进程专栏 multiprocessing 高级模块
要让Python程序实现多进程(multiprocessing),我们先了解操作系统的相关知识。
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
Python的os模块封装了常见的系统调用,其中就包括fork,可以在Python程序中轻松创建子进程:
# unix 系 下
import os
print('进程 id {} 开启...'.format(os.getpid()))
pid = os.fork() # 开启新的进程,但仍是先有父进程
if pid == 0:
print('我是子进程 id ({}) 被父进程 id ({}) 创建'.format(os.getpid(),os.getppid())) # 是被开启的子进程
else:
print('我是父进程 id ({}) 创建了子进程 id ({})'.format(os.getpid(),pid)) # 父进程 用来开启别的进程
进程 id 5697 开启...
我是父进程 id (5697) 创建了子进程 id (7799)
我是子进程 id (7799) 被父进程 id (5697) 创建
import os
print("Process (%s) is start..." %os.getpid())
pid = os.fork()
print('pid: {}'.format(pid))
if pid == 0:
print('I am child process (%s) and my parent is %s.' % (os.getpid(), os.getppid()))
else:
print('I (%s) just created a child process (%s).' % (os.getpid(), pid))# 系统通用 导入 multiprocessing 模块
from multiprocessing import Process
import os
# 子进程要执行的代码
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
Parent process 5697.
Child process will start.
Run child process test (7870)...
Child process end.
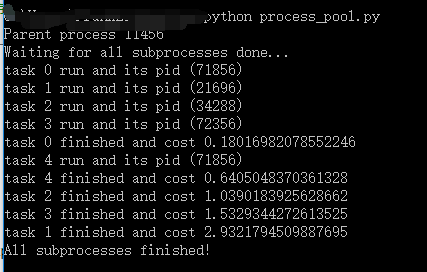
# 使用进程池 from multiprocessing import Pool
from multiprocessing import Pool
import os,time,random
def process_pool_task(name):
print('task {} run and its pid ({})'.format(name,os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('task {} finished and cost {}'.format(name,(end-start)))
if __name__ == '__main__':
print('Parent process %s' %os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(process_pool_task,args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses finished!')
# 子进程 ,这地方也不是很懂 用途是干嘛。。。
>>> import subprocess
>>> r = subprocess.call(['nslookup','www.baidu.com'])
Server: UnKnown
Address: 192.168.0.1
Non-authoritative answer:
Name: www.a.shifen.com
Addresses: 14.215.177.38
14.215.177.39
Aliases: www.baidu.com
>>> print('Exit code: {}'.format(r))
Exit code: 0# 这里用途很明显就是进程间通信一个造数据,一个消费数据
from multiprocessing import Process,Queue
import os,time,random
def write_queue(q):
print('write process ({}) start...'.format(os.getpid()))
for s in ['A','B','C','D']:
print('put value %s into queue...'%s)
q.put(s)
time.sleep(random.random() * 3)
def read_queue(q):
print('reading process ({}) start...'.format(os.getpid()))
while(True):
value = q.get(True)
print('Get value %s from queue'%value)
if __name__ == '__main__':
q = Queue()
pw = Process(target=write_queue, args=(q,))
pr = Process(target=read_queue, args=(q,))
pw.start()
pr.start()
pw.join()
pr.terminate()
reading process (8848) start...
write process (8847) start...
put value A into queue...
Get value A from queue
put value B into queue...
Get value B from queue
put value C into queue...
Get value C from queue
put value D into queue...
Get value D from queue
# 重写。。。
from multiprocessing import Process , Queue
import os, time , random
def write_queue(q):
print('write process ({}) start...'.format(os.getpid()))
for w in ['First','Second','Third']:
print('write process %s put %s into queue'%(os.getpid(),w))
q.put(w)
time.sleep(random.random() * 3)
def read_queue(q):
print('read process ({}) start...'.format(os.getpid()))
while True:
value = q.get(True)
print('read process {} get {} from queue'.format(os.getpid(),value))
if __name__ == '__main__':
q = Queue()
pw = Process(target=write_queue, args=(q,))
pr = Process(target=read_queue, args=(q,))
pw.start()
pr.start()
pw.join()
pr.terminate()
from multiprocessing import Process,Queue
import os,time,random
def write_queue(q):
words = [chr(i) for i in range(97,123)]
for word in words:
print('Process {} start to write word "{}" into queue...'.format(os.getpid(),word))
q.put(word)
time.sleep(random.random() * 3)
def read_queue(q):
while True:
word = q.get(True)
print('Process {} start to read word {} from queue...'.format(os.getpid(),word))
if __name__ == '__main__':
q = Queue()
pw = Process(target=write_queue,args=(q,))
pr = Process(target=read_queue,args=(q,))
pw.start()
pr.start()
pw.join()
pr.terminate()
线程专栏 threading 高级模块
>>> from threading import Thread,current_thread
>>> import time,random
>>> def thread_task():
... print('thread {} start...'.format(current_thread().name))
... for i in range(5):
... print('thread {} running...{}'.format(current_thread().name,i))
... print('thread {} finished...'.format(current_thread().name))
...
