1. 引言
libsvm函数包的组织结构图如下图所示。主文件路径中包含了核心的C/C++程序和例子数据,以及java、python版本的实现。tool子文件路径中包含了一些检验数据格式以及选择svm参数的tool,其为辅助作用。
在此,本文先以svm.h及svm.cpp做简单结构分析。
svm.h中主要是定义了4个结构体,分别是svm_node、svm_problem、svm_parameter、svm_model,然后就是19个函数的声明。如svm_node结构体:
struct svm_node
{
int index;
double value;
};这个结构体用于存储单一向量中的单个特征。例如:向量x1={0.002,0.345,4.000,5.677},则用svm_node来存储就是使用一个包含5个svm_node的数组来存储这个4维向量,内存中的表示如下:
| 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| 0.002 | 0.345 | 4.000 | 5.677 | 空 |
svm.cpp是核心文件,实现了svm算法的核心功能,里面总共有Cache、Kernel、ONE_CLASS_Q、QMatrix、Solver、Solver_NU、SVC_Q、SVR_Q8个类,如下图所示:

上述文件暂不做详细分析,列出c/c++语言版本的意图旨在对比其他语言,如java版本,用以表明不同语言的实现基本一致。后续内容将围绕java版本来原理分析。这样写的目的在于告诉读者,如果你熟悉的语言不是java,大可不必担心语言问题。如上述svm_node结构及几个核心类,在java中同样实现,如下图所示。
2 代码分析
2.1 svm_node代码分析
svm_node.java
整个文件源码非常少:
package libsvm;
public class svm_node implements java.io.Serializable
{
public int index; //存储单一向量的索引
public double value; //存储对应索引位置的值
}2.2 svm_problem代码分析
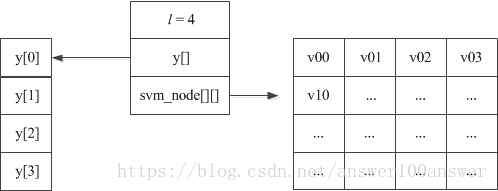
svm_problem.java如下
package libsvm;
public class svm_problem implements java.io.Serializable
{
public int l; //记录样本总数
public double[] y; //样本所属类别(标签,如+1,-1)的数组
public svm_node[][] x; //存储样本内容出标签外的信息
}
这个class结构存储本次参加运算的所有样本及其所属类别,一个示意图如下:
2.3 svm_parameter代码分析
svm_parameter.java
package libsvm;
public class svm_parameter implements Cloneable,java.io.Serializable
{
/* svm_type */
public static final int C_SVC = 0;
public static final int NU_SVC = 1;
public static final int ONE_CLASS = 2;
public static final int EPSILON_SVR = 3;
public static final int NU_SVR = 4;
/* kernel_type */
public static final int LINEAR = 0;
public static final int POLY = 1;
public static final int RBF = 2;
public static final int SIGMOID = 3;
public static final int PRECOMPUTED = 4;
public int svm_type;
public int kernel_type;
public int degree; // for poly 即,多项式核
public double gamma; // for poly/rbf/sigmoid (rbf为高斯核径向基)
public double coef0; // for poly/sigmoid
// these are for training only
public double cache_size; // in MB
public double eps; // stopping criteria
public double C; // for C_SVC, EPSILON_SVR and NU_SVR
public int nr_weight; // for C_SVC
public int[] weight_label; // for C_SVC
public double[] weight; // for C_SVC
public double nu; // for NU_SVC, ONE_CLASS, and NU_SVR
public double p; // for EPSILON_SVR
public int shrinking; // use the shrinking heuristics
public int probability; // do probability estimates
}
该class是对svm类型及参数的设置,在svm.java中会用到。

2.3 svm_model代码分析
svm_model.java
package libsvm;
public class svm_model implements java.io.Serializable
{
public svm_parameter param; // parameter
public int nr_class; // number of classes, = 2 in regression/one class svm
public int l; // total #SV
public svm_node[][] SV; // SVs (SV[l])
public double[][] sv_coef; // coefficients for SVs in decision functions (sv_coef[k-1][l])
public double[] rho; // constants in decision functions (rho[k*(k-1)/2])
public double[] probA; // pariwise probability information
public double[] probB;
public int[] sv_indices; // sv_indices[0,...,nSV-1] are values in [1,...,num_traning_data] to indicate SVs in the training set
// for classification only
public int[] label; // label of each class (label[k])
public int[] nSV; // number of SVs for each class (nSV[k])
// nSV[0] + nSV[1] + ... + nSV[k-1] = l
};
用于保存训练后的训练模型model,在predict中要用到。
3 核心代码分析
svm.java总共有2000多行代码,实现了svm算法的核心功能,里面总共有Cache、Kernel、ONE_CLASS_Q、QMatrix、Solver、Solver_NU、SVC_Q、SVR_Q 8个内部类。
1 Cache
class Cache {
private final int l; //数据总条目
private long size; //缓存大小
private final class head_t
{
head_t prev, next; // a cicular list 定义了链表节点
float[] data;
int len; // data[0,len) is cached in this entry
}
private final head_t[] head; //链表的一个数组
/*
* head[0] -------------- head[1] ------------- haad[2]
* | | |
* prev,next,len,data[0] ... ...
