无论是面试还是笔试,有一个问题经常被问到:详细讲述从浏览器输入地址到呈现页面中间发生了什么事情。
前端工程师不能只懂得写页面,还要拓展学习其他方面,例如计算机网络,我们要了解页面的获取机制,想办法从页面上提高网络性能。
一、什么是HTTP?
HTTP是超文本传输协议,计算机之间要通信,必须遵循协议的规则。
二、HTTP工作过程?
简单概括就是三个步骤。
- HTTP客户端发起请求,创建端口。
- HTTP服务器在端口监听客户端请求。
- HTTP服务器向客户端返回状态和内容
三、以谷歌浏览器,访问博客(www.mshanzi.com)
1、输入地址后回车,首先执行域名解析。
(1)Chrome搜索自身的DNS缓存,看有没有对应该域名的IP地址,这个缓存的时间只有一分钟。
(查看浏览器自身缓存:chrome://net-internals/#dns)
(2)如果在浏览器没有找到缓存或者缓存已经失效,则搜索操作系统自身的DNS缓存。
(3)如果在操作系统中也没有找到缓存或者缓存已经失效。则读取本地的host文件。
(host文件:window在System32\drivers\etc;mac在finder中按快捷键组合 Shift+Command+G 三个组合按键,并输入 Hosts 文件的所在路径:/etc/hosts)
(4)如果在host文件中找不到对应的配置,浏览器则发起一个DNS的系统调用。
(5)主机向本地域名服务器(宽带运营商服务器)发出查询(主机向本地域名服务器的查询一般是递归查询)。
① 本地域名服务器查看本身缓存。
② 如果本地域名服务器没有该域名的缓存,则发起一个迭代DNS解析的请求。
A 本地域名服务器会向根域名服务器发送迭代查询请求报文,查询域名对应的IP地址。如果根域名服务器知道,则给出IP地址;否则,根域名服务器会给出com域的顶级域名服务器的IP地址,让本地域名服务器再向顶级域名服务器查询。
B 本地域名服务器向顶级域名服务器发送迭代查询请求报文,查询域名对应的IP地址。如果顶级域名服务器知道,则给出IP地址;否则,顶级域名服务器会给出mshanzi.com域的权限域名服务器的IP地址,让本地域名服务器再向权限域名服务器查询。
C 到了mshanzi.com域的权限域名服务器(域名注册商的地址,例如万网),拿到www.mshanzi.com对应的IP地址。
③ 本地域名服务器把结果返回操作系统内核同时缓存起来。
④ 操作系统内核把结果返回浏览器。
⑤ 最后浏览器拿到了mshanzi.com对应的IP地址。
2、连接并进行通信。
(1)浏览器获得域名对应的IP地址后,发起HTTP“三次握手”。主机发送TCP连接请求,这个请求经过层层路由,TCP/IP协议栈,最后到达web服务器端。
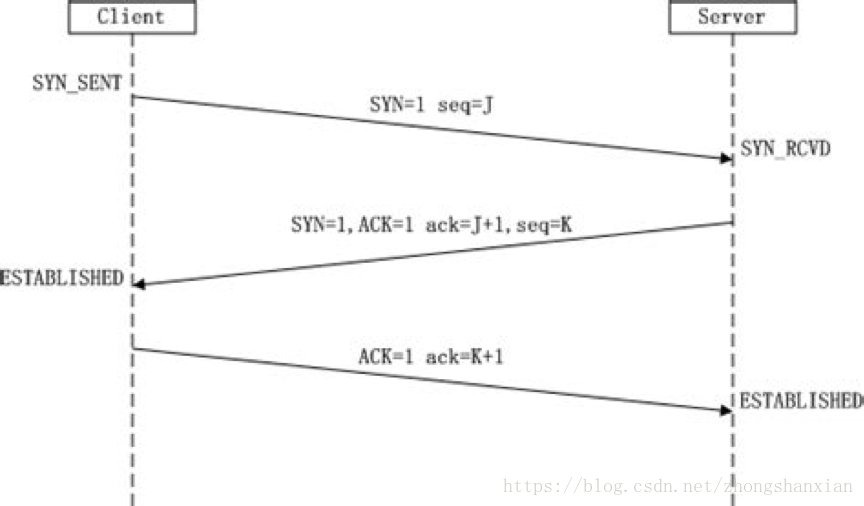
① 客户端在打算建立TCP连接时,向服务器发出连接请求报文段,这是报文段首部中的同步位SYN=1,同时选择一个初始序号seq=J。这是客户端进入SYN_SENT(同步已发送)状态。
② 服务器端接收到连接请求报文段后,如同意建立连接,则向客户端发送确认。在确认报文段中应把SYN位和ACK位(确认位)都置1,确认号ack=J+1,同时也为自己选择一个初始序号seq=K。这时服务器进入SYN_RCDV(同步收到)状态。
③ 客户端收到服务器端的确认后,还要向服务器端给出确认。确认报文段的ACK置1,确认号ack=K+1,序号seq=J+1。这时,TCP连接以建立,客户端进入ESTABLISHED(已建立连接)状态。
④ 服务器端收到客户端的确认后,已经入了ESTABLISHED(已建立连接)状态。
为什么最后客户端还要发送一个确认报文段给服务器?
这主要是防止已失效的连接请求报文段突然又传到了服务器端,因而产生错误。
具体情况:客户端发出的第一个连接请求报文段并没有丢失,而是在某些网络节点长时间滞留了,以致延误到连接释放以后的某个时间才到达服务器端。这本来是一个早已失效的报文段,但是服务器端收到这个失效的连接请求报文段之后,会误认为是客户端又发出一次新的连接请求,于是向客户端发出确认报文段,同意建立连接。
那么此时,如果不采用第三次握手,那么服务器端之遥发出确认,新的连接就建立了。
而实际客户端没有发出建立连接的请求,因此不会响应服务器端的确认报文段,因此连接不会建立。
(2)TCP/IP连接建立起来后,浏览器就可以向服务器发送http请求了,例如请求mshanzi.com的资源。
(3)服务器接收到这个请求,根据路径参数,经过后端的一些处理之后,把处理后的一个结果的数据返回给浏览器,如果是博客页面,就会把完整的html页面代码返回给浏览器。
(4)浏览器拿到了博客的完整html页面代码,在解析和渲染这个页面的时候,里面的js,css,图片静态资源,他们同样是一个个http请求都需要经过商民的主要步骤。
(5)浏览器根据拿到额资源对这个页面进行渲染,最终把一个完整的页面呈现给了用户。
四、http请求和响应详解
无论是请求还是响应,都包括http头部和正文信息。
http头部:发送的是一些附加信息,如内容类型,服务器发送响应的日期,http状态码。
正文:用户提交的表单数据。
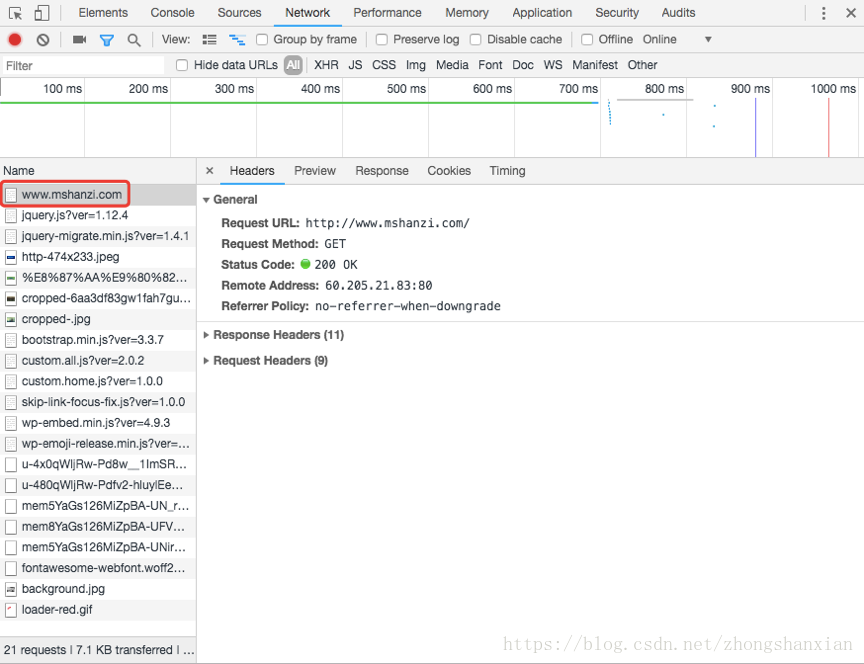
Request URL:请求路径。
Request method:请求方法(LINK,UNLINK已被http/1.1废弃)