>>> for n in range(100):
... t = Thread(target=thread_task,name='thread task '+str(n))
... t.start()
... t.join()协程专栏 Coroutine
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('consumer processing n: {}'.format(n))
r = '200 ok!'
def producer(c):
#开启生成器 必须 send(None)
c.send(None)
for n in range(1,6,1):
print('producer processing n: {}'.format(n))
r = c.send(n)
print('consumer return r:{}'.format(r))
c.close()
c = consumer()
producer(c)扩展知识
扩展知识2
概念
进程是一个具有一定独立功能的程序关于某次数据集合的一次运行活动,它是操作系统分配资源的基本单元。它可以申请和拥有系统资源,是一个动态的概念,是一个活动的实体。它不只是程序的代码,还包括当前的活动,通过程序计数器的值和处理寄存器的内容来表示。进程的概念主要有两点:第一,进程是一个实体。每一个进程都有它自己的地址空间,一般情况下,包括文本段、数据段和堆栈段。文本段存储处理器执行的代码;数据段储变量和进程执行期间使用的动态分配的内存;堆栈段存储着活动过程调用的指令和本地变量。第二,进程是一个“执行中的程序”。程序是一个没有生命的实体,只有处理器赋予程序生命时(操作系统执行之),它才能成为一个活动的实体,我们称其为进程。
线程是进程的一个执行流,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组 成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。
协程是一种编译器级实现的用户态的轻量级线程,本质上讲只是线程的一种实现。相对于线程,协程也相对独立,有自己的上下文,但是其切换由程序自己控制。
image
以上是抽象概念,它们的特性也很大程度取决于具体实现(操作系统或者编译器)。比如LINUX的线程实现就和WINDOWS有很大不同,LINUX的线程其实是轻量级进程(Light Weight Process,LWP),GO的协程也和C#的协程不同。
如果把进程比作工厂里的一个车间,车间里有各种的原材料,设备,和工作人员等等。那么线程就是车间里的生产线,它们负责整个车间的生产工作,共享车间内的其它资源,一个车间最少有一个生产线,也可以有多个。协程就好像是生产线里更小的生产单位,能够被一些阀门控制。
从概念上看,协程其实是线程的一种实现,所以可以先简单的认为协程就是线程的一种。而多进程和多线程程序却有着比较大的区别。
进程的创建
在WINDOWS和LINUX下的进程创建不太一样。
LINUX的fork()是函数通过系统调用创建一个与原来进程几乎完全相同的进程,exec()则是用来启动另外的进程以取代当前运行的进程,一个进程一旦调用exec类函数,它本身就"死亡"了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号。
WINDOWS则是用CreateProccess()来创建一个新的进程,这个新进程运行指定的可执行文件,看上去效果和LINUX的fork()+exec()差不多,只是实现上不太相同。
线程的模型
多对一模型
将多个用户级线程映射到一个内核级线程,线程管理在用户空间完成,这种模型下操作系统并不知道多线程的存在。如的GO(1.5以前)就是这种模型。
优点:线程管理是在用户空间进行的,切换上下文开销比较小,性能较高。
缺点:当一个线程在使用内核服务时被阻塞,那么整个进程都会被阻塞;多个线程不能并行地运行在多处理机上。
一对一模型
将每个用户级线程映射到一个内核级线程。Java的线程就属于这种模型。
优点:当一个线程被阻塞后,允许另一个线程继续执行,所以并发能力较强;能很好的利用到CPU的多核心。
缺点:每创建一个用户级线程都需要创建一个内核级线程与其对应,这样创建线程的开销比较大,会影响到应用程序的性能。并且切换线程要进出内核,代价比较大。
多对多模型
将n个用户级线程映射到m个内核级线程上,要求 m <= n。GO(1.5之后)的协程就属于这种线程模型。
特点:既克服了多对一模型的并发度不高的缺点,又克服了一对一模型的一个用户进程占用太多内核级线程,开销太大的缺点。又拥有多对一模型和一对一模型各自的优点。
进程和线程的区别
进程间是完全独立的个体,多进程环境中,任何一个进程终止不会影响其他进程,而多线程环境中任何一个线程执行exit系统调用,则所有线程退出,最常见的是因某个线程异常导致程序的退出。
通信方式,进程间通信(IPC:无名管道,有名管道,消息队列,信号,信号量,共享内存等)较为复杂,线程间可以直接读写进程数据段(如全局变量)来进行通信(需要线程同步和互斥手段的辅助,以保证数据的一致性)。
线程比进程轻,不管是创建还是上下文切换,线程的开销都要比进程小。