注:本节中的部分知识及图片参考《信息存储与IT管理》一书
一块磁盘的容量是有限的,速度也是有限的。对于一些应用来说,可能需要几百GB甚至TB大小的分区来存放数据。那么必须要制造单盘容量更大的硬盘来满足需求吗?为了解决这个问题,人们发明了RAID技术,即Redundant Array of Independent Disk技术,中文的意思是独立的磁盘组成的具有冗余特性的阵列,既然是阵列,那一定需要很多磁盘来组成;既然具有冗余特性,那一定可以允许某块磁盘损坏之后,数据仍然可用。下面我们就来看一下RAID是怎么样炼成的。
4.1 大话七种RAID武器
RAID技术经过不断地发展,现在已经有了从RAID0~RAID6这7种基本的RAID级别。另外,还有一些基本RAID级别的组合,例如RAID10(RAID-1和RAID0的组合)、RAID-50(RAID-5和RAID-0的组合)等。不同的RAID级别代表不同的存储性能、数据安全性和存储成本。在本书里,对RAID的级别的分类,称之为“阵式”,将七个阵式联合称之为“北斗七星阵”,也蛮有意思的。
4.1.1 RAID 0阵式
在了解RAID技术之前,首先需要熟知磁盘的磁性区域构造,包括磁道、磁头、扇区和柱面等知识,这些有利于理解这个技术。在书中的“七星大侠”看来,盘片就像一个蜂窝,上面的每一个孔都是一个扇区,可以说他已经参透了磁盘。
如果你有几块硬盘,需要去存储大量的内容。第一种最简单的方式就是累加,从第一块磁盘开始写入,等到第一块磁盘写满之后,再写入第二块磁盘。但是这种方式每次IO只用到了一块磁盘,另一块磁盘没有动作,效率较低,但是多个磁盘累加,确实容量要大于一块磁盘。第二种就是分割了,其实磁盘已经通过扇区分割开了,只是每一个扇区只有512B大小。但是这种分割成粒太小了,不仅开销太大,而且组合起来也很困难。但是又不能丢弃磁盘已经分割好的扇区,所以就使用条带化(Stripe)技术,实现原理如下图:

图左所示的是4块普通硬盘,其上布满了扇区。扇区是实实在在存在于盘片上的,具有自己的格式。图右所示的是引入分割思想(条带化)之后的硬盘。由于许多文件系统或者卷管理软件都使用块而不是扇区作为基本存储单元,所以图4-2中使用4个扇区组成的块作为基本单元。不同磁带的相同偏移处的块组合成Stripe,也就是条带。块的编号也就是以横向条带方向开始一条一条的向下。这样,对于一个全新的文件系统和RAID 0磁盘组,如果有大块的数据写入时,则数据很大概率上可以以条带为单位写入。也就是说数据被分为多块同时写入4个硬盘,而不是单硬盘系统中的顺序写入一个个硬盘,这就大大的提高了速度。RAID 0的原理就是将多个物理磁盘合并成一个大的逻辑磁盘,它代表了所有RAID级别中最高的存储性能,不具有冗余,不能并行IO,但速度最快。在存放数据时,根据构建RAID 0的磁盘个数对数据进行分段,然后同时将这些数据并行写进磁盘。
也可以按照《信息存储与IT管理》中举的例子,如下图所示:
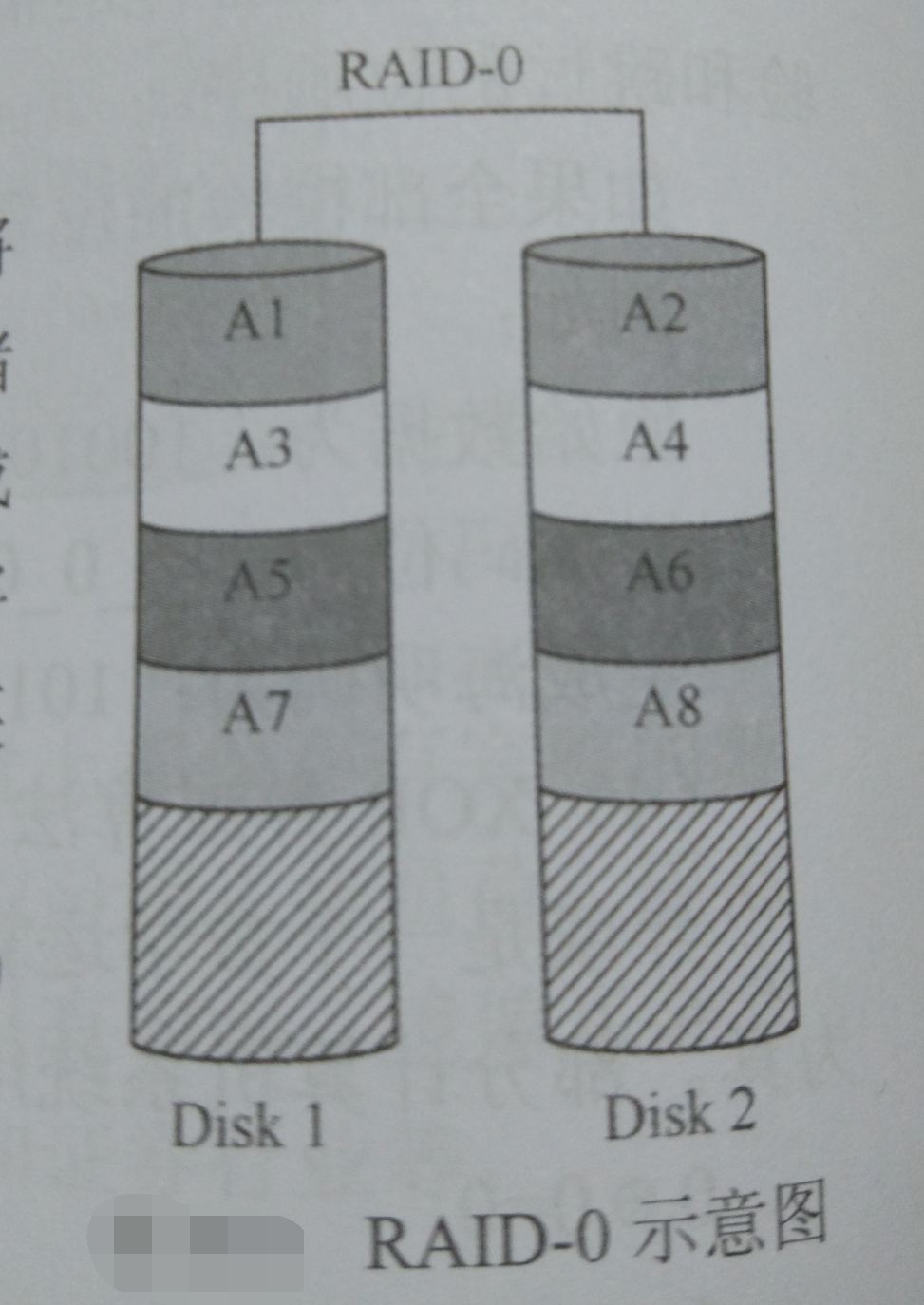
如上图所示,RAID-0的做法是将要存储的内容(A1,A2,...)根据磁盘数目分为两部分同时存储。A1和A2分别存储在Disk1和Disk2中,等到A1存储完成后,开始将A3存储进Disk1中。其余数据块同理。这样就是将两个磁盘看作一个大磁盘,并且两侧同时进行IO。不过如果某块数据坏掉,整个数据就会丢失。
从理论上讲,RAID-0磁盘个数和总磁盘性能应该成倍数关系,总磁盘性能等于“单一磁盘性能X磁盘数”。但实际上受限于总线IO瓶颈及其他因素的影响,RAID性能岁磁盘个数的增加不再是倍数关系,也就是说,假设一个磁盘的性能是50MB/S,两个磁盘的RAID-0性能约为96MB/S,3个磁盘的RAID-0性能也许是130MB/S而不是150MB/S,所以两个磁盘的RAID-0最能感受到性能的提示。
RAID-0的读写性能较好,但是没有数据冗余,因此RAID-0本身适用于对数据访问具有容错力的应用,以及能够通过其他途径重新形成数据的应用,如Web应用以及流媒体。
4.1.2 RAID 1阵式
RAID-1又称为Mirror或Mirroring(镜像),它的目的是最大限度的保证用户数据的可用性和可修复性。RAID-1的原理就是把用户写入硬盘的数据百分之百地自动复制到另一个硬盘上。RAID-1在主硬盘上存放数据的同时也在镜像磁盘上写同样的数据。当主硬盘损坏时,镜像硬盘代替主硬盘的工作。因为有镜像磁硬盘做数据备份,所以RAID-1的数据安全性是所有RAID级别中最好的。但是无论用多少磁盘做RAID-1,有效数据空间大小仅为单个磁盘容量,是所有RAID上磁盘利用率最低的一个级别。
RAID-1实现原理如下:

上图中,在存储数据时,将要存储的内容(A1,A2,...)存储进主磁盘Disk1,同时在Disk2中再次将数据存储一遍,以达到数据备份的目的。
RAID-1提供的最大容量是所有组成RAID-1的磁盘中容量最小的一块,剩余容量不再被使用,而且写性能等于所有磁盘中性能最低的那块磁盘的写性能。RAID-1是所有RAID级别中单位存储成本最高的,但因其提供了几乎最高的数据安全性和可用性,所以RAID-1适用于读操作密集的OLTP和其他要求数据具有较高读写性能和可靠性的应用,如电子邮件、操作系统、应用程序文件和随机存取环境等。
4.1.3 RAID 2阵式
RAID-2融合了RAID-0的写数据方式,但是在数据安全性校验方面采用了汉明码(Hanmming Code)的方式。汉明码的设计使得接受方可以判断到底是哪一位出错了,并且能修正一位错误,但是如果有两位都错了,那么就不能修正了。
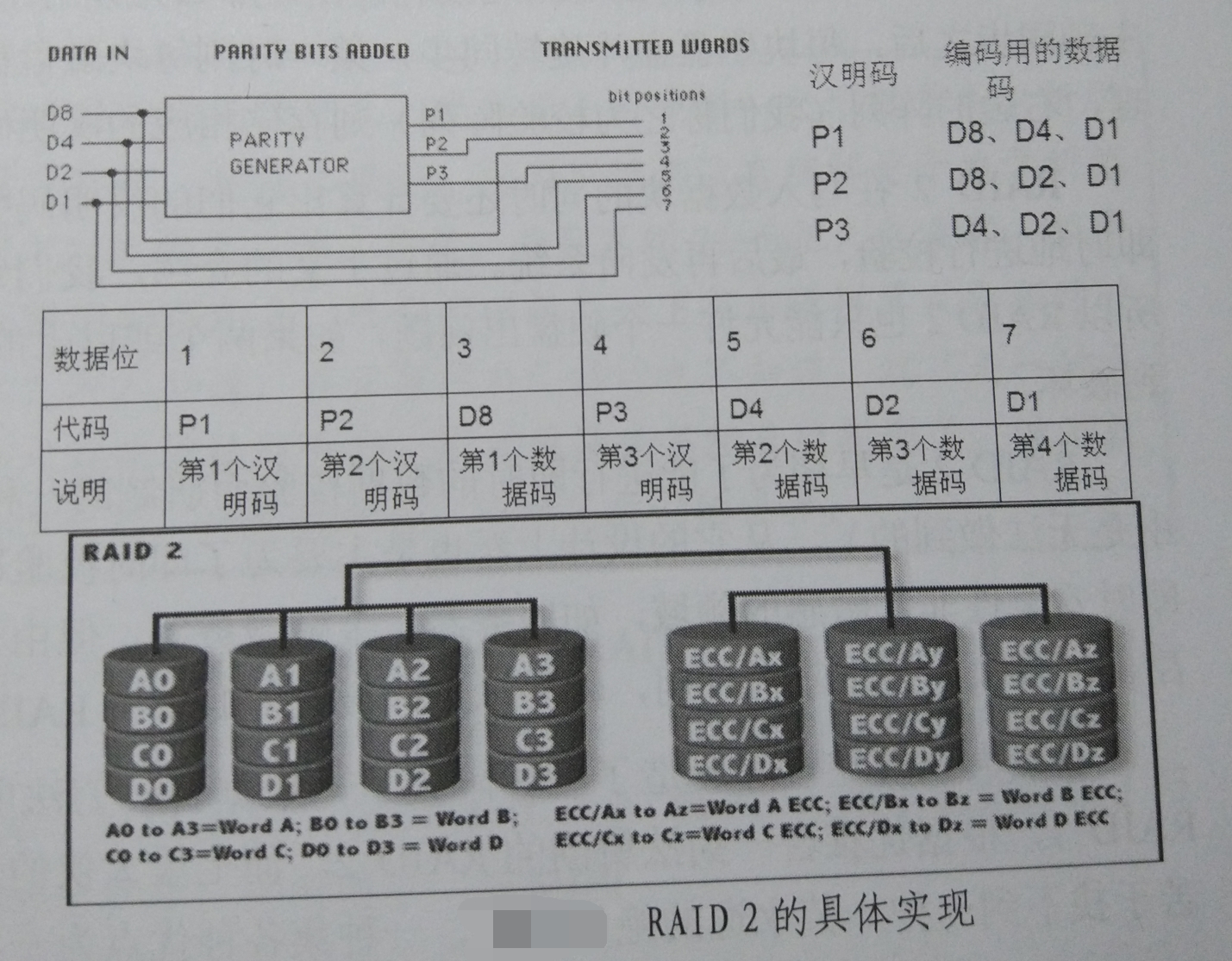
汉明码在原有的数据为中插入一定数量的校验码来进行错误检测和纠错。比如对于一组4位数据编码为例,汉明码会在这四位中加入3位校验位,使得实际传输的数据位达到7位,位置如上图所示。需要被插入的汉明码的位数与数据位的数量之间的关系为2P≥P+D+1,其中P代表汉明码的个数,D代表数据位的个数。所以7位数据时就需要3位汉明码(24≥4+7+1)。
在RAID-2中,每个IO下发的数据被以位为单位平均打散在所有数据盘上。如上图所示,左边的为数据盘阵列,如果某时刻有一个4KB的IO下发给这个RAID-2系统,则这4KB中的第1、5、9、13等位将会被存放在第一块数据盘的一个扇区中,第2、6、10、14等位被存放在第二个磁盘对应条带的扇区,以此类推。这样数据强行打散在所有磁盘上,迫使每次IO都要全组联动来存取,所以此时要求各磁盘主轴同步,才能达到最佳效果。因为如果某时刻只读出了一个IO的某些扇区,另一些扇区还没读出来,那么先读出来的数据都要等待,这就造成了瓶颈。主轴同步后,每块磁盘盘片旋转同步,某一时刻每块磁盘都旋转到同一个扇区偏移的上方,同理,右边的阵列(称之为校验阵列)则存储相应的汉明码。RAID-2在写入数据块的同时,还要计算它们的汉明码并写入校验阵列,读取时也要对数据即时的进行校验,最后再发回系统。因为汉明码只能纠正一个位的错误,所以RAID-2也只能允许一个硬盘出错,如果两个及以上的硬盘出问题,RAID-2的数据就会遭受到破坏。
RAID-2是早期为了能够进行即时的数据校验的一种技术,从设计上看也是为了即时校验以保证数据的安全,针对了当时对数据的即时安全性非常敏感的领域,如服务器、金融服务等。但由于校验盘数量太多、开销太大及成本昂贵,目前已基本不再使用,转而以更高级别的即时检验RAID所代替,如RAID3、5等。
4.1.4 RAID 3阵式
布尔运算中有一个XOR运算,即1 XOR 0 = 1,1 XOR 1 = 0,0 XOR 0 = 0。这其中有一些规律:
1 XOR 0 XOR 1 = 0
0 XOR 1 XOR 0 = 1
假如第一个式子中的0被遮盖,完全可以从结果推出这个被掩盖的逻辑数字。不管等式左边有多少位进行运算,等式的右边结果只会有一位,而且都可以推出这个被遮盖的一位数字。
那么按照布尔运算的规律,在RAID-2中用于校验的冗余的几块校验盘,在RAID-3中只需要一块来存放数据恢复的校验码就可以了。按照布尔的思想,数据盘的每一位之间做XOR运算,然后将结果写入校验盘的对应位置。这样,任何一块数据盘损坏,或者其中的任何一个扇区损坏,都可以通过剩余的位和校验位一同进行XOR运算,而运算的结果就是这个丢失的位。8位一起校验可以找出一个丢失的字节,512字节一起校验就可以找到一个丢失的扇区。RAID-3仍旧保持了RAID-2的思想,也就是对一个IO尽量做到能够分割成小块,让每个磁盘都能够得到存放这些小块的机会。这样多磁盘同时工作,性能高。所以RAID-3中把一个条带做成4KB这个魔术值(因为一般的文件系统常用4KB为一个块,如果4块数据盘,则条带深度为两个扇区或者1KB,如果8个数据盘,则条带深度为1个数据盘或512B),这样每次IO就会牵动所有磁盘并行读写。所以,在IO块大于Block SIZE的时候,RAID2和RAID3都是每次只能做一次IO,不适用于IO并发的情况,因为会造成IO等待。RAID-3的并发只是一次IO的多磁盘并发存取,而不是多个IO并发。所以和RAID2一样,适用于IO块大、IO SIZE/IOPS比值大的情况。RAID-3在极端优化的情况下也可以做到IO并发。控制器向一块磁盘发送的读写指令,其中包含一个所要读取扇区的长度,如果下一次IO与本次IO在物理上是连续的(连续IO),此时如果控制器做了极端的优化,则可以将这两个IO合并,向磁盘发送的每个IO指令中包含了两次上层IO的数据,这样也算是一种并发IO。
RAID3相比于RAID2校验效率提升,成本减少(使用磁盘更少)。缺点是不支持错误纠正,因为XOR算法无法纠正错误。但是发生错误的机会少之又少,完全可以靠上层来处理错误。RAID3和RAID2一样,要达到RAID3的最佳性能,需要所有磁盘的主轴同步,也就是说,对于一块数据,所有磁盘最好同时旋转到这个数据所在的位置,然后所有磁盘同步读出来。不然一旦有磁盘和其他盘不同步,就会造成等待,所以只有主轴同步才能发挥最大的性能。
磁盘读写又分为连续读写和随机读写。连续读是指每个IO所需要提取的数据块在序号上是连续的,磁头不必花太多时间来寻道,所以这种情况下寻道消耗的时间就很短。我们知道,一个IO所用的时间约等于寻道时间加上旋转延迟时间再加上数据传输时间。IOPS = 1/(寻道时间+旋转延迟时间+数据传输时间),由于寻道时间相对于传输时间要大于几个数量级,所以影响IOPS的关键因素就是寻道时间。而在连续IO的情况下,仅在换磁道时需要寻道,而磁道都是相邻的,所以,寻道时间也足够短。在这个前提下,传输时间这个分母就显示出作用了。由于RAID-3将每一个IO都平摊到N个数据盘上,所以数据传输时间是单盘的1/N,从而在连续IO的情况下,大大增加了IOPS。而磁盘总体传输速率约等于IOPS乘IO SIZE。不管IO SIZE多大,RAID-3的持续读性能几乎就是单盘的N倍。持续写也是同样的道理,必定分摊到所有的数据盘,那么寻道时间足够短的情况下,写的时间也是单盘的1/N,因此持续写的速率也是单盘的N倍。对于RAID3来说,所有的盘都是热点盘,数据盘、校验盘,每次IO必定牵动所有的盘。文件系统的一次IO呗分割到所有的盘,只要这个IO是写的动作,那么物理磁盘上对应的分块,就必定全部被重写,包括校验块。数据在一次写入之前,控制器就会计算好校验块,然后数据块和校验块同时写入磁盘。
再看RAID3的随机读写。所谓随机IO,即每次IO的数据块是分布在磁盘的各个位置,这些位置是不连续的,或者连续几率很小。这样,磁头就必须不断地换道,换道操作时磁盘操作中最慢的环节。根据公式IOPS = 1/(换道时间+数据传输时间),随机IO的时候换道时间很大,大出传输时间几个数量级,及时传输时间翻10倍也不急换道时间的影响大,所以此时可以忽略传输时间的增加效应。由于一次IO被同样分割到了所有数据盘,那么多块盘同时换道,然后同时传输各自的那个分块,换道时间就约等于单盘。其传输时间是单盘的1/N,而传输时间带来的增效可以忽略。所以对于随机读写的性能,RAID3并没有提升,和单盘一样,甚至不及单盘。因为有时候磁盘不是严格的主轴同步,换道慢的磁盘会拖累其他磁盘。