Status code:响应状态码。
Response headers:响应头部。
Request headers:请求头部。
Remote address:域名解析后的地址(http协议用的是80端口,https协议用的是443端口)。
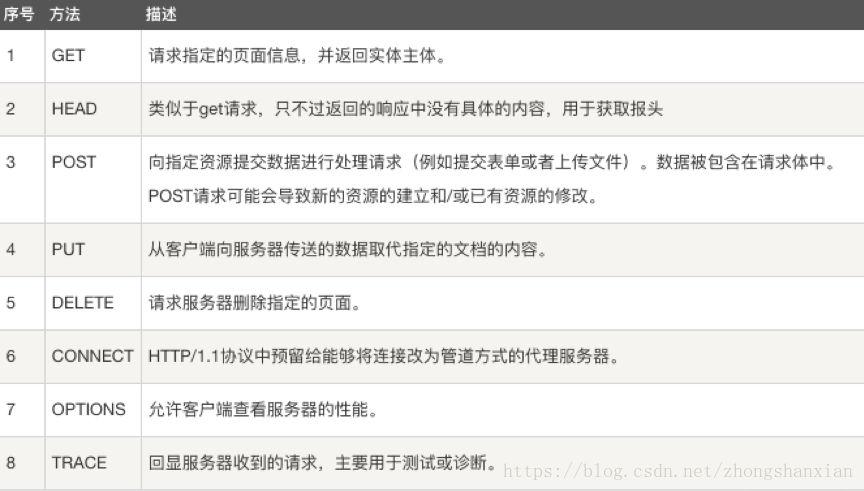
请求方法:
常用响应状态码:
200:请求被正常处理。
304:服务器端资源未改变,可直接使用客户端未过期的缓存。
400:请求报文中存在语法错误,服务器无法理解请求。
401:发送的请求需要有通过HTTP认证。
403:对请求资源的访问被服务器拒绝了,可能是没有权限。
404:服务器上没有找到请求的资源。
500:服务器端在执行请求时发生了错误。
503:服务器处于维护或者繁忙,现在无法处理请求。
1xx:信息性状态码,接受的请求正在处理。
2xx:成功状态码,请求正常处理完毕。
3xx:重定向状态码,需要进行附加操作以完成请求。
4xx:客户端错误状态码,服务器无法处理请求。
5xx:服务器错误状态码,服务器处理请求出错。
请求头部:
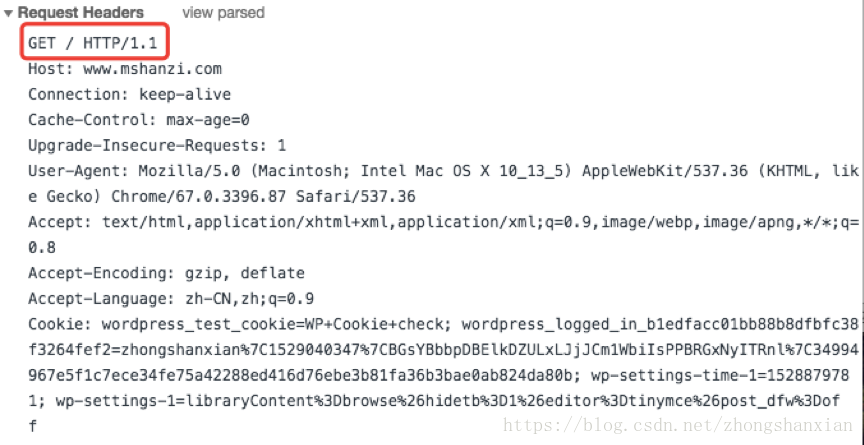
请求方法是get,在根目录,使用的是HTTP/1.1协议。
响应头部:
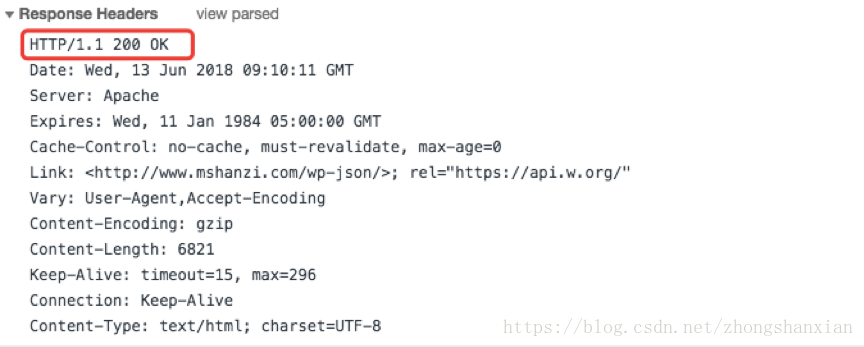
使用的是HTTP/1.1协议,请求状态码。
参考:
进击Node.js基础(一)之5-4,5-5 --Scott
《图解HTTP》—上野宣
《计算机网络》—谢希仁
图片引用,侵权联系立删
前往-->博主个人博客