EOS柚子
EOS环境部署
作者-磨链社区-KY
随着EOS主网上线的时间越来越近,对于超级节点竞选的话题也越来越多。很多人认为它是区块链3.0技术,可以推动区块链技术的商用落地。作为开发者,我们可以在EOS上,利用它提供的各种功能,高效地创建出区块链应用。本文以官方刚发布的EOSIO DAWN 3.0来介绍EOS的环境部署。
概述
在着手部署之前,我们可以先通过官方的一张EOS系统架构图,来了解一下系统中各个组件之间的关系。 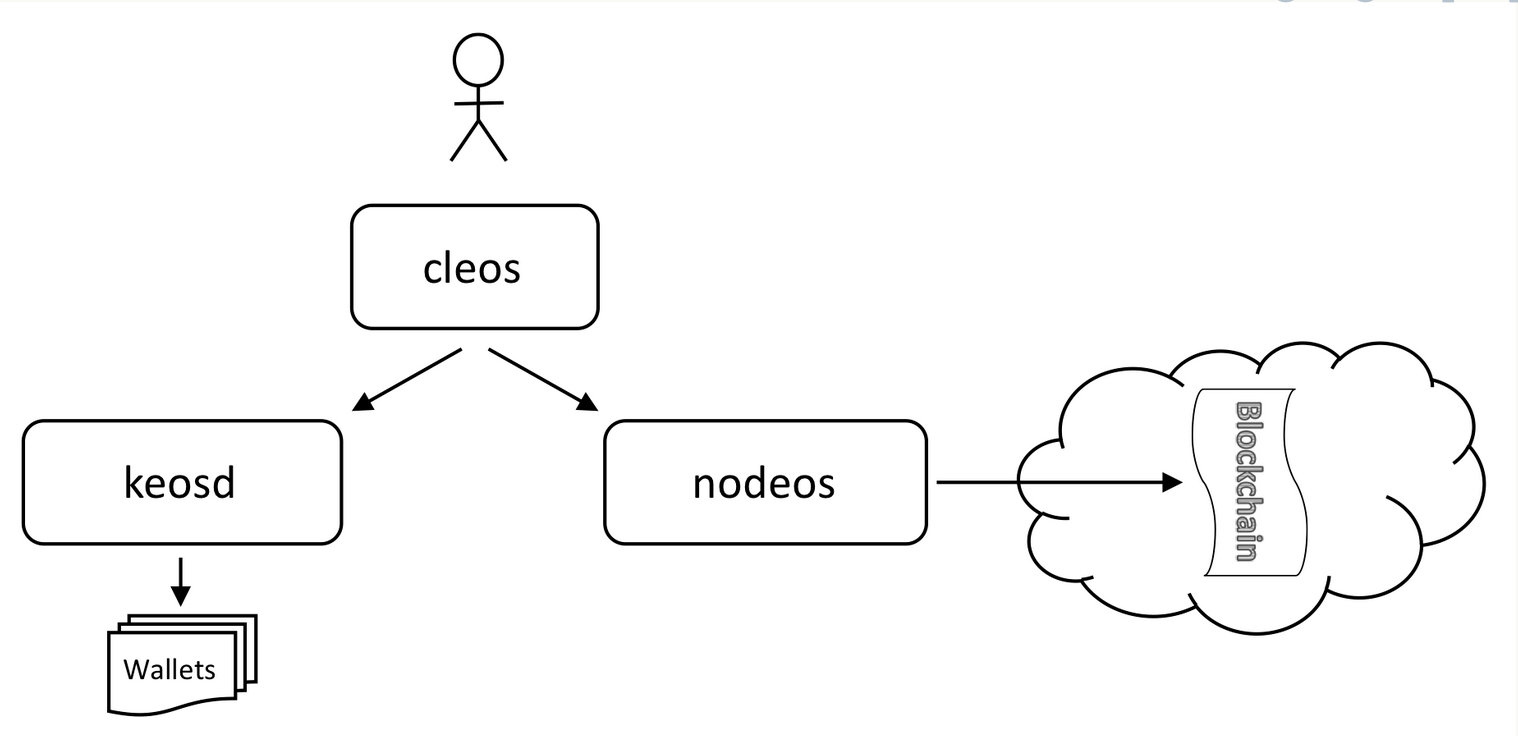
- nodeos - 服务器端区块链节点组件
- cleos - 操作区块链和管理钱包的命令行工具
- keosd - 钱包管理组件
从图中的关系可见,用户可以通过 cleos 命令行工具对 nodeos 和 keosd 进行交互,实现对区块链和钱包的各种管理操作。
部署前准备
编译部署EOSIO最简单的办法是使用自动编译脚本进行编译,当然也可以自己手动编译。本文主要介绍如何使用自动编译脚本进行编译安装。
目前自动编译脚本支持的系统包括:
Amazon 2017.09 and higher.Centos 7.Fedora 25 and higher (Fedora 27 recommended).Mint 18.Ubuntu 16.04 (Ubuntu 16.10 recommended).MacOS Darwin 10.12 and higher (MacOS 10.13.x recommended).
