简介:上一节,我们讲过Solidity 汇编语言,这个汇编语言,可以不同Solidity一起使用。这个汇编语言还可以嵌入到Solidity源码中,以内联汇编的方式使用。下面我们将从内联汇编如何使用着手,介绍其与独立使用的汇编语言的不同,最后再介绍这门汇编语言。
Solidity Assembly
内联汇编
通常我们通过库代码,来增强语言我,实现一些精细化的控制,Solidity为我们提供了一种接近于EVM底层的语言,内联汇编,允许与Solidity结合使用。由于EVM是栈式的,所以有时定位栈比较麻烦,Solidty的内联汇编为我们提供了下述的特性,来解决手写底层代码带来的各种问题:
- 允许函数风格的操作码:mul(1, add(2, 3))等同于push1 3 push1 2 add push1 1 mul
- 内联局部变量:let x := add(2, 3) let y := mload(0x40) x := add(x, y)
- 可访问外部变量:function f(uint x) { assembly { x := sub(x, 1) } }
- 标签:let x := 10 repeat: x := sub(x, 1) jumpi(repeat, eq(x, 0))
- 循环:for { let i := 0 } lt(i, x) { i := add(i, 1) } { y := mul(2, y) }
- switch语句:switch x case 0 { y := mul(x, 2) } default { y := 0 }
-
函数调用:function f(x) -> y { switch x case 0 { y := 1 } default { y := mul(x, f(sub(x, 1))) } }
下面将详细介绍内联编译(inline assembly)语言。
需要注意的是内联编译是一种非常底层的方式来访问EVM虚拟机。他没有Solidity提供的多种安全机制。
示例
下面的例子提供了一个库函数来访问另一个合约,并把它写入到一个bytes变量中。有一些不能通过常规的Solidity语言完成,内联库可以用来在某些方面增强语言的能力。pragma solidity ^0.4.0; library GetCode { function at(address _addr) returns (bytes o_code) { assembly { // retrieve the size of the code, this needs assembly let size := extcodesize(_addr) // allocate output byte array - this could also be done without assembly // by using o_code = new bytes(size) o_code := mload(0x40) // new "memory end" including padding mstore(0x40, add(o_code, and(add(add(size, 0x20), 0x1f), not(0x1f)))) // store length in memory mstore(o_code, size) // actually retrieve the code, this needs assembly extcodecopy(_addr, add(o_code, 0x20), 0, size) } } }内联编译在当编译器没办法得到有效率的代码时非常有用。但需要留意的是内联编译语言写起来是比较难的,因为编译器不会进行一些检查,所以你应该只在复杂的,且你知道你在做什么的事情上使用它。
pragma solidity ^0.4.0; library VectorSum { // This function is less efficient because the optimizer currently fails to // remove the bounds checks in array access. function sumSolidity(uint[] _data) returns (uint o_sum) { for (uint i = 0; i < _data.length; ++i) o_sum += _data[i]; } // We know that we only access the array in bounds, so we can avoid the check. // 0x20 needs to be added to an array because the first slot contains the // array length. function sumAsm(uint[] _data) returns (uint o_sum) { for (uint i = 0; i < _data.length; ++i) { assembly { o_sum := mload(add(add(_data, 0x20), mul(i, 0x20))) } } } }语法
内联编译语言也会像Solidity一样解析注释,字面量和标识符。所以你可以使用//和/**/的方式注释。内联编译的在Solidity中的语法是包裹在assembly { ... },下面是可用的语法,后续有更详细的内容。 - 字面量。如0x123,42或abc(字符串最多是32个字符)
- 操作码(指令的方式),如mload sload dup1 sstore,后面有可支持的指令列表
- 函数风格的操作码,如add(1, mlod(0)
- 标签,如name:
- 变量定义,如let x := 7 或 let x := add(y, 3)
- 标识符(标签或内联局部变量或外部),如jump(name),3 x add
- 赋值(指令风格),如,3 =: x。
- 函数风格的赋值,如x := add(y, 3)
- 支持块级的局部变量,如{ let x := 3 { let y := add(x, 1) } }
操作码
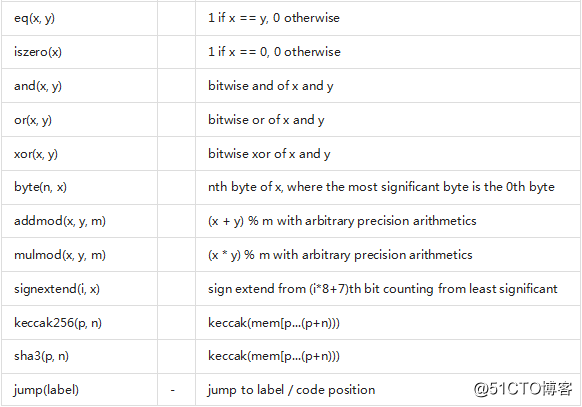
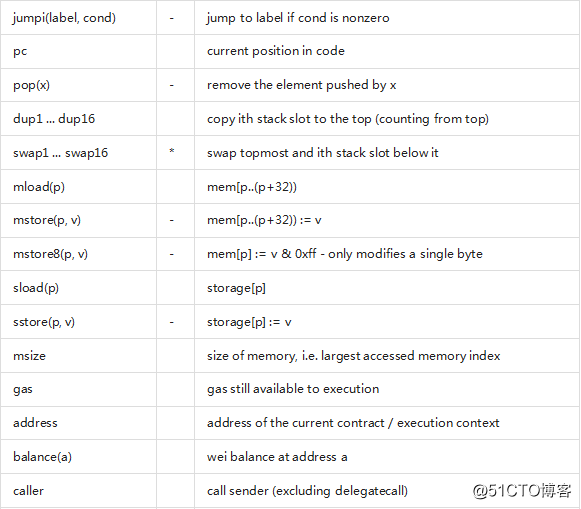
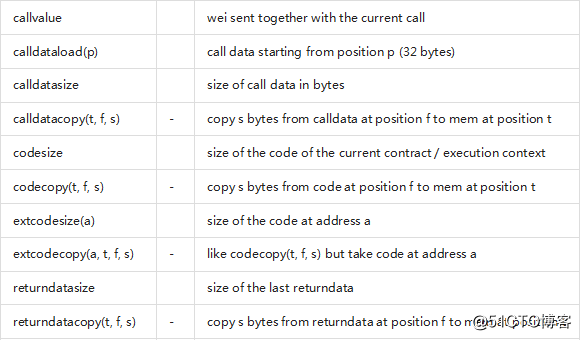
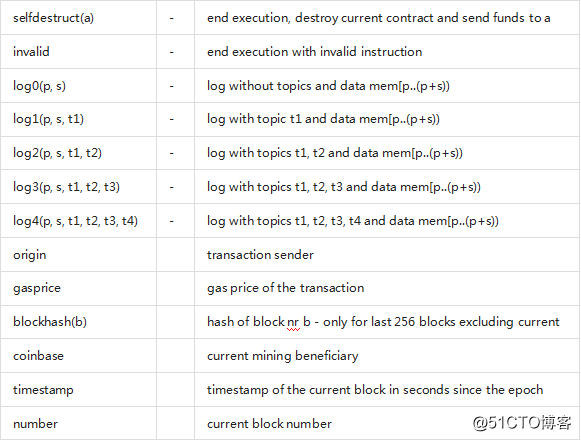
这个文档不想介绍EVM虚拟机的完整描述,但后面的列表可以做为EVM虚拟机的指令码的一个参考。
如果一个操作码有参数(通过在栈顶),那么他们会放在括号。需要注意的是参数的顺序可以颠倒(非函数风格,后面会详细说明)。用-标记的操作码不会将一个参数推到栈顶,而标记为*的是非常特殊的,所有其它的将且只将一个推到栈顶。
在后面的例子中,mem[a...b)表示成位置a到位置b(不包含)的memory字节内容,storage[p]表示在位置p的strorage内容。
操作码pushi和jumpdest不能被直接使用。
在语法中,操作码被表示为预先定义的标识符。




字面量
你可以使用整数常量,通过直接以十进制或16进制的表示方式,将会自动生成恰当的pushi指令。
assembly { 2 3 add "abc" and }
上面的例子中,将会先加2,3得到5,然后再与字符串abc进行与运算。字符串按左对齐存储,且不能超过32字节。
函数风格
你可以在操作码后接着输入操作码,它们最终都会生成正确的字节码。比如:
3 0x80 mload add 0x80 mstore
下面将会添加3与memory中位置0x80的值。
由于经常很难直观的看到某个操作码真正的参数,Solidity内联编译提供了一个函数风格的表达式,上面的代码与下述等同:
mstore(0x80, add(mload(0x80), 3))
函数风格的表达式不能在内部使用指令风格,如1 2 mstore(0x80, add)将不是合法的,必须被写为mstore(0x80, add(2, 1))。那些不带参数的操作码,括号可以忽略。