* data[1] ... ...
*/
private head_t lru_head;
Cache(int l_, long size_) //Cache的构造函数,带数据个数和缓存大小
{...}
private void lru_delete(head_t h) //删除当前节点
{
// delete from current location
h.prev.next = h.next;
h.next.prev = h.prev;
}
...
}这个类的主要功能是:负责运算所涉及的内存管理,包括申请、释放等。上述class head_t,它是一个双向链表方便前后内存的访问。
参考:https://blog.csdn.net/linj_m/article/details/19571663
2 Kernel
Kernel类主要是为SVM的核函数服务的,里面实现了SVM常用的核函数。
其中几个常用核函数如下所示:(一般情况下,使用RBF核函数能取得很好的效果)

参考:https://blog.csdn.net/linj_m/article/details/19574623
上述涉及矩阵运算
即:
线性核(
linear):主要用于线性可分的情况,我们可以看到特征空间到输入空间的维度是一样的,其参数少速度快,对于线性可分数据,其分类效果很理想,因此我们通常首先尝试用线性核函数来做分类,看看效果如何,如果不行再换别的K(x,z)=<x,z>行向量x与z向量积。如
x=[1 2 3],z=[11 22 33],则<x,z>=1*11+2822+3*33。多项式核(
poly):多项式核函数可以实现将低维的输入空间映射到高纬的特征空间,但是多项式核函数的参数多,当多项式的阶数比较高的时候,核矩阵的元素值将趋于无穷大或者无穷小,计算复杂度会大到无法计算K(x,z)=(<x,z>+c)^d其中x,z是向量。d=1,c=0时退化为线性核。
高斯径向基核(
RBF):高斯径向基函数是一种局部性强的核函数,其可以将一个样本映射到一个更高维的空间内,该核函数是应用最广的一个,无论大样本还是小样本都有比较好的性能,而且其相对于多项式核函数参数要少,因此大多数情况下在不知道用什么核函数的时候,优先使用高斯核函数- 多层感知器核(
sigmoid):采用sigmoid核函数,支持向量机实现的就是一种多层神经网络
Kernel继承于QMatrix,Kernel主要实现了以下方法:
powi
/*
* 乘方函数重写,效率相比自带函数较高
*/
private static double powi(double base, int times)kernel_function
/*
* 根据不同的kernel_type分类。返回第i,j两行向量的核运算结果
* i,j表示前向量第i行,后向量j列的输入数据,此函数仅得到运算矩阵中的一个点
*/
double kernel_function(int i, int j)Kernel
/*
* Kernel带参构造器,将样本总数l、除分类标签数据外的数据svm_node[][]、参数传入
*/
Kernel(int l, svm_node[][] x_, svm_parameter param)dot
static double dot(svm_node[] x, svm_node[] y) //参数为两行向量(单行单列向量)k_function
/*
* 根据不同的kernel_type分类,及参数。返回向量x、向量j的核运算结果。
* (和kernel_function类似)
*/
static double k_function(svm_node[] x, svm_node[] y,
svm_parameter param)完整代码及注释如下:
//
// Kernel evaluation
//
// the static method k_function is for doing single kernel evaluation
// the constructor of Kernel prepares to calculate the l*l kernel matrix
// the member function get_Q is for getting one column from the Q Matrix
//
abstract class QMatrix {
abstract float[] get_Q(int column, int len);
abstract double[] get_QD();
abstract void swap_index(int i, int j);
};
abstract class Kernel extends QMatrix {
private svm_node[][] x;
private final double[] x_square;
// svm_parameter
private final int kernel_type;
private final int degree;
private final double gamma;
private final double coef0;
abstract float[] get_Q(int column, int len);
abstract double[] get_QD();
void swap_index(int i, int j)
{
do {svm_node[] tmp=x[i]; x[i]=x[j]; x[j]=tmp;} while(false);
if(x_square != null) do {double tmp=x_square[i]; x_square[i]=x_square[j]; x_square[j]=tmp;} while(false);
}
/*
* 乘方函数重写,效率相比自带函数较高
*/
private static double powi(double base, int times)