系统要求(所有平台)
8GB RAM free required20GB Disk free required
以下我使用 ubuntu 16.04 操作系统进行介绍
获取代码
首先进入项目目录,下载源代码
git clone https://github.com/EOSIO/eos --recursive
参数 --recursive 表示下载项目需要的所有子模块,建议加上
编译安装 EOSIO
运行自动编译脚本
cd eos./eosio_build.sh
如果你设备的内存或硬盘达不到最低要求,可能会出现类似下面的报错
ky@ubuntu:~/Project/eosio/eos$ ./eosio_build.shBeginning build version: 1.2Fri Apr 27 08:02:24 UTC 2018User: kygit head id: 5abf3060734f2973567bbacdd3e8af7cc1fc802eCurrent branch: * masterARCHITECTURE: LinuxOS name: UbuntuOS Version: 16.04CPU speed: 2194MhzCPU cores: 1Physical Memory: 962 MgbDisk install: /dev/sda1Disk space total: 18GDisk space available: 10GYour system must have 7 or more Gigabytes of physical memory installed.Exiting now.
当看到下图时,代表EOS.IO已经成功的编译和安装了。 
验证环境(可选)
如果需要,你可以使用以下命令来运行一组测试程序,以便验证环境是否被正常安装。 Linux 平台:
~/opt/mongodb/bin/mongod -f ~/opt/mongodb/mongod.conf &
MacOS:
/usr/local/bin/mongod -f /usr/local/etc/mongod.conf &
然后执行:
cd buildmake test
创建和启动单节点测试网络
编译部署好EOS环境之后,在 build/programs/nodeos 目录下会存在 nodeos 命令,可以通过运行该命令创建和启动单节点测试网络:
cd build/programs/nodeos./nodeos -e -p eosio --plugin eosio::wallet_api_plugin --plugin eosio::chain_api_plugin --plugin eosio::account_history_api_plugin
执行完命令之后会出现:
******************************** ** ------ NEW CHAIN ------ ** - Welcome to EOSIO! - ** ----------------------- ** ********************************Your genesis seems to have an old timestampPlease consider using the --genesis-timestamp option to give your genesis a recent timestamp325596ms thread-0 producer_plugin.cpp:176 plugin_startup ] producer plugin: plugin_startup() end326063ms thread-0 producer_plugin.cpp:239 block_production_loo ] eosio generated block acff902a... #1 @ 2018-04-28T09:05:26.000 with 0 trxs, lib: 0326501ms thread-0 producer_plugin.cpp:239 block_production_loo ] eosio generated block f30acbb3... #2 @ 2018-04-28T09:05:26.500 with 0 trxs, lib: 1327001ms thread-0 producer_plugin.cpp:239 block_production_loo ] eosio generated block 01c10821... #3 @ 2018-04-28T09:05:27.000 with 0 trxs, lib: 2
这时,nodeos 就运行起来了,但其中只有一个生产者 eosio
使用 cleos 与系统交互
编译部署好EOS环境之后,在 build/programs/cleos 目录下会存在 cleos 命令,可以通过运行该命令与系统进行交互。 在启动单节点测试网络之后,我们另外打开一个命令行窗口,进入 build/programs/cleos 目录
cd build/programs/cleos
查看区块链当前状态
> ./cleos get info{"server_version": "4e99117b","head_block_num": 1764,"last_irreversible_block_num": 1763,"head_block_id": "000006e432459f5588cbfba1a568bef24aa25cdfb4e460a5ef1f71ac5f8905ad","head_block_time": "2018-04-28T09:59:56","head_block_producer": "eosio"}
信息字段说明:
server_version 表示当前服务器运行的eos版本。head_block_num 表示最新区块的编号,可以理解为区块高度。last_irreversible_block_num 表示不可逆区块的最大编号。head_block_id 是最新区块的id。head_block_time 是最新区块的生成时间。head_block_producer
最新区块的生产者名称,由于我们只有一个节点,因此其取值一直是 eosio。
创建钱包
在区块链上进行各种交易操作需要用私钥签名授权,钱包就是存储这些私钥的地方。我们可以通过以下命令创建一个钱包:
> ./cleos wallet createCreating wallet: defaultSave password to use in the future to unlock this wallet.Without password imported keys will not be retrievable."PW5JL9JQAAE9kY3QsCP9G3PTz5WUL5Q1d1VfVrshi82KvedimADf4"
命令执行完,会创建一个名为 default 的钱包,并返回钱包密码,该密码可以用来解锁钱包,需要保存好。
查看钱包列表
创建钱包之后,可以查看钱包列表:
> ./cleos wallet listWallets:["default *"]
如果你没有指定钱包名称,默认操作的都是 default 钱包。
将私钥导入钱包
创建新的账户需要用到已经被初始化的账号,在测试网络中账户 eosio 是已经被初始化了的,可以在 config.ini 文件中找到它对应的公钥和私钥对:
private-key = ["EOS6MRyAjQq8ud7hVNYcfnVPJqcVpscN5So8BhtHuGYqET5GDW5CV","5KQwrPbwdL6PhXujxW37FSSQZ1JiwsST4cqQzDeyXtP79zkvFD3"]
执行以下命令可以将私钥导入钱包:
> ./cleos wallet import 5KQwrPbwdL6PhXujxW37FSSQZ1JiwsST4cqQzDeyXtP79zkvFD3imported private key for: EOS6MRyAjQq8ud7hVNYcfnVPJqcVpscN5So8BhtHuGYqET5GDW5CV
创建密钥对
创建新的账户还需要指定两组密钥对:owner和active。
EOS.IO 软件给所有账户指定了两个默认权限组。一个是"owner"权限组,可以执行任何操作。还有一个“active”权限组,除了更改“owner” 权限组之外,可以执行所有操作。所有其他权限组均由“active”组派生。
可以使用以下命令创建密钥对:
owner key> ./cleos create keyPrivate key: 5KiUyjfLLs6HjaV2LjrXFk62AQ85d6Sfq52XgnpgPUaes1MErPTPublic key: EOS7Nc5Z4Ek8fawzrM4R2xPpEhEuEqhE6hXfLWMBHrELqstjKnAotactive key> ./cleos create keyPrivate key: 5Js2Ts5Rwdh56kLD3NDsu7ZmJxUGruQz9KFVgPwLBnJf5dJ2WbEPublic key: EOS6fCP6JxUPiK1CFvoUNnWUvkxM6UjAx2hjgHCtyjW6xeW3bPZ5G
创建账户
接下来使用 eosio 账户以及两组密钥对来创建新的账户 tester:
> ./cleos create account eosio tester EOS7Nc5Z4Ek8fawzrM4R2xPpEhEuEqhE6hXfLWMBHrELqstjKnAot EOS6fCP6JxUPiK1CFvoUNnWUvkxM6UjAx2hjgHCtyjW6xeW3bPZ5Gexecuted transaction: dbebf3334c4191c1800835b0efb07d7a07076748a6e65f27955510694d72626d 352 bytes 102400 cycles# eosio <= eosio::newaccount {"creator":"eosio","name":"tester","owner":{"threshold":1,"keys":[{"key":"EOS7Nc5Z4Ek8fawzrM4R2xPpEh...
查看账户
通过下面的命令可以查看到账户的权限等信息:
> ./cleos get account tester{"account_name": "tester","permissions": [{"perm_name": "active","parent": "owner","required_auth": {"threshold": 1,"keys": [{"key": "EOS6fCP6JxUPiK1CFvoUNnWUvkxM6UjAx2hjgHCtyjW6xeW3bPZ5G","weight": 1}],"accounts": []}},{"perm_name": "owner","parent": "","required_auth": {"threshold": 1,"keys": [{"key": "EOS7Nc5Z4Ek8fawzrM4R2xPpEhEuEqhE6hXfLWMBHrELqstjKnAot","weight": 1}],"accounts": []}}]}
扩展阅读
分布式存储
以电影为例子,那么有很多电影,分布式节点是不是都要把所有的电影完整存储在本地节点上,还是分开存储,如果一旦分散存储,节点加入和退出会不会影响到整个存储电影的数据。
一致性哈希
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简 单哈希算法带来的问题,使得分布式哈希(DHT)可以在P2P环境中真正得到应用。
一致性hash算法提出了在动态变化的Cache环境中,判定哈希算法好坏的四个定义:
平衡性(Balance):平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。很多哈希算法都能够满足这一条件。
单调性(Monotonicity):单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
分散性(Spread):在分布式环境中,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
负载(Load):负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同 的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。(摘自百度百科-一致性哈希)
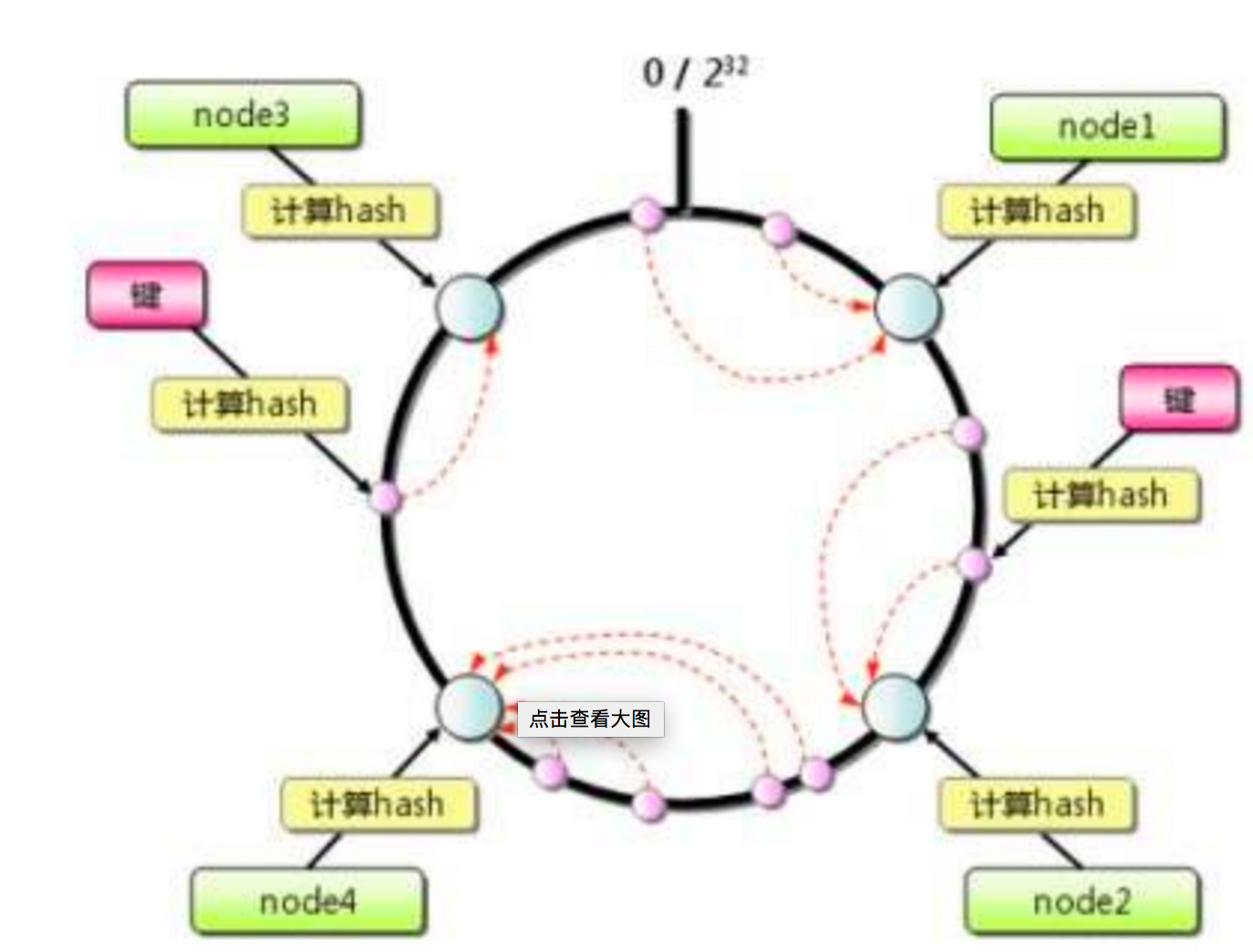
一致性哈希(Consistent Hashing):结合上面的例子说明,使用一组不同的hash函数,根据电影的文件名movie-name分别计算出一组h1(x)计算hash值。根据hash函数h(x)再结合分布式网络中每个节点n的唯一名称或者标签,再计算一组h2(x)计算hash值。针对某一个电影来说,那么h1(x)≈h2(x)。那么讲其一个副本存储在该网络节点上。计算公式:|h1(x)-h2(x)|=min{|h1(x)-h2(x)|}。这个针对每一个任意节点来计算。
那么我们假设有m部电影、网络中有n个节点、有k个hash函数,根据节点的hash值和电影hash最为接近的原则,得到一个存放电影的期望值km/n。
那么问题来了,节点如果不能保证长期在线正常的工作,这个时候就需要考虑节点的加入和退出带来的影响。在这个环境中,网络中的节点无法直接知道那个节点具体存放了那个电影,在搜索的时候会不断询问周边节点,周边节点再询问周边,直到找到所需要的信息。简单理解分布式系统内部有一个虚拟网络,称为覆盖网络(Overlay Network)。
一致性哈希算法设计原理
针对节点的加入和退出,一致性hash算法原则:
环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。
把数据通过一定的hash算法处理后映射到环上,每个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。
节点机器通过hash算法映射到环上
在采用一致性哈希算法的分布式集群中将新的机器加入,其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中,然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
机器的删除
节点(机器)的删除,如果任意出现故障被删除了,那么按照顺时针迁移的方法,对象将会被迁移到下一个节点中,这样仅仅是对象的映射位置发生了变化,其它的对象没有任何的改动。
机器的增加
节点(机器)的添加,如果往集群中添加一个新的节点,通过对应的哈希算法得到KEY4,并映射到环中。
按顺时针迁移的规则,那么对象被迁移到了下一个节点中,其它对象还保持这原有的存储位置。通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
平衡性处理
一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,但这还并不能当做其被广泛应用的原由,因为还缺少了平衡性。引入“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
- 参考:https://blog.csdn.net/cywosp/article/details/23397179/ 有兴趣可以看看全文,文章图片和文字都有详细说明。
IPFS
星际文件系统IPFS(InterPlanetary File System)是一个面向全球的、点对点的分布式版本文件系统,目标是为了补充(甚至是取代)目前统治互联网的超文本传输协议(HTTP),将所有具有相同文件系统的计算设备连接在一起。原理用基于内容的地址替代基于域名的地址,也就是用户寻找的不是某个地址而是储存在某个地方的内容,不需要验证发送者的身份,而只需要验证内容的哈希,通过这样可以让网页的速度更快、更安全、更健壮、更持久。
IPFS的存储与读取
接下来先基础地介绍下IPFS是怎么进行存储和读取的。IPFS文件的存储和读取与BitTorrent上传下载原理相似。
IPFS采用的索引结构是DHT(分布式哈希表),数据结构是Merkle DAG(Merkle 有向无环图)。
单文件存储
研究过文件系统的人都知道索引和扇区这两个概念,如:NTFS一个扇区通常是4K,真正的文件数据都是保存在扇区里面的,找到这些扇区的方式就是建立索引(确切的说是高效的索引),IPFS也是一个文件系统,不同的是,IPFS是没有存储上限的,且不存在空间回收的功能。IPFS存储文件时,如图(没天赋,略丑),会经历以下几个步骤:
1. 把单个文件拆分成若干个256KB大小的块( block,这个就可以理解成扇区 );
2. 逐块(block)计算block hash,hashn = hash ( blockn );
3. 把所有的block hash拼凑成一个数组,再计算一次hash,便得到了文件最终的hash,hash ( file ) = hash ( hash1……n ),并将这个 hash(file) 和block hash数组“捆绑”起来,组成一个对象,把这个对象当做一个索引结构;
4. 把block、索引结构全部上传给IPFS节点(这里先不介绍细节),文件便同步到了IPFS网络了;
5. 把 Hash(file)打印出来,读的时候用;
PS: 这里可以看出IPFS计算文件得到的hash,其实和我们平时计算hash的方式不一样,而且最终的结果也不一样!