需要注意的是函数风格的参数与指令风格的参数是反的。如果使用函数风格,第一个参数将会出现在栈顶。
访问外部函数与变量
Solidity中的变量和其它标识符,可以简单的通过名称引用。对于memory变量,这将会把地址而不是值推到栈上。Storage的则有所不同,由于对应的值不一定会占满整个storage槽位,所以它的地址由槽和实际存储位置相对起始字节偏移。要搜索变量x指向的槽位,使用x_slot,得到变量相对槽位起始位置的偏移使用x_offset。
在赋值中(见下文),我们甚至可以直接向Solidity变量赋值。
还可以访问内联编译的外部函数:内联编译会推入整个的入口的label(应用虚函数解析的方式)。Solidity中的调用语义如下:
- 调用者推入返回的label,arg1,arg2, ... argn
- 调用返回ret1,ret2,..., retm
这个功能使用起来还是有点麻烦,因为堆栈偏移量在调用过程中基本上有变化,因此对局部变量的引用将是错误的。
pragma solidity ^0.4.11;
contract C {
uint b;
function f(uint x) returns (uint r) {
assembly {
r := mul(x, sload(b_slot)) // ignore the offset, we know it is zero
}
}
}标签
另一个在EVM的汇编的问题是jump和jumpi使用了绝对地址,可以很容易的变化。Solidity内联汇编提供了标签来让jump跳转更加容易。需要注意的是标签是非常底层的特性,尽量使用内联汇编函数,循环,Switch指令来代替。下面是一个求Fibonacci的例子:
{
let n := calldataload(4)
let a := 1
let b := a
loop:
jumpi(loopend, eq(n, 0))
a add swap1
n := sub(n, 1)
jump(loop)
loopend:
mstore(0, a)
return(0, 0x20)
}需要注意的是自动访问栈元素需要内联者知道当前的栈高。这在跳转的源和目标之间有不同栈高时将失败。当然你也仍然可以在这种情况下使用jump,但你最好不要在这种情况下访问栈上的变量(即使是内联变量)。
此外,栈高分析器会一个操作码接着一个操作码的分析代码(而不是根据控制流),所以在下面的情况下,汇编程序将对标签two的堆栈高度产生错误的判断:
{
let x := 8
jump(two)
one:
// Here the stack height is 2 (because we pushed x and 7),
// but the assembler thinks it is 1 because it reads
// from top to bottom.
// Accessing the stack variable x here will lead to errors.
x := 9
jump(three)
two:
7 // push something onto the stack
jump(one)
three:
}这个问题可以通过手动调整栈高来解决。你可以在标签前添加栈高需要的增量。需要注意的是,你没有必要关心这此,如果你只是使用循环或汇编级的函数。
下面的例子展示了,在极端的情况下,你可以通过上面说的解决这个问题:
{
let x := 8
jump(two)
0 // This code is unreachable but will adjust the stack height correctly
one:
x := 9 // Now x can be accessed properly.
jump(three)
pop // Similar negative correction.
two:
7 // push something onto the stack
jump(one)
three:
pop // We have to pop the manually pushed value here again.