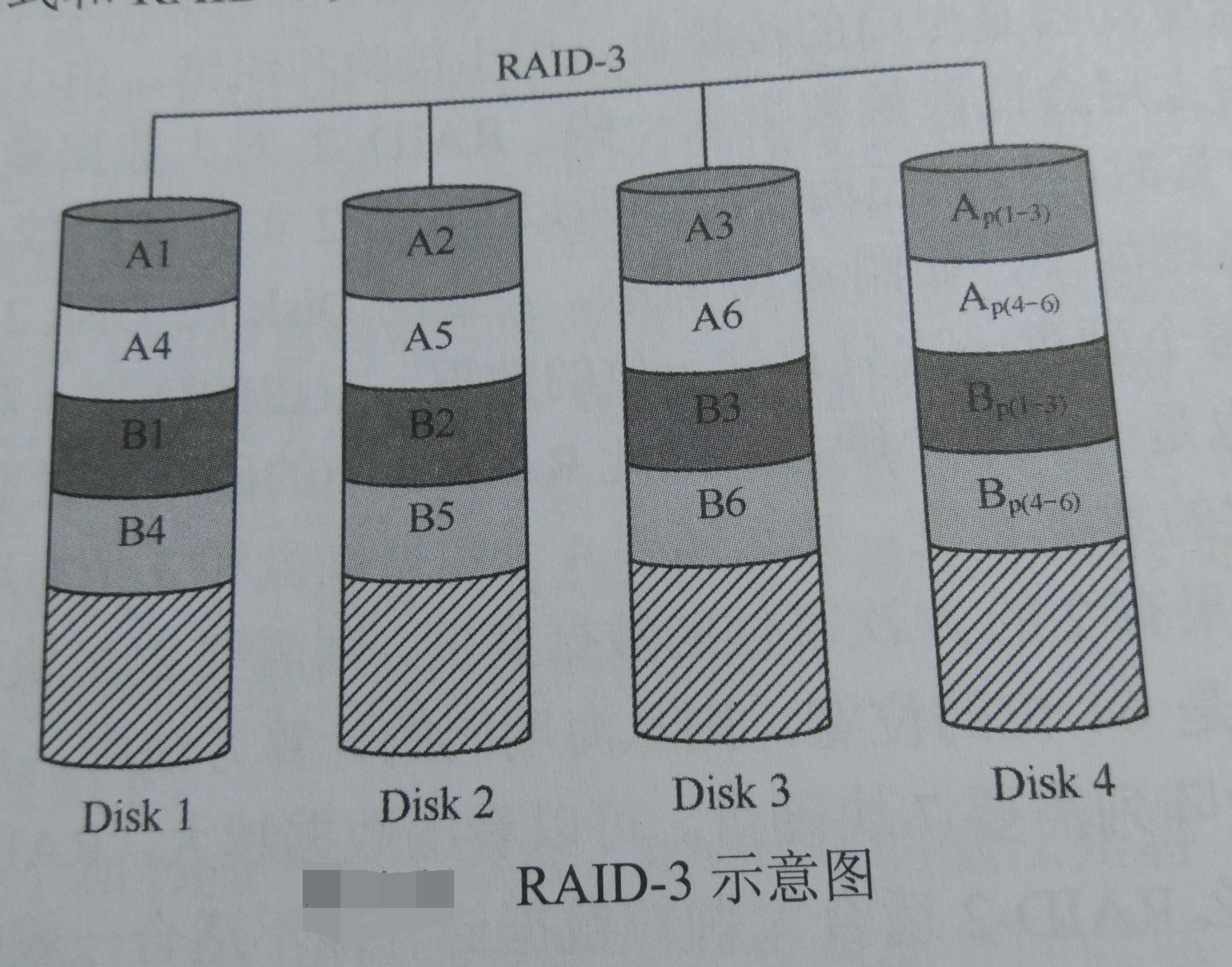
4.1.5 RAID 4阵式
RAID3的设计思想就是一次IO尽量让每块磁盘都参与,而控制器的一次IO的数据块不会很大,那么想让每块磁盘都参与这个IO,就只能认为的减小条带深度的大小。事实证明这种IO设计在IOSIZE/IOPS(比值)很大的时候,确实效果显著。但是在现实应用中,很多应用的IOSIZE/IOPS都很小,比如随机小块读写等,这种应用每秒产生的IO数目很大,但是每个IO所请求的数据长度却很短。如果所有磁盘同一时刻能被一个IO占用着,切不能并发IO,只能一个IO一个IO的来做,由于IO长度小,此时全盘联动来传输这个IO,得不偿失,还不如让这个IO的数据直接写入一块磁盘,空余的磁盘就可以做其他IO了。
要实现并发IO,就需要保证有空闲的磁盘未被IO占用,以便其他IO去占用磁盘进行访问。唯一可以实现这个目的的方法就是增大条带深度,控制器的一个IO过来,如果这个IO块小于条带深度,那么这次IO就完全“禁锢”在一块磁盘上,直接写入了一个磁盘的Segment中,这个过程只用到了一个磁盘。而其他IO也可以和这个IO同时进行,前提是其他IO的目标不是这个IO要写入或读取的磁盘。所以实现IO并发还需要增大数据的随机分布性,而不要连续在一个磁盘上分布。RAID4就是讲RAID3进行了简单的改造,加大了条带深度。
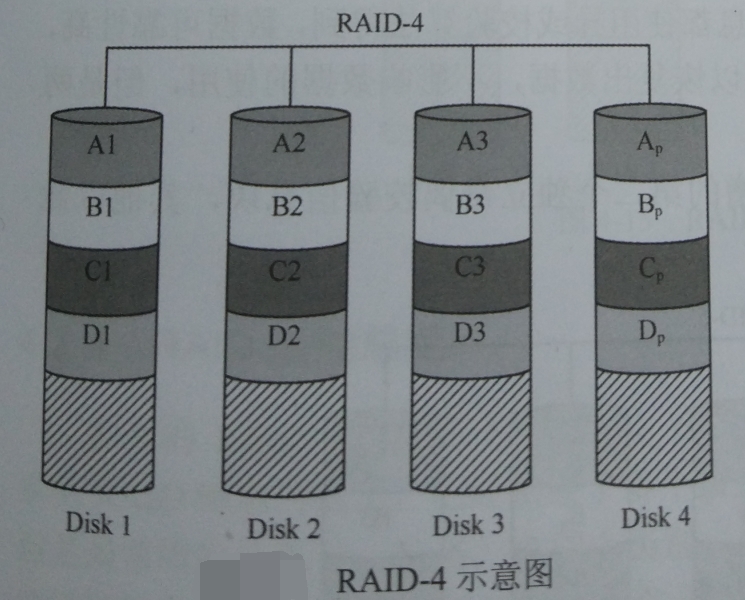
4.1.6 RAID5阵式
RADI-4虽然在设计时考虑到了随机小块读写的情况,但是在实际应用中,却发现不管IOSIZE/IOPS的值是多少,好像性能对于RAID-3并没有什么提升。每个IO写操作必须占用校验盘,校验盘每一个时刻总是被一个IO占用,因为写数据盘的时候,同时也要读写校验盘上的校验码。所以每个写IO不管占用了哪块数据盘,校验盘它是必须占用的,这样校验盘就成为了瓶颈,而且每个写入IO都会拖累校验盘,使得校验盘没有休息的时间,成了“热点盘”,非常容易损坏。