{
double tmp = base, ret = 1.0;
for(int t=times; t>0; t/=2)
{
if(t%2==1) ret*=tmp;
tmp = tmp * tmp;
}
return ret;
}
/*
* 根据不同的kernel_type分类。返回第i,j两行向量的核运算结果
*/
double kernel_function(int i, int j) //i,j表示前向量第i行,后向量j列的输入数据,此函数仅得到运算矩阵中的一个点
{
switch(kernel_type) //kernel_type是int型的参数
{
case svm_parameter.LINEAR: //0 线性核
// K(x,z)=<x,z>
return dot(x[i],x[j]); //对应索引相乘再相加
case svm_parameter.POLY: //1 多项式核
return powi(gamma*dot(x[i],x[j])+coef0,degree);
case svm_parameter.RBF: //2
return Math.exp(-gamma*(x_square[i]+x_square[j]-2*dot(x[i],x[j])));
case svm_parameter.SIGMOID:
return Math.tanh(gamma*dot(x[i],x[j])+coef0);
case svm_parameter.PRECOMPUTED:
return x[i][(int)(x[j][0].value)].value;
default:
return 0; // java
}
}
/*
* Kernel带参构造器,将样本总数l、除分类标签数据外的数据svm_node[][]、参数传入
*/
Kernel(int l, svm_node[][] x_, svm_parameter param)
{
this.kernel_type = param.kernel_type;
this.degree = param.degree;
this.gamma = param.gamma;
this.coef0 = param.coef0;
x = (svm_node[][])x_.clone();//将数据备份一次
if(kernel_type == svm_parameter.RBF) //当高斯径向基核时
{
x_square = new double[l];
for(int i=0;i<l;i++)
x_square[i] = dot(x[i],x[i]);
}
else x_square = null;
}
/*
* 将x,y对应索引相乘相加。判断索引相等,是因为允许值为0是index省略。
* 11 22 33
* 1 3 5
* 则结果11*1+22*3+33*5
*/
static double dot(svm_node[] x, svm_node[] y) //参数为两行向量(单行单列向量)
{
double sum = 0;
int xlen = x.length;
int ylen = y.length;
int i = 0;
int j = 0;
while(i < xlen && j < ylen)
{
if(x[i].index == y[j].index) //如果是对应的位置
sum += x[i++].value * y[j++].value;
else
{
if(x[i].index > y[j].index)
++j;
else
++i;
}
}
return sum;
}
/*
* 根据不同的kernel_type分类,及参数。返回向量x、向量j的核运算结果。(和kernel_function类似)
*/
static double k_function(svm_node[] x, svm_node[] y,
svm_parameter param)
{
switch(param.kernel_type)
{
case svm_parameter.LINEAR:
return dot(x,y);
case svm_parameter.POLY:
return powi(param.gamma*dot(x,y)+param.coef0,param.degree);
case svm_parameter.RBF:
{
double sum = 0;
int xlen = x.length;
int ylen = y.length;
int i = 0;
int j = 0;
while(i < xlen && j < ylen)
{
if(x[i].index == y[j].index)
{
double d = x[i++].value - y[j++].value;
sum += d*d;
}
else if(x[i].index > y[j].index)
{
sum += y[j].value * y[j].value;
++j;
}
else
{
sum += x[i].value * x[i].value;
++i;
}
}
while(i < xlen)
{
sum += x[i].value * x[i].value;
++i;
}
while(j < ylen)
{
sum += y[j].value * y[j].value;
++j;
}
return Math.exp(-param.gamma*sum);
}
case svm_parameter.SIGMOID:
return Math.tanh(param.gamma*dot(x,y)+param.coef0);
case svm_parameter.PRECOMPUTED:
return x[(int)(y[0].value)].value;
default:
return 0; // java
}
}
}
3 Solver
