一. 知识点补充
1. 列表和字典不能在循环过程中进行增删操作,因为列表索引在循环过程会发生改变,字典规定循环不可改变.
删除方法: 将需要大量删除的列表或者字典遍历取出要删除的对象,放入一个空列表,之后对列表进行循环遍历,删除原列表或字典.
2. fromkeys(' a ', ' b ')不会对原来的字典产生影响. 产生新字典(将a迭代变成字典的key, b为每个key的vlaue)
dic = {"a":"123"}
dic.fromkeys("救世主", "暗帝" ) # 返回给你一个新字典
print(dic)
#输出结果: {'a': '123'}
dic = {"a":"123"}
a = dic.fromkeys("救世主", "暗帝" ) # 返回给你一个新字典
print(a)
#输出结果: {'救': '暗帝', '世': '暗帝', '主': '暗帝'}
二. set集合: 是一个无序且不重复的元素集合
1. 集合对象是一组无序排列的可哈希的值,集合成员可以做字典中的键。
集合支持用in和not in操作符检查成员,由len()内建函数得到集合的基数(大小), 用 for 循环迭代集合的成员。
但是因为集合本身是无序的,不可以为集合创建索引或执行切片(slice)操作,也没有键(keys)可用来获取集合中元素的值.
2. 创建空集合时,只能用set(),如果用第二种方法s={},创建的实际上是一个空字典
s = {} print(type(s)) #输出结果: <class 'dict'> a=set('boy') b=set(['y', 'b', 'o','o']) c=set({"k1":'v1','k2':'v2'}) d={'k1','k2','k2'} e={('k1', 'k2','k2')} print(a,type(a)) print(b,type(b)) print(c,type(c)) print(d,type(d)) print(e,type(e)) #执行结果如下: #{'o', 'b', 'y'} <class 'set'> #{'o', 'b', 'y'} <class 'set'> #{'k1', 'k2'} <class 'set'> #{'k1', 'k2'} <class 'set'> #{('k1', 'k2', 'k2')} <class 'set'>
3. 增加
