点的列表。
第二步:直接使用JedisCluster对象操作redis。在系统中单例存在。
第三步:打印结果
第四步:系统关闭前,关闭JedisCluster对象。
@Test
public void testJedisCluster() throws Exception {
// 第一步:使用JedisCluster对象。需要一个Set<HostAndPort>参数。Redis节点的列表。
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.204.134", 7001));
nodes.add(new HostAndPort("192.168.204.134", 7002));
nodes.add(new HostAndPort("192.168.204.134", 7003));
nodes.add(new HostAndPort("192.168.204.134", 7004));
nodes.add(new HostAndPort("192.168.204.134", 7005));
nodes.add(new HostAndPort("192.168.204.134", 7006));
JedisCluster jedisCluster = new JedisCluster(nodes);
// 第二步:直接使用JedisCluster对象操作redis。在系统中单例存在。
jedisCluster.set("hello", "100");
String result = jedisCluster.get("hello");
// 第三步:打印结果
System.out.println(result);
// 第四步:系统关闭前,关闭JedisCluster对象。
jedisCluster.close();
}
3.4.2 jedis连接redis集群使用连接池
// 连接redis集群并使用连接池
@Test
public void testJedisCluster2() {
//获取连接对象可以省略使用默认(配置JEdisPoolConfig的设置)
JedisPoolConfig config = new JedisPoolConfig();
// 最大连接数
config.setMaxTotal(30);
// 最大连接空闲数
config.setMaxIdle(2);
//集群结点
Set<HostAndPort> jedisClusterNode = new HashSet<HostAndPort>();
jedisClusterNode.add(new HostAndPort("192.168.204.134", 7001));
jedisClusterNode.add(new HostAndPort("192.168.204.134", 7002));
jedisClusterNode.add(new HostAndPort("192.168.204.134", 7003));
jedisClusterNode.add(new HostAndPort("192.168.204.134", 7004));
jedisClusterNode.add(new HostAndPort("192.168.204.134", 7005));
jedisClusterNode.add(new HostAndPort("192.168.204.134", 7006));
JedisCluster jc = new JedisCluster(jedisClusterNode, config);
JedisCluster jcd = new JedisCluster(jedisClusterNode);
jcd.set("name", "zhangsan");
String value = jcd.get("name");
System.out.println(value);
}
3.4.3 jedis连接使用spring
配置applicationContext.xml
<!-- 连接池配置 -->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大连接数 -->
<property name="maxTotal" value="30" />
<!-- 最大空闲连接数 -->
<property name="maxIdle" value="10" />
<!-- 每次释放连接的最大数目 -->
<property name="numTestsPerEvictionRun" value="1024" />
<!-- 释放连接的扫描间隔(毫秒) -->
<property name="timeBetweenEvictionRunsMillis" value="30000" />
<!-- 连接最小空闲时间 -->
<property name="minEvictableIdleTimeMillis" value="1800000" />
<!-- 连接空闲多久后释放, 当空闲时间>该值 且 空闲连接>最大空闲连接数 时直接释放 -->
<property name="softMinEvictableIdleTimeMillis" value="10000" />
<!-- 获取连接时的最大等待毫秒数,小于零:阻塞不确定的时间,默认-1 -->
<property name="maxWaitMillis" value="1500" />
<!-- 在获取连接的时候检查有效性, 默认false -->
<property name="testOnBorrow" value="true" />
<!-- 在空闲时检查有效性, 默认false -->
<property name="testWhileIdle" value="true" />
<!-- 连接耗尽时是否阻塞, false报异常,ture阻塞直到超时, 默认true -->
<property name="blockWhenExhausted" value="false" />
</bean>
<!-- redis集群 -->
<bean id="jedisCluster" class="redis.clients.jedis.JedisCluster">
<constructor-arg index="0">
<set>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.204.134"></constructor-arg>
<constructor-arg index="1" value="7001"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.204.134"></constructor-arg>
<constructor-arg index="1" value="7002"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.204.134"></constructor-arg>
<constructor-arg index="1" value="7003"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.204.134"></constructor-arg>
<constructor-arg index="1" value="7004"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.204.134"></constructor-arg>
<constructor-arg index="1" value="7005"></constructor-arg>
</bean>
<bean class="redis.clients.jedis.HostAndPort">
<constructor-arg index="0" value="192.168.204.134"></constructor-arg>
<constructor-arg index="1" value="7006"></constructor-arg>
