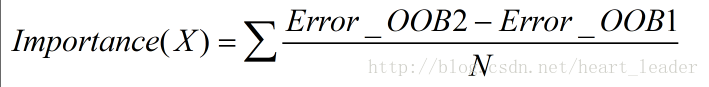信贷风险模型
今天在复习随机森林的时候,突然有了一些思考:信贷风险模型在我的理解,就是为了评估某个客户(企业,个体)在贷款等相关业务中,是否能够有效的将其贷款回收。通过自己的一些了解与猜想,信用评估模型中的主要评价来源是客户的数据。那么,数据可能会存在各种各样的数据,例如其历史借贷信息等。同时,收集的数据肯定会有很多的噪声。所以,如何根据这些特征信息来分析客户的借贷情况就显得尤为重要。
通常,在机器学习这里,我们都会构造一个合适的模型,从而根据数据来训练出一个比较合适的参数。这里,数据的特征构造对模型的性能会造成很大的影响。
所以,这里我就联想了到了再进行模型训练之前可以对数据进行一些操作,其中特征的选择就可以借鉴一下。下面,我主要介绍如何使用随机森林进行特征选择。
随机森林-特征重要性评价
这里,随机森林可以作为一种特征选择的工具来进行数据预处理。随机森林的主要思想可由下面这张图来说明:

主要的步骤有三步:
- 对于随机森林的每一颗决策树,使用响应的OOB(袋外数据)来计算袋外数据误差(Eroor_OOB1)
- 然后,在袋外数据OOB的所有样本中,对于某个样本特征X随机加入噪声干扰,相当于随机改变了样本在特征X处的值, 再次计算袋外数据误差Error_OOB2
- N棵树: