最近,AMD 发布 MIOpen。至此,AMD 始于15年的打造 GPU 计算生态的 Boltzmann Initiative,有了阶段性的成果。
下面本文从深度学习计算的视角来审视一下 AMD 推出的 ROCm 生态。当然, ROCm 是一个完整的 GPGPU 生态,这里的讨论大体也适用于其他应用领域。
1. Overview
ROCm 的目标是建立可替代 CUDA 的生态(图1),并在源码级别上对 CUDA 程序的支持。
图1.

为了实现目标,ROCm 复制了 CUDA 的技术栈。对比如图2、图3(本文不考虑 OpenCL 支持)。
图2. CUDA 栈

图3. ROCm 栈
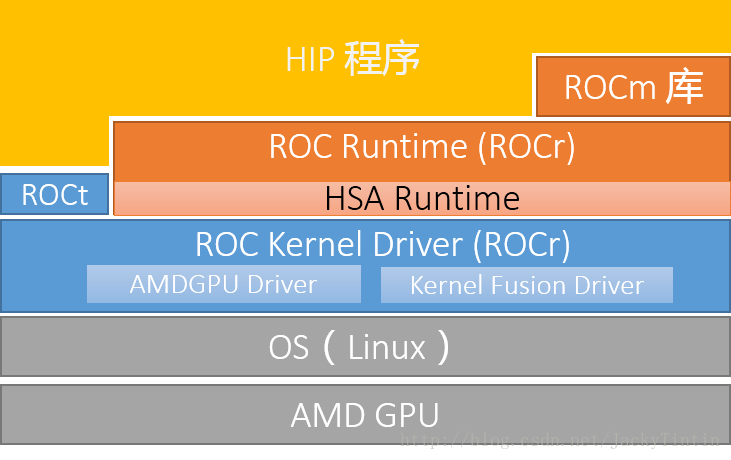
由于 ROCm 是开源平台,出于模块化以及对一些开放标准的支持,ROCm 的封装层次较 CUDA 会多一些。好在,这对一般开发者是不可见。
2. ROCm
2.1 名词解释
在介绍 ROCm 前,首先对一些概念进行说明。
ROC —— Radeon Open Computing,即 “Radeon 开放计算”。其中,Radeon 是 AMD GPU 产品的品牌名。
ROCm——ROC platforM 的简称,是基于一系列开源项目的 AMD GPU 计算生态。ROCm 之于 AMD GPU,基本上相当 于 CUDA 之于 NVIDIA GPU。除 ROCm 外,还有一系列 ROCx 的简称,如 ROCr —— ROC Runtime,ROCk —— ROC kernel driver, ROCt —— ROC Thunk 等。
扫描二维码关注公众号,回复: 2040220 查看本文章
HSA——Heterogeous system architecture,可以简单理解为硬件上的一层抽象。 AMD 等为支持 CPU+GPU 混合计算生态而成立了非赢利组织 HSA 基金,提供 runtime 和架构 API 标准。现成员包括 AMD、三星、高通、ARM、TI、Imagination、MTK等。
GCN——Graphics Core Next,是 AMD 11年推出的全新架构,以区别于之前基于基于 VLIW (超长指令字)的架构。由于现在所有 AMD GPU 都建于 GCN 架构,失去 ”next“ 的对象,因此,GCN 可以简单理解为 AMD GPU 架构。
2.2 ROCm
了解 ROCm 最快的方式可能是和 CUDA 对比。表1给出了主要模块的对比。
| CUDA | ROCm | 备注 |
|---|---|---|
| CUDA API | HIP | C++ 扩展语法 |
| NVCC | HCC | 编译器 |
