0.Hadoop
Hadoop是一个开源框架,它允许在整个集群使用简单编程模型计算机的分布式环境存储并处理大数据。它的目的是从单一的服务器到上千台机器的扩展,每一个台机都可以提供本地计算和存储。

大数据学习群:716581014
1.Druid
Druid是实时数据分析存储系统,Java语言中最好的数据库连接池。Druid能够提供强大的监控和扩展功能。
Druid是一个分布式的、面向列的、实时的分析数据存储库,通常用于为多租户环境中的探索性仪表板供电。
Druid作为一种数据仓库解决方案,擅长于对petabyte大小的数据集进行快速聚合查询。Druid支持各种灵活的过滤器、精确计算、近似算法和其他有用的计算。
Druid可以同时加载流数据和批处理数据,并与Samza、Kafka、Storm、SPark和Hadoop集成。
2.Ambari
大数据平台搭建、监控利器;类似的还有CDH
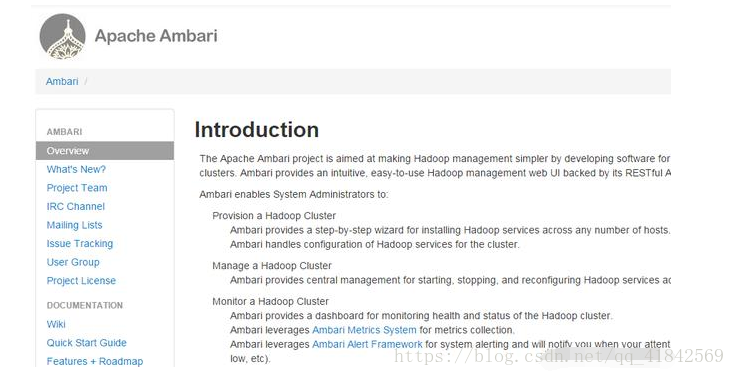
Ambari能够:
提供Hadoop集群
- Ambari为在任意数量的主机上安装Hadoop服务提供了一个逐步向导。
- Ambari处理集群Hadoop服务的配置。
管理Hadoop集群
- Ambari为整个集群提供启动、停止和重新配置Hadoop服务的中央管理。
监视Hadoop集群
- Ambari为监视Hadoop集群的健康状况和状态提供了一个仪表板。
- 安巴里杠杆Ambari度量系统用于度量集合。
- 安巴里杠杆Ambari警报框架用于系统警报,并在需要注意时通知您(例如,节点下降,剩余磁盘空间较低等)。
3.Spark
一个快速通用的集群计算系统.它在Java、Scala、Python和R中提供了高级API,并提供了支持通用执行图的优化引擎。大规模数据处理框架(可以应付企业中常见的三种数据处理场景:复杂的批量数据处理(batch data processing);基于历史数据的交互式查询;基于实时数据流的数据处理,Ceph:Linux分布式文件系统。

4.Storm
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。Storm的部署管理非常简单,而且,在同类的流式计算工具,Storm的性能也是非常出众的。

以上5个大数据处理/数据分析/分布式工具。更多精彩文章,点击文末【了解更多】
最后
为帮助那些往想互联网方向转行想学习,却因为时间不够,资源不足而放弃的人。我搜集整理了一套完整的IT学习资料,包括运营技巧、SEO优化等,比自己在网上零散收集的结构性和连贯性更强,只为帮助那些想学习的人!
在这里相信有许多想要学习大数据的同学,大家可以+下大数据学习裙:716加上【五8一】最后014,即可免费领取一整套系统的大数据学习教程