本文代码见点击打开链接
https://github.com/crystal30/SGDLinrearRegression
一. 梯度下降法(Batch Gradient Descent)
1.梯度下降法的原理
(1) 梯度下降法是一种基于搜索的最优化方法,不是一个机器学习算法。
(2) 作用:最小化一个损失函数.
扩展:梯度上升法与梯度下降法相反,是最大化一个效用函数。
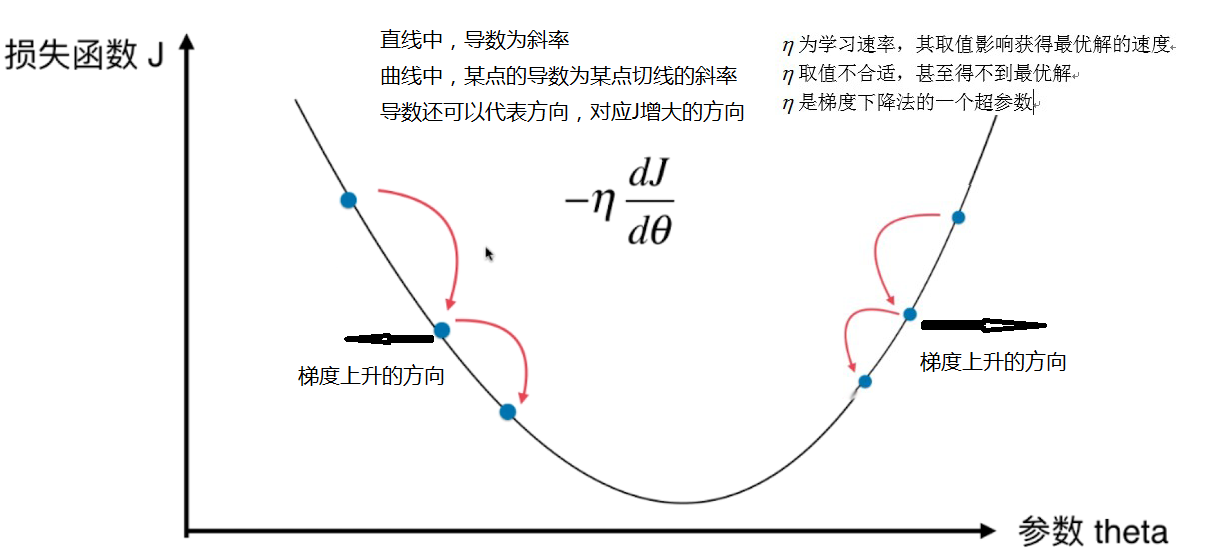
如下图eta太大,得不到最优解

另外,梯度下降法有可能找不到全局最优解,只能找到局部最优解

2.线性回归中使用梯度下降法
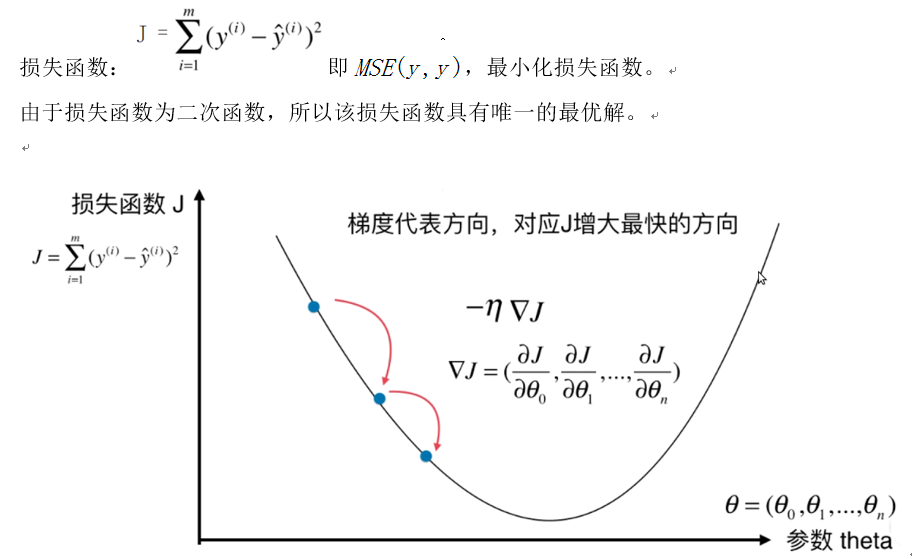


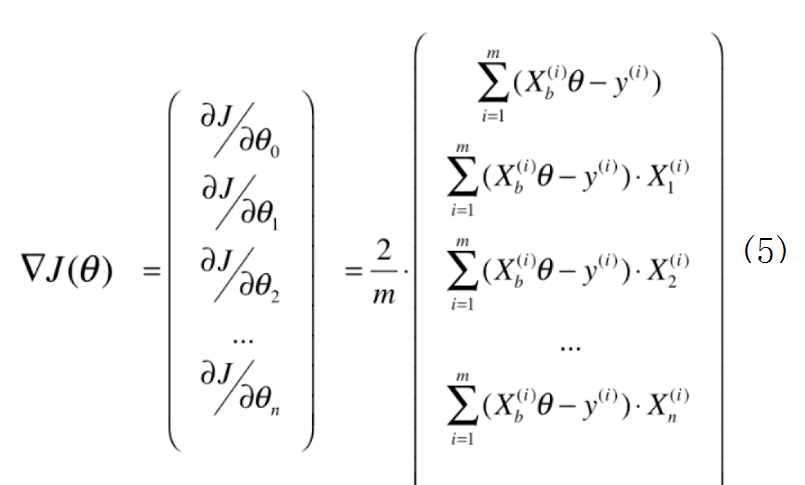

3.向量化计算
为编程方便,把计算过程整理为向量的形式
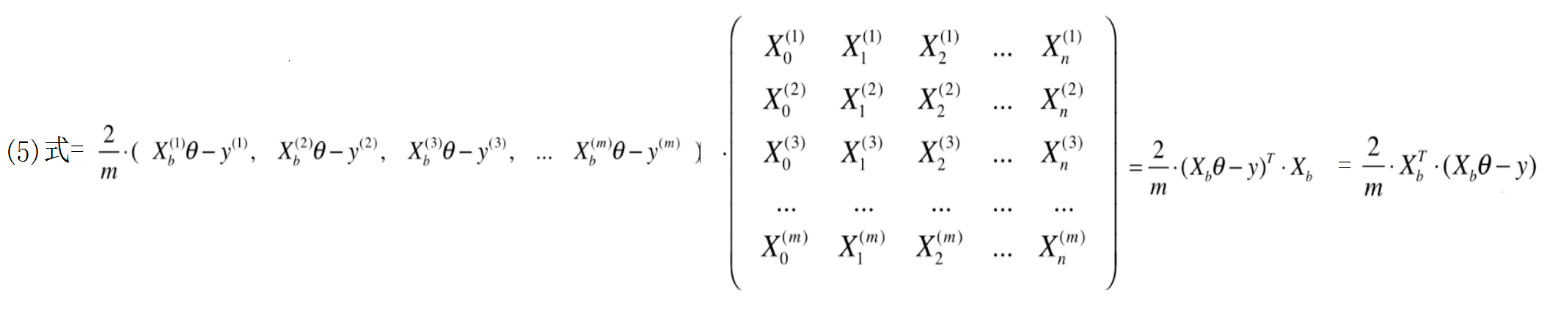
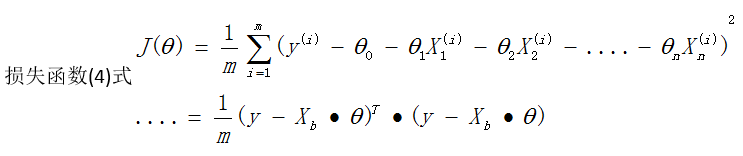
在这里向量y和theta均默认为列向量
4.线性回归中使用梯度下降法的算法步骤