| CUDA 函数库 | ROC 库、HC 库 | |
| Thrust | Parallel STL | HCC 原生支持 |
| Profiler | ROCm Profiler | |
| CUDA-GDB | ROCm-GDB | |
| nvidia-smi | rocm-smi | |
| DirectGPU RDMA | ROCn RDMA | peer2peer |
| TensorRT | Tensile | 张量计算库 |
| CUDA-Docker | ROCm-Docker |
2.2.1 HIP (Heterogeous-compute Interface for Portability,异构计算可移植接口)
HIP 可以说是 CUDA API 的”山寨克隆“版。除了一些不常用的功能(e.g. managed memory)外,几乎全盘拷贝 CUDA API,是 CUDA 的一个子集。
HIP 不支持的 CUDA 功能,参见 FAQ。
开发者可以在 HIP 里得到和 CUDA 类似的编程语法,和大量的 API 指令,从而以类似 CUDA 的风格为 AMD GPU 编程。大多数情况下,通过 ”cuda“ 和 ”hip“字符的相互替换(e.g. cudaMalloc -> hipMalloc),可以在源码级别完成移植(图4)。实际上, AMD 提供的 HIPify 工具,核心只是一个 perl 脚本,主要功能就是查找与替换。
图4. HIP 源码级别兼容 CUDA 代码 【src】
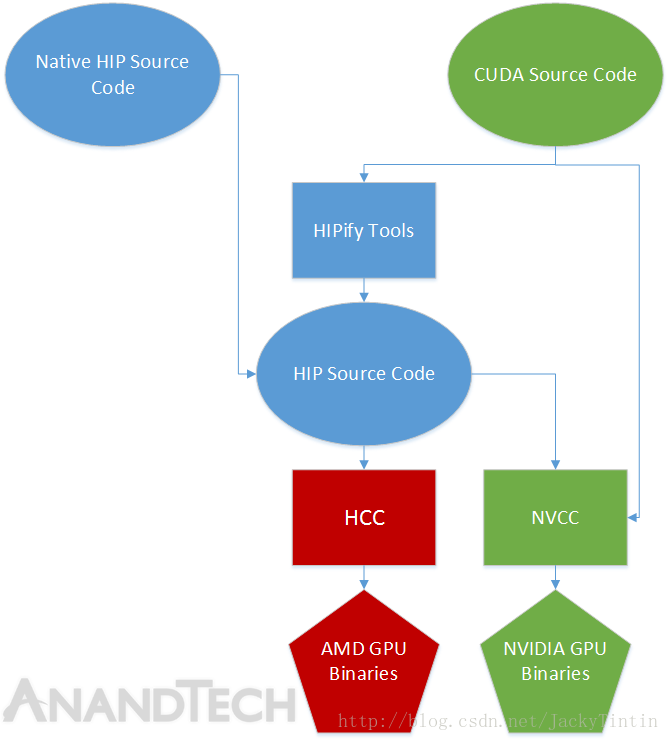
当然,ROCm 还提供了 CUDA 生态的一系列函数库的替代版本,这些将在后面介绍。另外,A 卡和 N 卡在 warp size 上有差异,在对移植代码进行性能优化时也需要考虑。
AMD 曾在 SC’16 上展示了从 CUDA 向 HIP 移植的 CAFFE,号称 5.5 万行代码只用了不到 4 天,99.6% 都是自动移植完成。
2.2.2 HCC (Heterogeneous Compute Compiler)
HCC 是 基于 CLANG/LVVM 的开源编译器,是 ROCm 中 NVCC 的对应工具。
相比于 NVCC,HCC 的提供了更多的功能 。HCC 单一编译环境统一支持 ISO C++ 11/14、C14、OpenMP 4.0,并且前向性的支持 C++17 “Parallel STL”,兼容 C++ AMP(微软推出的并行计算 API 标准),而且是同时适用于CPU、GPU。
Google 15 年推出了开源的 CUDA 编译器,GPUCC。现在没有消息,难道一心扑在 TPU 上,对 CUDA 生态没有了兴趣?
2.2.3 函数库
BLAS
rocBLAS 接口上兼容 Netlib BLAS 和 cuBLAS-v2 API。cublas 替代为 rocblas 即可,方便移植。下面是一个示例接口:
rocblas_status
rocblas_sgemv(rocblas_handle handle,
rocblas_operation trans,
rocblas_int m, rocblas_int n,
const float* alpha,
const float* A, rocblas_int lda,
const float* x, rocblas_int incx,
const float* beta,
float* y, rocblas_int incy);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
此外,rocblas 还有一个 HIP 的 wrapper,见叫 hipblas。另外,ROCm 还有另一库 hcBLAS,是基于 HCC 的实现。
随机数
AMD 提供了随机数库 hcrng(HC Random Number Generator)。hcrng 目前支持如下四种,均匀分布伪随机数生成算法:
- MRG31k3p
- MRG32k3a
- LFSR113
- Philox-4x32-10
目前似乎只有均匀分布伪随数生成器,也不支持准随(quasi)机数生成。相比于 curand,功能上还不够丰富。
FFT
rocFFT 接口设计上与 clFFT 一致。(应该和 cufft 接口不兼容,但我没有对比确认)。rocFFT 是使用 HIP 编写的,因此,能够使用 NVCC 编译在 NVIDIA GPU 上使用。
另外还有去接基于 HCC 的库——hcFFT。
稀疏矩阵
同 cusparse 对应的是 hcsparse 一度移到了官方 github 上,但现在(20170708)又从官方移除。不清楚目前开发状态。
rocxxx 为基于 HIP 的函数库,因此,可以通过 NVCC 编译后在 NVIDIA GPU 上运行; hcxxx 为基于 HCC 的函数库,只支持 AMD 平台。rocxxx 应该为官方主推的函数库(官方称为 next generation),但是 hcxxx 库在 github 上还有更新。AMD 在生态和文档建设水平,还是有待进一步提高。
MIOpen(Machine Intelligence Open)
叫 rocdnn 之类的难道不好么?无故增加认知难度。。。
MIOpen 是 AMD 版的 cuDNN。 最近推出了 MIOpen 基本完成了对 CUDA 的对位复制。支持 OpenCL 和 HIP 两种编程模式。
虽然 MIOpen 进一步完善了 AMD 的深度学习计算生态(当然相比于 cuDNN,MIOpen 还有待进一步开发),但似乎也没有什么好介绍的。MIOpen 支持的功能参见文档。
MIOpen 使用了一个叫 MIOpenGEMM 的矩阵乘法库。为什么没有将功能合并到 rocBLAS 中?详细一看,这贷是基于 OpenCL 的。。。。这生态真是丰(混)富(乱)。
3. 深度学习框架支持
ROCm 通过支持各大头部框架,试图打入深度学习市场。目前 各个大框架的支持情况如下:
| Framework. | Status. | MIOpen Enabled. | Upstreamed | Current Repository |
|---|---|---|---|---|
| Caffe | Public | Yes | https://github.com/ROCmSoftwarePlatform/hipCaffe | |
| Tensorflow | Development | Yes | CLA in Progress | Notes: Working on NCCL and XLA enablement, Running |
| Caffe2 | Upstreaming | Yes | CLA in Progress | https://github.com/ROCmSoftwarePlatform/caffe2 |
| Torch | Upstreaming | Development In process | https://github.com/ROCmSoftwarePlatform/cutorch_hip | |
| torch cunn | Upstreaming | Development | https://github.com/ROCmSoftwarePlatform/cunn_hip | |
| PyTorch | Development | Development | ||
| MxNet | Development | Development | ||
| CNTK | Development | Development |
最新的进展参见官方页面。
感谢生态的成熟,配置和硬件和驱动环境后,普通用户几乎没有切换成本。相比于上面罗列的工具,对这些流行框架的支持可能是更加重要的。
4. 讨论
13 年开始,尝试利用 OPenCL 打入深度计算领域,先是尝试移植 cuda-convnet,后转向 Caffe,最后的成果是 OpenCL Caffe,虽然是有益的尝试,但这项努力并没有引起很多的关注。
相比于几年前,这次 AMD 有更大的机会,在 GPGPU 的市场分得一杯羹。
- 内部
- 终于下决心好好搞软件了,从生态的高度进行布局。
- 抢人策略,源码级别兼容 CUDA,一定程度上借用 CUDA 生态。
- 外部
- 深度学习框架的竞争大局已定,基本在少数几家巨头之间进行。AMD 只需要对若干个头部框架进行支持即可,开发量是可接受的。(百度刚刚宣布与 NVIDIA 深入合作,为 Paddle 优化 GPU 代码,不知道百度的专家对 ROCm 有什么想法没?)。
- 大厂商根本不在乎用那家 GPU,Google 干脆自己搞了 TPU,大的数据中心都有 FPGA 等加速方案。 除了 NVIDIA,大家都是乐见其成的,竞争总是对 GPU 消费方有利的。
- 高级框架的稳定,在源码级别形成了实事上标准化。大部分时候,普遍研究者和开发者使用框架提供的接口,可以完成定制操作。因此,个人用户转换后端的成本会非常低。
现在对 AMD 可以说是天时地利人和,这波努力倒不至于,但至少占领部分市场应该是没问题。总之,期待 ROCm 在各大主流框架上的 benchmark 结果。
References
- ROCm 官方网站:https://rocm.github.io
- CUDA Document: http://docs.nvidia.com/cuda
- ROCm Core Technology.
- ROCm Software Platform.
- AMD SC’15 slides.
- AMD SC’16 slides.
- HSA Foundation.