现在我们涉及到的Solver类是一个SVM优化求解的实现技术:SMO(Sequential Minimal Optimization)即序列最小优化算法。libsvm中最原始的Solver的代码有六百多行,再加上各种变形就上千行了,为了好理解,我们先来看看理论问题。
代码的开头如下:
// An SMO algorithm in Fan et al., JMLR 6(2005), p. 1889--1918
// Solves:
//
// min 0.5(\alpha^T Q \alpha) + p^T \alpha
//
// y^T \alpha = \delta
// y_i = +1 or -1
// 0 <= alpha_i <= Cp for y_i = 1
// 0 <= alpha_i <= Cn for y_i = -1
//
// Given:
//
// Q, p, y, Cp, Cn, and an initial feasible point \alpha
// l is the size of vectors and matrices
// eps is the stopping tolerance
//
// solution will be put in \alpha, objective value will be put in obj
//SMO(Sequential Minimal Optimization)是针对求解SVM问题的Lagrange对偶问题,一个二次规划式,开发的高效算法。传统的二次规划算法的计算开销正比于训练集的规模,而SMO基于问题本身的特性(KKT条件约束)对这个特殊的二次规划问题的求解过程进行优化。对偶问题中我们最后求解的变量只有Lagrange乘子向量,这个算法的基本思想就是每次都只选取一对,固定向量其他维度的元素的值,然后进行优化,直至收敛。
链接:https://www.zhihu.com/question/40546280/answer/88539689
SMO干了什么?
SMO算法是将分解算法思想推向极致得出的,即每次迭代仅优化两个点的最小子集

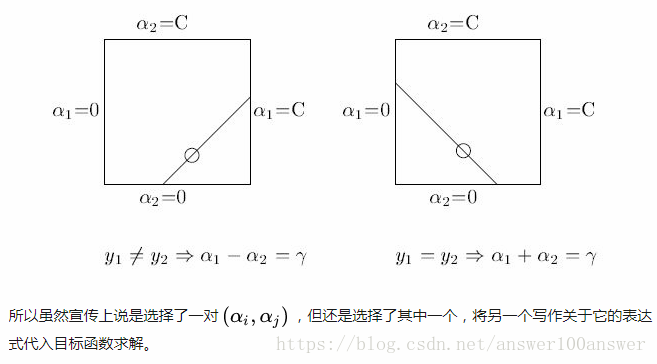
其中,yi=1或-1
为什么SMO跑的那么快

参考:https://www.zhihu.com/question/40546280?sort=created
SMO代码:
void Solve(int l, QMatrix Q, double[] p_, byte[] y_,
double[] alpha_, double Cp, double Cn, double eps, SolutionInfo si, int shrinking)
{
this.l = l;
this.Q = Q;
QD = Q.get_QD();
p = (double[])p_.clone();
y = (byte[])y_.clone();
alpha = (double[])alpha_.clone();
this.Cp = Cp;
this.Cn = Cn;
this.eps = eps;
this.unshrink = false;
// initialize alpha_status 初始化alpha
{
alpha_status = new byte[l];
for(int i=0;i<l;i++)
update_alpha_status(i);
}
// initialize active set (for shrinking)
{
active_set = new int[l];
for(int i=0;i<l;i++)
active_set[i] = i;
active_size = l;
}
// initialize gradient
{
G = new double[l];
G_bar = new double[l];
int i;
for(i=0;i<l;i++)
{
G[i] = p[i];
G_bar[i] = 0;
}
for(i=0;i<l;i++)
if(!is_lower_bound(i))
{
float[] Q_i = Q.get_Q(i,l);
double alpha_i = alpha[i];
int j;
for(j=0;j<l;j++)
G[j] += alpha_i*Q_i[j];
if(is_upper_bound(i))
for(j=0;j<l;j++)
G_bar[j] += get_C(i) * Q_i[j];
}
}
// optimization step 优化步骤
int iter = 0;
int max_iter = Math.max(10000000, l>Integer.MAX_VALUE/100 ? Integer.MAX_VALUE : 100*l);
int counter = Math.min(l,1000)+1;
int[] working_set = new int[2];
while(iter < max_iter) //迭代次数小于最大迭代次数时
{
// show progress and do shrinking
if(--counter == 0)
{
counter = Math.min(l,1000);
if(shrinking!=0) do_shrinking();
svm.info(".");
}
if(select_working_set(working_set)!=0)
{
// reconstruct the whole gradient
reconstruct_gradient();
// reset active set size and check
active_size = l;
svm.info("*");
if(select_working_set(working_set)!=0)
break;
else
counter = 1; // do shrinking next iteration
}
int i = working_set[0];
int j = working_set[1];
++iter;
// 更新两个alpha
// update alpha[i] and alpha[j], handle bounds carefully
float[] Q_i = Q.get_Q(i,active_size);
float[] Q_j = Q.get_Q(j,active_size);
double C_i = get_C(i);
double C_j = get_C(j);
double old_alpha_i = alpha[i];
double old_alpha_j = alpha[j];
if(y[i]!=y[j])
{
double quad_coef = QD[i]+QD[j]+2*Q_i[j];
if (quad_coef <= 0)
quad_coef = 1e-12;
double delta = (-G[i]-G[j])/quad_coef;
double diff = alpha[i] - alpha[j];
alpha[i] += delta;
alpha[j] += delta;
if(diff > 0)
{
if(alpha[j] < 0)
{
alpha[j] = 0;
alpha[i] = diff;
}
}
else
{
if(alpha[i] < 0)
{
alpha[i] = 0;
alpha[j] = -diff;
}
}
if(diff > C_i - C_j)
{
if(alpha[i] > C_i)
{
alpha[i] = C_i;
alpha[j] = C_i - diff;
}
}
else
{
if(alpha[j] > C_j)
{
alpha[j] = C_j;
alpha[i] = C_j + diff;
}
}
}
else
{
double quad_coef = QD[i]+QD[j]-2*Q_i[j];
if (quad_coef <= 0)
quad_coef = 1e-12;
double delta = (G[i]-G[j])/quad_coef;
double sum = alpha[i] + alpha[j];
alpha[i] -= delta;
alpha[j] += delta;
if(sum > C_i)
{
if(alpha[i] > C_i)
{
alpha[i] = C_i;
alpha[j] = sum - C_i;
}
}
else
{
if(alpha[j] < 0)
{
alpha[j] = 0;
alpha[i] = sum;
}
}
if(sum > C_j)
{
if(alpha[j] > C_j)
{
alpha[j] = C_j;
alpha[i] = sum - C_j;
}
}
else
{
if(alpha[i] < 0)
{
alpha[i] = 0;
alpha[j] = sum;
}
}
}
// update G
double delta_alpha_i = alpha[i] - old_alpha_i;
double delta_alpha_j = alpha[j] - old_alpha_j;
for(int k=0;k<active_size;k++)
{
G[k] += Q_i[k]*delta_alpha_i + Q_j[k]*delta_alpha_j;
}
// update alpha_status and G_bar
{
boolean ui = is_upper_bound(i);
boolean uj = is_upper_bound(j);
update_alpha_status(i);
update_alpha_status(j);
int k;
if(ui != is_upper_bound(i))
{
Q_i = Q.get_Q(i,l);
if(ui)
for(k=0;k<l;k++)
G_bar[k] -= C_i * Q_i[k];
else
for(k=0;k<l;k++)
G_bar[k] += C_i * Q_i[k];
}
if(uj != is_upper_bound(j))
{
Q_j = Q.get_Q(j,l);
if(uj)
for(k=0;k<l;k++)
G_bar[k] -= C_j * Q_j[k];
else
for(k=0;k<l;k++)
G_bar[k] += C_j * Q_j[k];
}
}
}
if(iter >= max_iter)
{
if(active_size < l)
{
// reconstruct the whole gradient to calculate objective value
reconstruct_gradient();
active_size = l;
svm.info("*");
}
System.err.print("\nWARNING: reaching max number of iterations\n");
}
// calculate rho
si.rho = calculate_rho();
// calculate objective value
{
double v = 0;
int i;
for(i=0;i<l;i++)
v += alpha[i] * (G[i] + p[i]);
si.obj = v/2;
}
// put back the solution
{
for(int i=0;i<l;i++)
alpha_[active_set[i]] = alpha[i];
}
si.upper_bound_p = Cp;
si.upper_bound_n = Cn;
//打印迭代次数
svm.info("\noptimization finished, #iter = "+iter+"\n");
}