本文主要参考天池同名直播课程。网址为:https://tianchi.aliyun.com/forum/videoStream.html?spm=5176.11510288.4851101.12.31f62042EnWwrg&postsId=5315#postsId=5315。
1 数据读取与导出
1.1 数据读取
上图中,“csv”是文件的后缀,可更换,如:
“sep”用于指定数据分隔符,默认为逗号分隔;
“header=none”表示文件没有头,可以通过df.columns进行指定。


1.2 数据构造
自行构造数据有三种方法,如下三行:
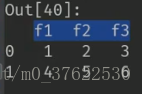
第一种:list构造,如上图中二行三列的数据,后给每一列命名f1, f2, f3。输出结果为:
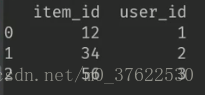
第二种:按列构造(字典dict型),user_id和item_id分别为一列。输出结果为:
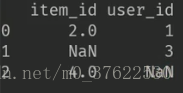
第三种:按行构造,每一列一个字典。输出结果为:

1.3 数据导出
上图中,“csv”是文件的后缀,可更换;“index”为索引;“sep”用于指定数据分隔符,默认为逗号分隔。
2 数据查看
df.describe: 得到数据的统计结果,如下:
df[].value_counts: 查看某一列有几种取值,分别多少个,结果如下:
(四种取值)
df[].unique: 查看某一列有多少不同取值,结果如下:



3 数据选取
以下四种:
第一种:输出结果如下:
也可单独选取一列,如:
或
第二种:也可指定看多少行多少列,如下:
看第0到2行(0已省略),第0列(即user_id那一列)
第三种:选取指定行and列
第四种:对数据进行采样,采样频率为0.5
除了指定采样频率意外,还可以:df.sample(n=):采样时指定采样个数




4 数据整理
4.1 空值处理
对空值进行替换:


4.2 替换