这里还漏掉了一个小文件的处理逻辑,和NTFS等文件系统类似,小文件(小于 1KB) 的文件,IPFS会把数据内容直接和Hash(索引)放在一起上传给IPFS节点,不会再额外的占用一个block的大小。
现在,已经把文件的原始数据和文件的索引(即hash)上传到IPFS网络了。前面已经讲过,IPFS是不支持空间回收的,文件一旦同步到IPFS,将永久的存在。看起来这样会招来一个严重的后果就是,如果频繁的编辑大文件,每编辑一次就要重新同步,岂不是会过度浪费空间!?举个例子:
本地有一个1G的大文件File1,已经同步到IPFS了,后面在这个文件File1后面追加了1K的内容,现在需要重新同步这个文件,算下来需要花费的空间应该是:1G+1G+1K;
然而,事实并非如此。IPFS在储存数据的时候,同一份数据只存储一次,文件是分块(block)存储的,hash相同的block,只会存储一次,也就说,前面1G的内容没有发生改变,其实IPFS并不会为这些数据分配新的空间,只会为最后1K的数据分配一个新的block,再重新上传hash,实际占用的空间是: 1G + 1K ;
不同的文件有很多数据是存在重复的,如不同语言字幕的电影,影音部分相同的,只有字幕部分不一样,当两个不同国家的人都在上传同一部电影的时候,这些文件在分块(block)的时候,很有可能有大部分block的hash是一致的,这些block在IPFS上也只会存储一份,这样一来就可能会有很多文件的索引指向同一个block,这里就构成了前面提到的一个数据结构——Merkle DAG(Merkle 有向无环图)。
因为所有的索引上都保存了hash,所以Merkle DAG具有以下特点(从白皮书上扒下来的):
1. 内容可寻址:所有内容都是被多重hash校验和来唯一识别的,包括links。
2. 无法篡改:所有的内容都用它的校验和来验证。如果数据被篡改或损坏,IPFS会检测到。
3. 重复数据删除:重复内容并只存储一次。
文件树存储
IPFS支持目录结构,存储目录的方式很简单:
先把目录下所有的文件同步到IPFS网络中去,为所有的文件hash建立一个别名,这个别名其实就是本地文件名,把hash和别名“捆绑”在一起组建成一个名为 IPFSLink 的对象;
把该目录下所有的 IPFSLink 对象组成一个数组,对该数组计算一个目录hash,并将数组和目录hash拼成一个结构体,同步到IPFS网络;
如果上层还有目录结构,则为目录hash建立一个别名(就是目录名),把目录hash和别名“捆绑”在一起组建成一个 IPFSLink 的对象,重复从步骤2开始执行;
把目录hash打印出来,读取的时候用;
由上可以看出,对于IPFS而言,存储目录和文件其实是一样的处理方式,IPFS甚至根本没有关心节点想要存储的是一个目录还是一个文件。
单文件读取
IPFS取文件的方式,就比较简单了,就是存储方式的一个逆推过程:
根据hash搜索该hash的索引结构,即找到该文件hash 的 block hash数组(这一步由IPFS网络完成,是旷工该干的事情),下载下来;此时已经得到了 block 的索引,根据block hash,搜索block所在的节点位置,下载下来;本地拼装block:根据block hash数组的顺序,把文件拼凑好。block的下载是IPFS的核心,这中间涉及到很多复杂的技术细节,因为个人能力有限,这里没有展开讨论,只是先一笔带过。希望不会误导新入门的读者,以为IPFS就只干了这么点事情!
文件树读取
目录的读取也是目录存储过程的逆推:
根据hash搜索该hash的索引结构,找到该目录的 IPFSLink 对象数组,即目录下的子列表;
遍历数组,如果IPFSLink对象是文件,则取出文件的hash下载该文件;
如果IPFSLink对象是目录,取出目录hash,重新从步骤1开始执行。
大致介绍IPFS文件存储于读取,磨链社区-陈狍子,原文链接:http://mochain.info/wordpress/index.php/2018/03/12/qian_xi_ipfs_de_cun_chu_yu_du_qu/
三年区块链相关政策