}定义汇编-局部变量
你可以通过let关键字来定义在内联汇编中有效的变量,实际上它只是在{}中有效。内部实现上是,在let指令出现时会在栈上创建一个新槽位,来保存定义的临时变量,在块结束时,会自动在栈上移除对应变量。你需要为变量提供一个初始值,比如0,但也可以是复杂的函数表达式:
pragma solidity ^0.4.0;
contract C {
function f(uint x) returns (uint b) {
assembly {
let v := add(x, 1)
mstore(0x80, v)
{
let y := add(sload(v), 1)
b := y
} // y is "deallocated" here
b := add(b, v)
} // v is "deallocated" here
}
}赋值
你可以向内联局部变量赋值,或者函数局部变量。需要注意的是当你向一个指向memory或storage赋值时,你只是修改了对应指针而不是对应的数据。
有两种方式的赋值方式:函数风格和指令风格。函数风格,比如variable := value,你必须在函数风格的表达式中提供一个变量,最终将得到一个栈变量。指令风格=: variable,值则直接从栈底取。以于两种方式冒号指向的都是变量名称(译者注:注意语法中冒号的位置)。赋值的效果是将栈上的变量值替换为新值。
assembly {
let v := 0 // functional-style assignment as part of variable declaration
let g := add(v, 2)
sload(10)
=: v // instruction style assignment, puts the result of sload(10) into v
}Switch
你可以使用switch语句来作为一个基础版本的if/else语句。它需要取一个值,用它来与多个常量进行对比。每个分支对应的是对应切尔西到的常量。与某些语言容易出错的行为相反,控制流不会自动从一个判断情景到下一个场景(译者注:默认是break的)。最后有个叫default的兜底。
assembly {
let x := 0
switch calldataload(4)
case 0 {
x := calldataload(0x24)
}
default {
x := calldataload(0x44)
}
sstore(0, div(x, 2))
}可以有的case不需要包裹到大括号中,但每个case需要用大括号的包裹。
循环
内联编译支持一个简单的for风格的循环。for风格的循环的头部有三个部分,一个是初始部分,一个条件和一个后叠加部分。条件必须是一个函数风格的表达式,而其它两个部分用大括号包裹。如果在初始化的块中定义了任何变量,这些变量的作用域会被默认扩展到循环体内(条件,与后面的叠加部分定义的变量也类似。译者注:因为默认是块作用域,所以这里是一种特殊情况)。
assembly {
let x := 0
for { let i := 0 } lt(i, 0x100) { i := add(i, 0x20) } {
x := add(x, mload(i))
}
}函数
汇编语言允许定义底层的函数。这些需要在栈上取参数(以及一个返回的代码行),也会将结果存到栈上。调用一个函数与执行一个函数风格的操作码看起来是一样的。
函数可以在任何地方定义,可以在定义的块中可见。在函数内,你不能访问一个在函数外定义的一个局部变量。同时也没有明确的return语句。
如果你调用一个函数,并返回了多个值,你可以将他们赋值给一个元组,使用a, b := f(x)或let a, b := f(x)。
下面的例子中通过平方乘来实现一个指数函数。
assembly {
function power(base, exponent) -> result {
switch exponent
case 0 { result := 1 }
case 1 { result := base }
default {
result := power(mul(base, base), div(exponent, 2))
switch mod(exponent, 2)
case 1 { result := mul(base, result) }
}
}
}内联汇编中要注意的事
内联汇编语言使用中需要一个比较高的视野,但它又是非常底层的语法。函数调用,循环,switch被转换为简单的重写规则,另外一个语言提供的是重安排函数风格的操作码,管理了jump标签,计算了栈高以方便变量的访问,同时在块结束时,移除块内定义的块内的局部变量。特别需要注意的是最后两个情况。你必须清醒的知道,汇编语言只提供了从开始到结束的栈高计算,它没有根据你的逻辑去计算栈高(译者注:这常常导致错误)。此外,像交换这样的操作,仅仅交换栈里的内容,并不是变量的位置。
Solidity中的惯例
与EVM汇编不同,Solidity知道类型少于256字节,如,uint24。为了让他们更高效,大多数的数学操作仅仅是把也们当成是一个256字节的数字进行计算,高位的字节只在需要的时候才会清理,比如在写入内存前,或者在需要比较时。这意味着如果你在内联汇编中访问这样的变量,你必须要手动清除高位的无效字节。
Solidity以非常简单的方式来管理内存:内部存在一个空间内存的指针在内存位置0x40。如果你想分配内存,可以直接使用从那个位置的内存,并相应的更新指针。
Solidity中的内存数组元素,总是占用多个32字节的内存(也就是说byte[]也是这样,但是bytes和string不是这样)。多维的memory的数组是指向memory的数组。一个动态数组的长度存储在数据的第一个槽位,紧接着就是数组的元素。
固定长度的memory数组没有一个长度字段,但它们将很快增加这个字段,以让定长与变长数组间有更好的转换能力,所以请不要依赖于这点。
参考内容:https://open.juzix.net/doc
智能合约开发教程视频:区块链系列视频课程之智能合约简介