没有引入校验功能,数据盘可以被写IO并发,引入了校验功能之后,数据盘还可以并发,但是校验盘不可以并发,所以整体上还是不能并发。那么既然数据盘可以并发,那么把校验盘打散,分布在数据盘上不就可以并发了吗?多个IO可以同时访问多块数据盘,而校验盘又被打散在各个数据盘上,那么就意味着多IO可以同时访问校验盘(的“残体”)。这样就大大增加了多IO并发的几率,纵使发生多个IO所要用到的校验盘的“残体”可能在同一块数据盘上,这样还是可以IO排队等待的。
如果数据盘足够多,校验盘打散的部分就会分布得足够广泛,多IO并发的几率就会显著增大!由于2块盘的RAID-5系统,对于写操作来说不能并发IO,因为一个IO访问其中一块盘的数据时,校验信息一定在另一块盘,必定也要同时访问另一块盘。同样, 3块盘的RAID-5系统也不能并发IO,最低可以并发IO的RAID-5系统需要4块盘,而此时最多可以并发两个IO,可以计算出并发几率为0.0322(此处的3块盘也不能并发的原因见http://forum.huawei.com/enterprise/zh/thread-439657-1-1.html,几率的计算还未见到分享)。更多的磁盘数量的RAID-5系统的并发几率将会更高。下图为四块盘的RAID-5系统:
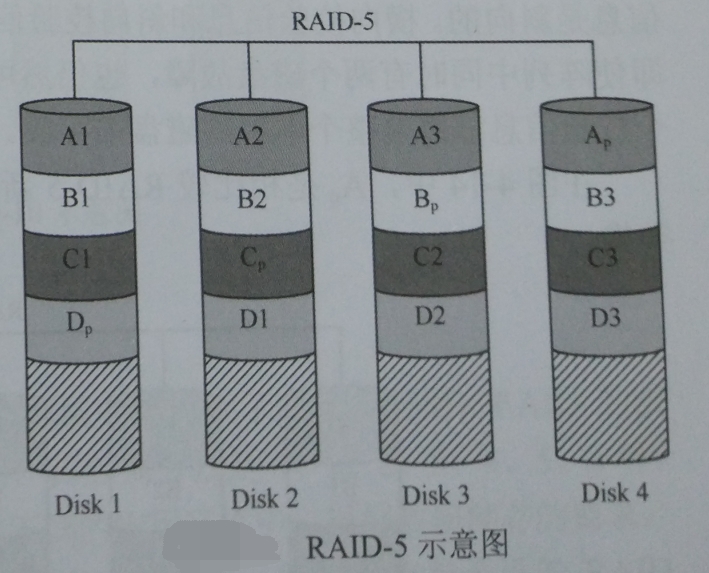
RAID-5也是采用了和RAID-4一样的数据存储方式,也是采用了奇偶校验来进行校验和纠错,可以实现并发IO,但是比RAID-1更加划算,比RAID-0更加安全。RAID-5浪费的资源,在两块盘的情况下与RAID-1是一样的,都是二分之一,但是随着磁盘数量的增加,RAID-5浪费的磁盘为N分之一,但是RAID-1一直是二分之一。
在连续读写方面,RAID-5的性能不如RAID-3.RAID-3由于条带深度很小,每次IO总是能够牵动所有磁盘为他服务,对于大块连续数据的读写速度很快。但是RAID-5的条带深度比较大,每次IO一般只使用一块数据盘,而且通用的RAID-5系统一般被设计为数据块先放慢一个Segment,再去下一个磁盘的Segment,块编号横向进行。RAID-5在随机读方面是首屈一指的,这要归功于多IO并发的实现。也就是说,RAID-3在IOSIZE值大的时候具有高性能,RAID-5在随机IOPS大的时候具有高性能。
RAID-5的一大缺点就是写性能差。根本原因在于每写一个扇区的数据就要产生其校验扇区,一并写入校验盘。尤其是更改数据时,这种效应尤其严重。
因为RAID-5可以在一块磁盘损坏后,继续使用,但是此时如果再坏一块硬盘,就不能工作了。所以针对这一缺陷,又出现了RAID 5E和RAID 5EE阵式。RAID-5E是在原来的每个磁盘预留一部分空间作为热备盘,而且不做横向切割。RAID-5EE是将热备份盘也和校验盘一样,横分竖割融合到数据盘中。
4.1.7 RAID 6阵式
RAID-6是为了进一步加强数据保护而设计的,与RAID-5相比,RAID-6增加了第二种独立的奇偶校验信息块。这样一来,等于每个数据块有了两个校验屏障(一个分层校验,一个是总体校验),因此RAID-6的数据冗余性能非常好。但是,由于增加了一个校验,所以写入的效率较RAID-5还差,而且控制系统的设计也更为复杂,第二块的校验区也减少了有效存储空间。常见的RAID-6技术有P+Q和DP,两种技术获取校验信息的方法不同,但是都可以允许整个阵列有两块磁盘数据丢失。
P+Q:P+Q需要计算出两个校验数据P和Q,当有两个数据丢失时,根据P和Q恢复出丢失的数据。校验数据P和Q是由以下公式得来的。
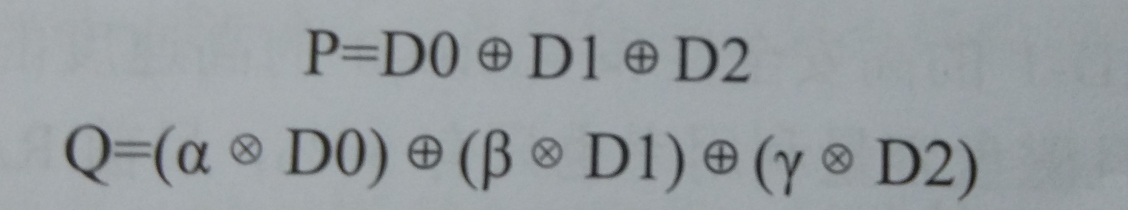
在P+Q中,P和Q是两个相互相互独立的校验值,它们的计算互不影响,都是由同一条带上其他数据盘上的数据依据不同的算法计算而来的。
DP:两次奇偶校验(double parity,DP)就是在RAID-4使用的一个行XOR校验磁盘的基础上又增加了一个磁盘用于存放斜向的XOR信息。DP同样也有两个相互独立的校验信息块,但是与P+Q不同的是,它的第二次校验信息是斜向的。横向校验信息与斜向校验信息都是使用异或校验算法得到的,数据可靠性高,即使阵列中同时有两个磁盘故障,也仍然可以恢复出数据,不影响数据的使用,但是两个校验信息都需要整个单独的磁盘来存放。
下图是RAID-6阵列的示意图,
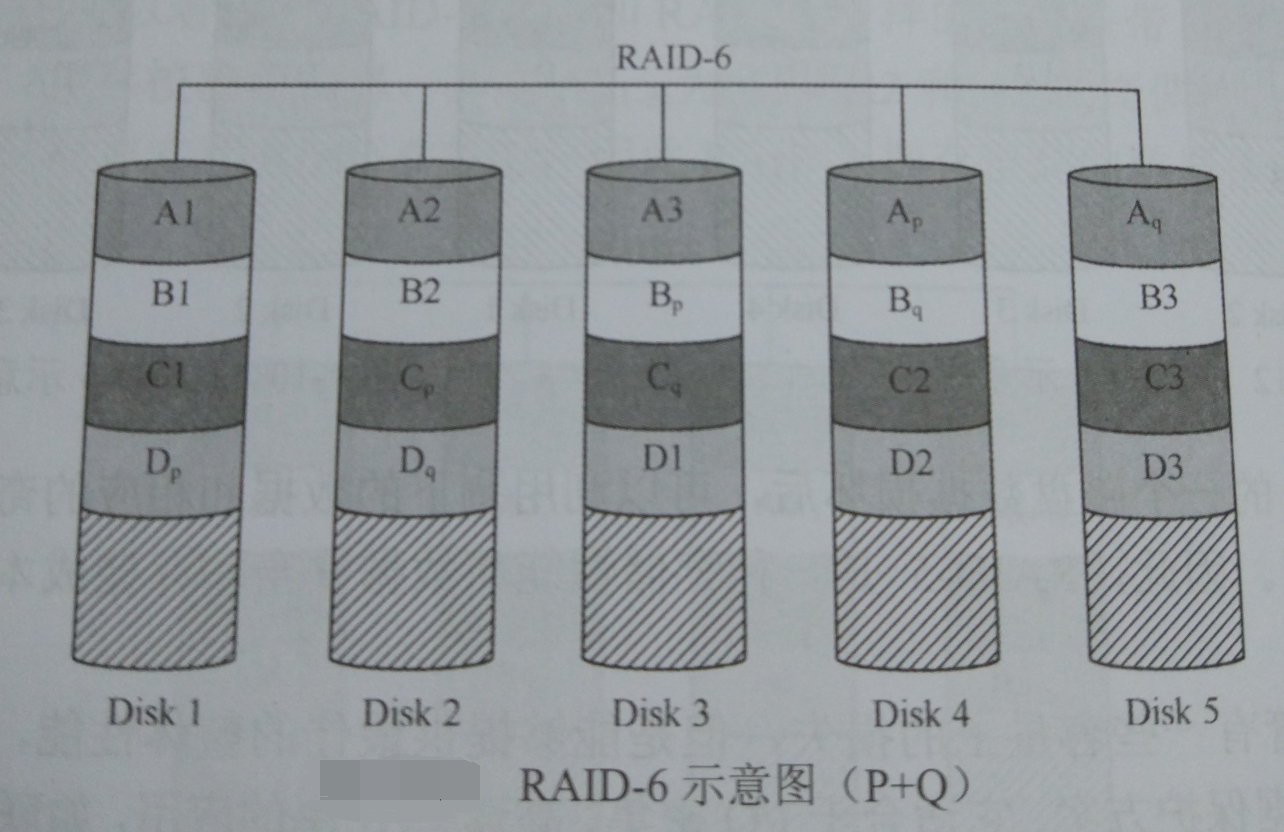
RAID-6的数据安全性比RAID-5高,即使阵列中有两个磁盘故障,阵列依然能够继续工作并恢复故障磁盘的数据。但是控制器的设计较为复杂,写入速度不是很高,而且计算校验信息和验证数据正确性所花的时间也比较多,当对每个数据块进行写操作时,都要进行两次独立的校验计算,系统负载较重,而且磁盘利用率相对RAID-5低一些,配置更为复杂,适合用于对数据准确性和完整性要求更高的环境中。