二、随机梯度下降法(Stochastic Gradient Descent)
1.随机梯度下降法的原理
随机梯度下降法即指:每次计算梯度时,只随机的选取一个样本来计算梯度,这样就大大的减小了计算的复杂度
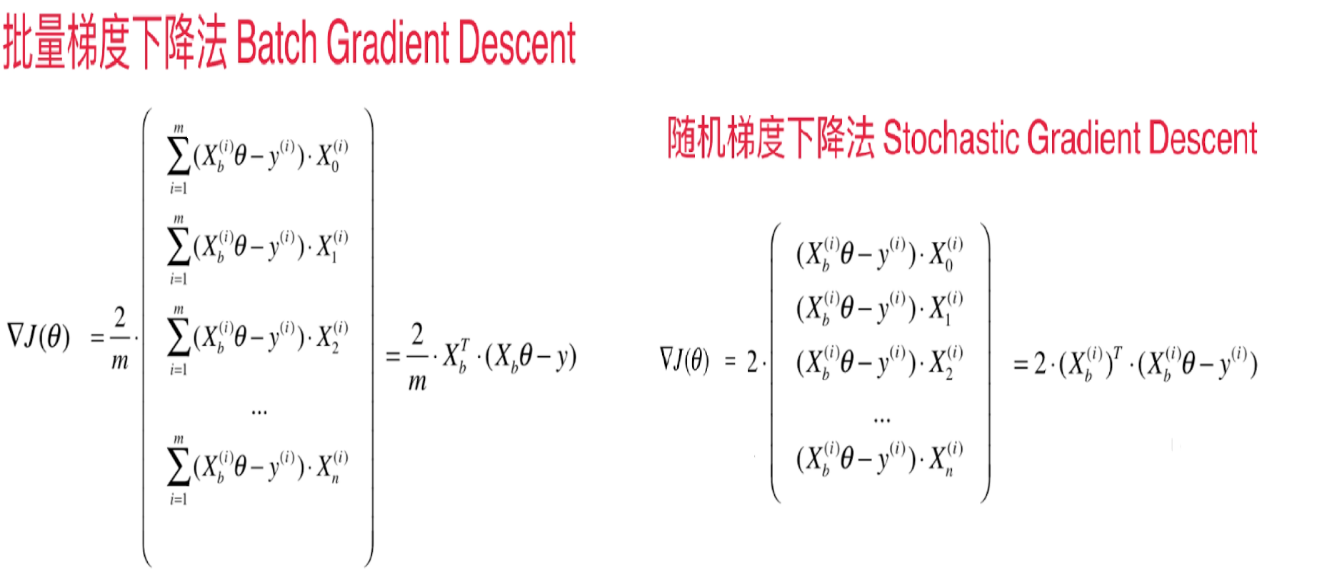
批量梯度下降法比较稳定,一定可以朝着函数的极小值的方向(如果函数只有一个极小值,则可以说是最小值)迈进。
随机梯度下降法速度快,但每次的方向不稳定,甚至可能向反方向(函数上升的方向)迈进。
随机梯度下降法的优点:更快的运行速度。且机器学习算法领域很多算法都需使用随机的优点(如随机搜索,随机森林)
随机梯度下降法的缺点: 可能跳出局部最优解

2.线性回归中使用随机梯度下降法的算法步骤
(1)将数据分为训练数据和测试数据
(2)分别将训练数据和测试数据归一化(注:利用多元线性回归的正规方程解不需要数据归一化,因为其是一个具体的公式,带入具体的数值即可;而梯度下降法中,每一个特征相当于一个维度,当某个维度的量纲较大时,会导致整体的搜索步长变大,算法性能有所下降)
X为训练数据,y为target,共有m个样本;Xb为全1的列向量与X的拼接
程序实现:Xb = numpy.hstack([numpy.ones(shape=(X.shape[0],1)),X])

(6)当i=m时,i_iters =i_iters+1(遍历次数加一)
(7)当i_iters>iters,终止迭代,否则继续进入(3)
三.小批量梯度下降法(Mini-Batch Gradient Descent)
1.小批量梯度下降法
批量梯度下降法一定能沿着极小值的方向迈进,比较稳定,然而每次计算梯度时都需要遍历所有样本,计算量比较大。
随机梯度下降法的运算速度虽然比较快,但有可能跳出局部最优解,每次的迈进方向不稳定,甚至有可能向反方向迈进。
故每次计算梯度时,选取一部分样本,即小批量梯度下降法。与随机梯度下降法相比,增强了方向的稳定性。与批量梯度下降法相比,运算量大大减少,运行速度也更快。
2.线性回归中使用小批量梯度下降法的算法步骤
(1)将数据分为训练数据和测试数据
(2)分别将训练数据和测试数据归一化(注:利用多元线性回归的正规方程解不需要数据归一化,因为其是一个具体的公式,带入具体的数值即可;而梯度下降法中,每一个特征相当于一个维度,当某个维度的量纲较大时,会导致整体的搜索步长变大,算法性能有所下降)
X为训练数据,y为target,共有m个样本;Xb为全1的列向量与X的拼接
程序实现:Xb = numpy.hstack([numpy.ones(shape=(X.shape[0],1)),X])

(6) 当i=m//batch时,i_iters =i_iters+1(遍历次数加一)
(7) 当i_iters>iters,终止迭代,否则继续进入(3)
四.梯度的调试
1.利用梯度的定义来进行梯度调试
梯度下降法不仅能在线性回归中使用,在其他算法中也具有广泛的用途。当损失函数非常复杂,不能确保分析得出的梯度表达式准确时,可以参照一个benchmark(通过定义求梯度),看我们的梯度表达式是否正确(当然引起与benchmark不同的原因有很多,这里我们不考虑其他原因)。这就是我们所说的梯度调试

