一般数据会分为两部分:成长集(2/3)和修剪集(1/3)。成长集用于生成规则,修剪集用于调整规则。
1,ripper算法
基本概念:
规则覆盖:若某个实例完全满足某条规则的前件,则规则覆盖该实例。 分类的时候,将规则库中的规则根据添加的先后顺序一一与实例匹配,若匹配成功则实例被预测为正例,若都不匹配则为负例。
RIPPER算法的主框架分为两个部分:生成规则与优化规则。生成规则部分是一个两层的循环,其中外循环每次生成一条规则修剪后添加到规则库,内循环则是每次为规则增加一个前件;优化部分则是根据规则库里的规则构造备选规则,并使用MDL准则挑选出最佳规则加入规则库。
算法细节:
1,准备阶段
首先计算每个类别的先验概率。由于RIPPER算法本身是二分类算法,所以对于多分类的数据集需要根据先验概率的降序转换为二分类问题,每次对先验概率较低的类别建立规则。假设完整的数据集为D,每次对一个类别的数据建立规则并加入到规则库中:如完整数据集的类C1,C2,…Cn先验概率为p1≤p2≤…≤pn,那么首先对C1建立规则,规则建立完成后将其覆盖的数据从D中删除。
2,生成正例规则
输入是数据集D,正例类别C与其先验概率p,注意这里的数据集D是上一次生成规则阶段筛除部分数据后的数据集。首先需要计算的是在默认规则下的描述长度,这个描述长度将作为一个参考值使用,算法生成的规则不应该比默认规则有更长的描述长度。在这个阶段中,将生成若干条规则直到无法继续,这些规则的后件都是类别C,每一条规则的生成都经历增长和剪枝两个阶段,增长阶段从空规则开始,每次增加一个前件;剪枝阶段则从最后一个被添加的前件逆序往前剪枝。首先需要将数据集D分为独立的增长集Grow与修剪集Prune,通常两者的比例控制在2:1。
2.1规则增长阶段
数据集为增长集Grow。规则的增长从空规则开始(任何实例都被空规则覆盖),类似于决策树的建立过程,其每次在所有可能的属性与阈值之间挑选合适的组合作为前件添加到规则之中。度量的标准是信息增益,不同于其他决策树,这里的信息增益并非期望熵的减少,而是来源于信息论里对一个正例编码所需比特的减少。这里的信息增益的准确定义如下:
Gain(antd)=cover⋅(log2rt′−log2rt)
其中cover指规则添加前件antd后覆盖到的正例数量,rt′指添加前件后规则覆盖的数据中的正例比例,rt则是未添加前件的。这里的前件形如attr=θ、attr≤θ、attr≥θ,属性既可以是离散属性也可以是连续属性,每一个出现的属性值都将成为候选阈值。每一次添加前件都需要对所有候选阈值计算其所带来的信息增益并选择最高的一个添加到规则中,每添加一个前件,都需要将其所覆盖的数据从增长集中删去,这就是规则增长阶段的一次循环。同一个离散属性不会被多次添加到一条规则中,譬如不会出现天气=晴,天气=雨这样的情况,逻辑上来看这也是矛盾的;但对于连续属性则是允许的,譬如a≥10,a≤20是合法的。添加前件的循环将持续进行,直到Grow为空(意味着当前规则覆盖了整个原始的增长集Grow),或者余下的Grow中已经没有正例(所有的正例都被覆盖),或者没有更多的候选阈值(规则的前件中囊括了所有的离散属性),或者规则的覆盖率低于某个值(譬如规则只覆盖了寥寥几条数据,根据需要自行设定)。以上便是规则增长阶段,一旦某条规则停止增长,则马上对其进行剪枝。
2.2规则修剪阶段
修剪阶段使用修剪集Prune来检验规则的泛化能力。在这个阶段,从最后一项被添加的前件开始往前依次删去规则的一个前件,计算其在修剪集上的准确率(即被规则覆盖的数据中真正正例的比例)。算法选择准确率最高且前件尽可能少的规则,但该规则的准确率至少要比空规则高。记待修剪的规则R=(a1,a2,…a6),下表展示了修剪的过程:
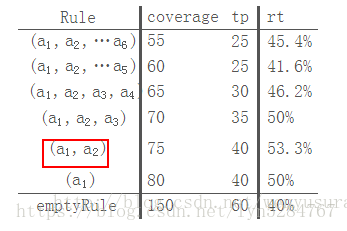
比较得出当规则只有两个前件时准确率最高,因此把前件a3,a4,a5,a6都删除。在某些文献中,剪枝时度量标准是最大化p−np+n,其中p是修剪集中被规则覆盖的正例,n是被规则覆盖的负例,其实两者是等价的,其实质仍是最大化修剪集上的准确率。
一旦规则被剪枝完成,则试图把其添加到规则库中,计算规则库的描述长度并更新最小描述长度。若添加规则后的描述长度比最小描述长度多64位时则停止添加规则,并把刚添加的规则从库中删去。如果规则覆盖的实例数量太少或者准确率过低一样也会导致添加失败。如果规则添加成功,则将其覆盖的实例从D中删去,重新划分Grow与Prune进入规则增长与修剪阶段。直到某个规则添加失败,该循环结束,不再产生新的规则,而是进入优化阶段。
3优化阶段
此时针对阶段2生成的规则库进行优化,通过构造备选规则,算法对规则库里的每条规则都进行优化。类似于阶段2,此阶段使用的也是数据集D,且每优化一条规则都需要将最终规则覆盖的实例从D中删去然后优化下一条规则直到所有规则都被优化。规则优化的顺序同生成阶段规则添加的顺序。
优化规则R
首先仍然是数据集D划分为Grow与Prune,策略与阶段2并没有什么不同。对于规则R,首先检测其在数据集D中的覆盖率,如果没有实例被覆盖那就没有优化的必要了。规则的优化通过构造额外两个备选规则实现,算法取三者中描述长度较小的规则。
备选规则一:仍然是从空规则开始,利用Grow生成规则并剪枝,但这里并不是直接使用Prune作为剪枝集,剪枝时的度量标准亦有所变化。对于Prune中的每个实例,如果其被规则库中R以后的任意规则覆盖,那么将其从Prune中删除。换言之,当针对规则Ri构造备选规则时,Prune中的任意实例都不能被规则Ri+1,Ri+2,…覆盖。其次,剪枝时需要计算的是规则在整个修剪集上的准确率而不是被覆盖的数据中的准确率(在阶段2的修剪阶段,计算的是tptp+fp,在这里计算的是tp+tntotal)。剪枝完成后的规则即是备选规则一。
备选规则二:此时从规则R开始继续添加前件并剪枝。首先对于Grow,筛选出其中所有被R覆盖的实例作为增长集,然后使用2.1中的方法继续往R添加前件直到无法继续增长。然后使用Prune剪枝,使用的是整个修剪集上的准确率。注意与备选规则一的异同,两者分别从空规则、原规则开始增长,增长集也不一样;而在剪枝部分,备选规则一对修剪集有一个预处理的过程,两者使用的都是整个修剪集上的准确率。
接下来便是将三者分别放入规则库中比较描述长度了,取最短者作为最终采纳的规则,然后更新数据集D并取下一条规则进行优化。在优化阶段,所有的规则都需要经过构造备选规则的优化,而整个优化阶段亦重复数次。到这里,针对某一类别建立的规则库便已确定了,若是多分类的话便更新最外层的数据集D(阶段1所提到的),将规则库覆盖的实例从中删去,然后挑选下一个类别,从阶段2重新开始构建规则并优化。因此在多分类问题中,根据先验概率的大小,每个类别都会生成一个规则库,它们与一条空规则(前件为空,后件为先验最大的类别)共同组成算法最终生成的规则库。
4总结
RIPPER算法由于不需要事先建立完整决策树,因此效率比C4.5等要高,复杂度为ο(Nlog2N),并且可以使用很大的数据集2,同时在算法效果上,其不亚于C4.5生成的规则。另,算法的一个具体实现可以参考Weka中的JRip算法。