a=set('python') a.add('tina') print(a) b=set('python') b.update('tina') print(b) #执行结果如下: #{'tina', 'o', 'p', 'n', 't', 'y', 'h'} #{'o', 'i', 'p', 'a', 'n', 't', 'y', 'h'} #由以上代码可以看出,add是单个元素的添加,而update是批量的添加。输#出结果是无序的,并非添加到尾部。
4.删除(remove,discard,pop)
c={'p', 'i', 'h', 'n', 'o', 'y', 't'}
c.remove('p')
print(c)
#输出结果: c={'p', 'i', 'h', 'n', 'o', 'y', 't'}
c.discard('p')
print(c)
#输出结果: c={'p', 'i', 'h', 'n', 'o', 'y', 't'}
c.pop()
print(c)
#输出结果: 执行结果如下: {'i', 'h', 't', 'o', 'y', 'n'}
#当执行c.remove('p','i')和c.discard('p','i')时,报错:TypeError: #remove() takes exactly one argument (2 given),
#说明remove和discard删除元素时都只能一个一个的删,同add对应。
#remove,pop和discard的区别:
#discard删除指定元素,当指定元素不存在时,不报错;
#remove删除指定元素,但当指定元素不存在时,报错:KeyError。
#pop删除任意元素,并可将移除的元素赋值给一个变量,不能指定元素移#除。
5. 清空
c={'p', 'i', 'h', 'n', 'o', 'y', 't'}
c.clear()
print(c)
#执行结果如下:
#set()
三. 深浅拷贝
1. 赋值
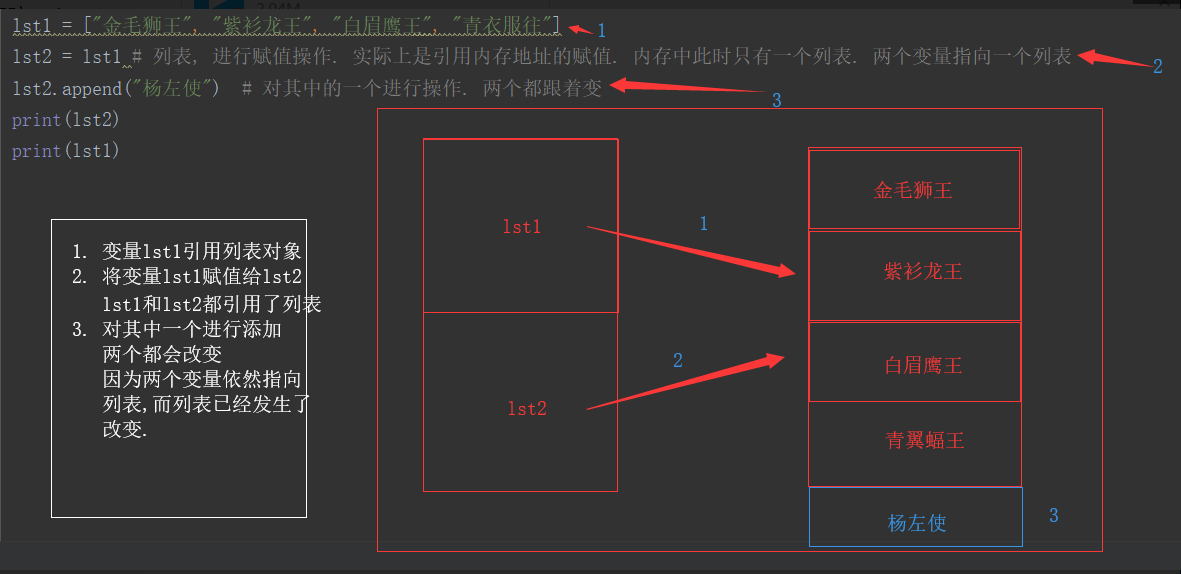
lst1 = ["金毛狮王", "紫衫龙王", "白眉鹰王", "青衣服往"] lst2 = lst1 # 列表, 进行赋值操作. 实际上是引用内存地址的赋值. 内存中此时只有一个列表. 两个变量指向一个列表 lst2.append("杨左使") # 对其中的一个进行操作. 两个都跟着变 print(lst2) print(lst1) #输出结果: ['金毛狮王', '紫衫龙王', '白眉鹰王', '青衣服往', '杨左使'] # ['金毛狮王', '紫衫龙王', '白眉鹰王', '青衣服往', '杨左使']
2. 浅拷贝
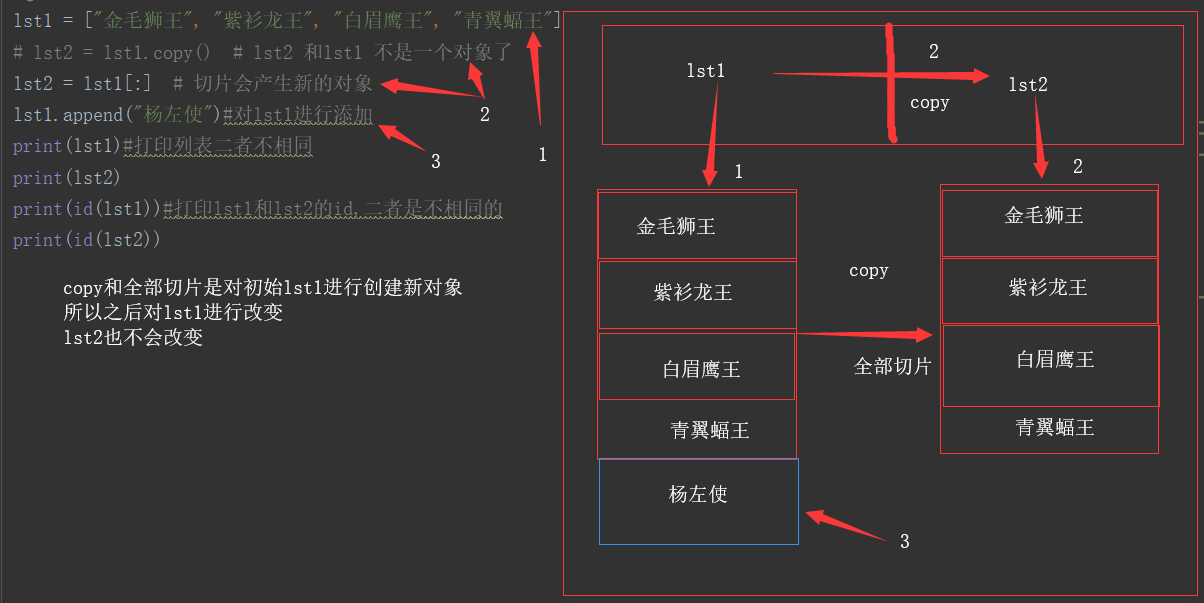
lst1 = ["金毛狮王", "紫衫龙王", "白眉鹰王", "青翼蝠王"] # lst2 = lst1.copy() # lst2 和lst1 不是一个对象了 lst2 = lst1[:] # 切片会产生新的对象 lst1.append("杨左使")#对lst1进行添加 print(lst1)#打印列表二者不相同 print(lst2) print(id(lst1))#打印lst1和lst2的id,二者是不相同的 print(id(lst2)) #输出结果:['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王', '杨左使'] # ['金毛狮王', '紫衫龙王', '白眉鹰王', '青翼蝠王'] # 331794792563784 # 1794792563848
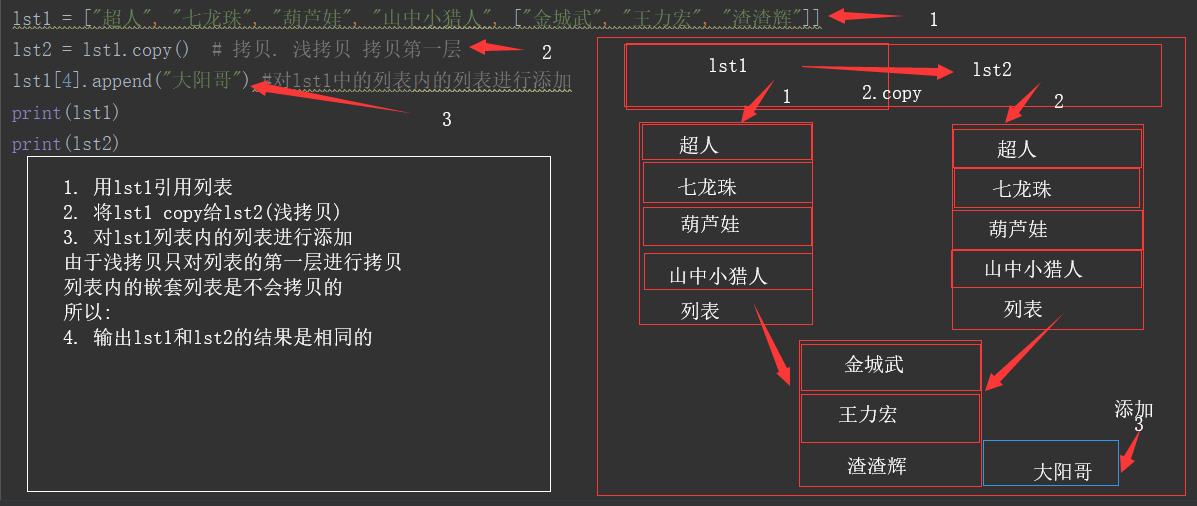
lst1 = ["超人", "七龙珠", "葫芦娃", "山中小猎人", ["金城武", "王力宏", "渣渣辉"]] lst2 = lst1.copy() # 拷贝. 浅拷贝 拷贝第一层 lst1[4].append("大阳哥") #对lst1中的列表内的列表进行添加 print(lst1) print(lst2) #输出结果: #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']] #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']]
3. 深拷贝
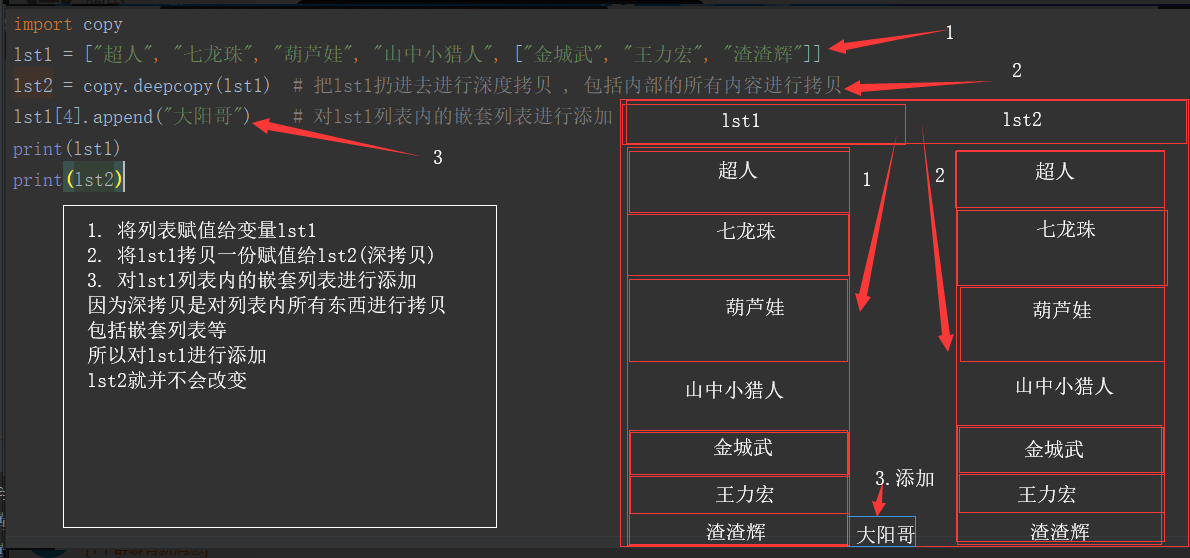
import copy lst1 = ["超人", "七龙珠", "葫芦娃", "山中小猎人", ["金城武", "王力宏", "渣渣辉"]] lst2 = copy.deepcopy(lst1) # 把lst1扔进去进行深度拷贝 , 包括内部的所有内容进行拷贝 lst1[4].append("大阳哥") # 对lst1列表内的嵌套列表进行添加 print(lst1) print(lst2) #输出结果: #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉', '大阳哥']] #['超人', '七龙珠', '葫芦娃', '山中小猎人', ['金城武', '王力宏', '渣渣辉']]
*为什么要有深浅拷贝
*拷贝比创建对象的过程要快