周末这几天都忙着东奔西跑,比赛也在周末结束了,故现来总结一波。这次报名蚂蚁金服风险大赛主要是为了做个案例,用国内落地案例最多的大数据平台TDH社区版+可拖拽式快速人工智能平台Sophon来完成。
数据预处理(编码2分钟+运行5分钟):
上传至HDFS,用分布式SQL引擎兼数据仓库来完成用于分析的海量业务数据存储。用Java处理数据,得到我们需要的格式。至于替换缺失值等操作完全可以在sophon中实现,极为方便。
建模(拖拽2分钟+调参运行10分钟):
随机森林、梯度提升树、xgboost、svm。没有不好的算法,只有不好的数据和参数。所以在算法选择上建议大家不要犹豫,随机森林或xgboost就够用了。如果你的特征工程做得好、模型参数调得好,结果自然就会好。
其中随机森林在每颗树的深度和树的个数较高时具有不错的效果,但耗时相对较久。而xgboost和梯度提升树在默认参数下,较短的时间内就能获得相对较好的结果。具体模型的建立过程大家参考前几篇博客:

风险大脑-支付风险识别天池大赛(三)快速建立模型(含调参思路)
风险大脑-支付风险识别天池大赛(四)处理无标签数据、建立完整模型
当你拖完下面的算子后,你的工作已经完成了90%了,sophon就是这么强大!
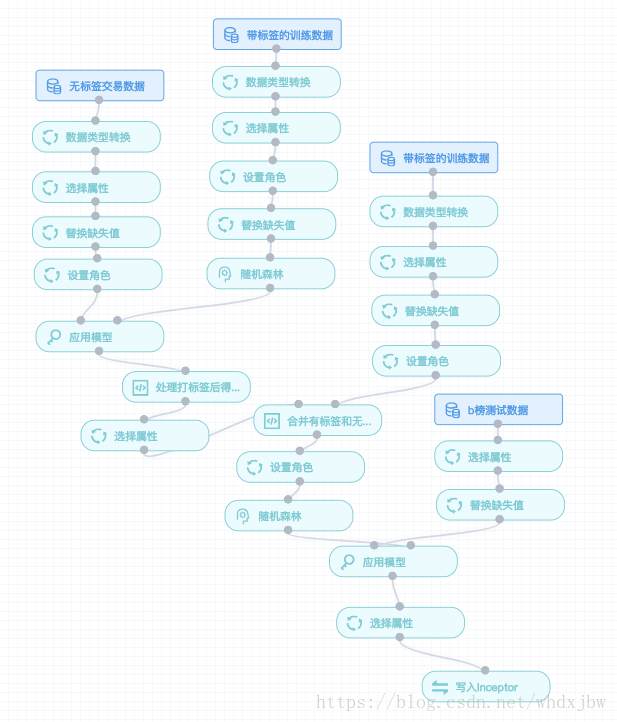
处理输出数据(编码2分钟+运行1分钟):
这次直接用决定最终成绩的B榜数据去测试的,故得到结果直接参与排名。具体模型结果处理参考如下博文:
险大脑-支付风险识别天池大赛(五)处理模型输出并提交结果、“榜上有名”
刷刷刷:
排行榜这种东西是有毒的,会让你一直想改进自己模型不断优化,当初本来不是抱着这个目的参赛的,只想做个案例。结果还是中毒了,可能博主比较喜欢刚 !
!
结果:

差不多提交了8次,最终成绩,看着不错,其实还没出线 :
:

可改进的地方:
1、端正参赛动机,不是为了得到第一,就不要去报名!
2、无标签数据其实可以用基于“流形假设”的聚类策略,将高维度支付特征映射到分布在流形结构的低维特征上,这样能发现风险支付的某些局部相似特征。而不是仅仅的用把无标签数据都当成风险概率为0.65的trick策略。
3、本次直接把所有特征数据都送入模型进行了训练,然而通过观察数据可以发现实际上有些特征之间相关度比较高,如缺失都是缺失,不缺失则都大致相近。其实可以PCA计算每个特征的权重,选择TopK个权重(根据预先观察),再将选中的TopK个特征送入模型训练,这样可以大大减少噪声,由于没经验,以为给的数据就是完美的,故没做此操作。
4、模型融合,因为时间原因这次仅仅采用了基于不同模型输出的结果文件的平均值策略,其实还可以尝试其他策略,如stacking、voting、weighting等,其实这次也用了stacking思想,即通过sophon里的交叉验证算子,最终嫌弃跑的太慢就放弃了。
5、学习学习,自己懂得还是太少!通过这次比赛,我发现对数据的敏感度需要建立在基础理论知识基础上,否则一切都是假象。这玩意儿就像学物理一样,需要直观感受和理论依据以及科学的计算。
6、星环的可拖拽式人工智能平台Sophon真实666,为她打call,节省了90%的代码量,半小时上排行榜,再也不是梦,哈哈。
总之,答应大家从头直播比赛的事情,今天正式圆满了,大家不要对天池大赛望而生畏啦,各位,加油,英雄榜上风云四起,怎么能少了你!!!