</bean>
</set>
</constructor-arg>
<constructor-arg index="1" ref="jedisPoolConfig"></constructor-arg>
</bean>
测试代码
private ApplicationContext applicationContext;
@Before
public void init() {
applicationContext = new ClassPathXmlApplicationContext(
"classpath:applicationContext.xml");
}
//redis集群
@Test
public void testJedisCluster() {
JedisCluster jedisCluster = (JedisCluster) applicationContext
.getBean("jedisCluster");
jedisCluster.set("name", "zhangsan");
String value = jedisCluster.get("name");
System.out.println(value);
}
实际应用的例子这里就不做介绍了,下面介绍一下附录:
4附:
4.1 redis.conf
Redis 支持很多的参数,但都有默认值。
daemonize:
默认情况下,redis 不是在后台运行的,如果需要在后台运行,把该项的值更改为yes
pidfile
当Redis 在后台运行的时候,Redis 默认会把pid 文件放在/var/run/redis.pid,你可以配置到其他地址。当运行多个redis 服务时,需要指定不同的pid 文件和端口
bind
指定Redis 只接收来自于该IP 地址的请求,如果不进行设置,那么将处理所有请求,在生产环境中最好设置该项
port
监听端口,默认为6379
timeout
设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接
loglevel
log 等级分为4 级,debug, verbose, notice, 和warning。生产环境下一般开启notice
logfile
配置log 文件地址,默认使用标准输出,即打印在命令行终端的窗口上
databases
设置数据库的个数,可以使用SELECT <dbid>命令来切换数据库。默认使用的数据库是0
save
设置Redis 进行数据库镜像的频率。
if(在60 秒之内有10000 个keys 发生变化时){
进行镜像备份
}else if(在300 秒之内有10 个keys 发生了变化){
进行镜像备份
}else if(在900 秒之内有1 个keys 发生了变化){
进行镜像备份
}
rdbcompression
在进行镜像备份时,是否进行压缩
dbfilename
镜像备份文件的文件名
dir
数据库镜像备份的文件放置的路径。这里的路径跟文件名要分开配置是因为Redis 在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,再把该该临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中
slaveof
设置该数据库为其他数据库的从数据库
masterauth
当主数据库连接需要密码验证时,在这里指定
requirepass
设置客户端连接后进行任何其他指定前需要使用的密码。警告:因为redis 速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行150K 次的密码尝试,这意味着你需要指定非常非常强大的密码来防止暴力破解。
maxclients
限制同时连接的客户数量。当连接数超过这个值时,redis 将不再接收其他连接请求,客户端尝试连接时将收到error 信息。
maxmemory
设置redis 能够使用的最大内存。当内存满了的时候,如果还接收到set 命令,redis 将先尝试剔除设置过expire 信息的key,而不管该key 的过期时间还没有到达。在删除时,将按照过期时间进行删除,最早将要被过期的key 将最先被删除。如果带有expire 信息的key 都删光了,那么将返回错误。这样,redis 将不再接收写请求,只接收get 请求。maxmemory 的设置比较适合于把redis 当作于类似memcached 的缓存来使用。
appendonly
默认情况下,redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。所以redis 提供了另外一种更加高效的数据库备份及灾难恢复方式。开启append only 模式之后,redis会把所接收到的每一次写操作请求都追加到appendonly.aof 文件中,当redis 重新启动时,会从该文件恢复出之前的状态。但是这样会造成appendonly.aof 文件过大,所以redis 还支持了BGREWRITEAOF 指令,对appendonly.aof 进行重新整理。所以我认为推荐生产环境下的做法为关闭镜像,开启appendonly.aof,同时可以选择在访问较少的时间每天对appendonly.aof 进行重写一次。
appendfsync
设置对appendonly.aof 文件进行同步的频率。always 表示每次有写操作都进行同步,everysec 表示对写操作进行累积,每秒同步一次。这个需要根据实际业务场景进行配置
vm-enabled
是否开启虚拟内存支持。因为redis 是一个内存数据库,而且当内存满的时候,无法接收新的写请求,所以在redis 2.0 中,提供了虚拟内存的支持。但是需要注意的是,redis中,所有的key 都会放在内存中,在内存不够时,只会把value 值放入交换区。这样保证了虽然使用虚拟内存,但性能基本不受影响,同时,你需要注意的是你要把vm-max-memory 设置到足够来放下你的所有的key
vm-swap-file
设置虚拟内存的交换文件路径
vm-max-memory
这里设置开启虚拟内存之后,redis 将使用的最大物理内存的大小。默认为0,redis 将把他所有的能放到交换文件的都放到交换文件中,以尽量少的使用物理内存。在生产环境下,需要根据实际情况设置该值,最好不要使用默认的0
vm-page-size
设置虚拟内存的页大小,如果你的value 值比较大,比如说你要在value 中放置博客、新闻之类的所有文章内容,就设大一点,如果要放置的都是很小的内容,那就设小一点。
vm-pages
设置交换文件的总的page 数量,需要注意的是,page table 信息会放在物理内存中,每8 个page 就会占据RAM 中的1 个byte。总的虚拟内存大小 = vm-page-size * vm-pages
vm-max-threads
设置VM IO 同时使用的线程数量。因为在进行内存交换时,对数据有编码和解码的过程,所以尽管IO 设备在硬件上本上不能支持很多的并发读写,但是还是如果你所保存的vlaue 值比较大,将该值设大一些,还是能够提升性能的
glueoutputbuf
把小的输出缓存放在一起,以便能够在一个TCP packet 中为客户端发送多个响应,具体原理和真实效果我不是很清楚。所以根据注释,你不是很确定的时候就设置成yes
hash-max-zipmap-entries
在redis 2.0 中引入了hash 数据结构。当hash 中包含超过指定元素个数并且最大的元素没有超过临界时,hash 将以一种特殊的编码方式(大大减少内存使用)来存储,这里可以设置这两个临界值
activerehashing
开启之后,redis 将在每100 毫秒时使用1 毫秒的CPU 时间来对redis 的hash 表进行重新hash,可以降低内存的使用。当你的使用场景中,有非常严格的实时性需要,不能够接受Redis 时不时的对请求有2 毫秒的延迟的话,把这项配置为no。如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存