1、概述:
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
MR由两个阶段组成:Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
这两个函数的形参是key、value对,表示函数的输入信息。
2、Mapreduce原理:
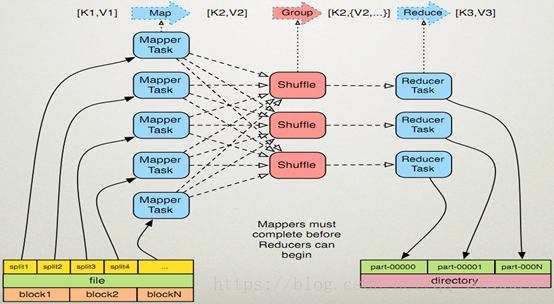
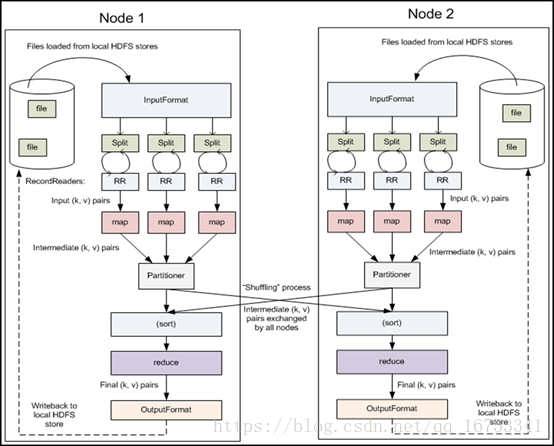
3、执行步骤:
一、map任务处理
1.1读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
二、2.reduce任务处理
2.1在reduce之前,有一个shuffle的过程对多个map任务的输出进行合并、排序。
2.2写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
2.3把reduce的输出保存到文件中。

4、WordCount例子:
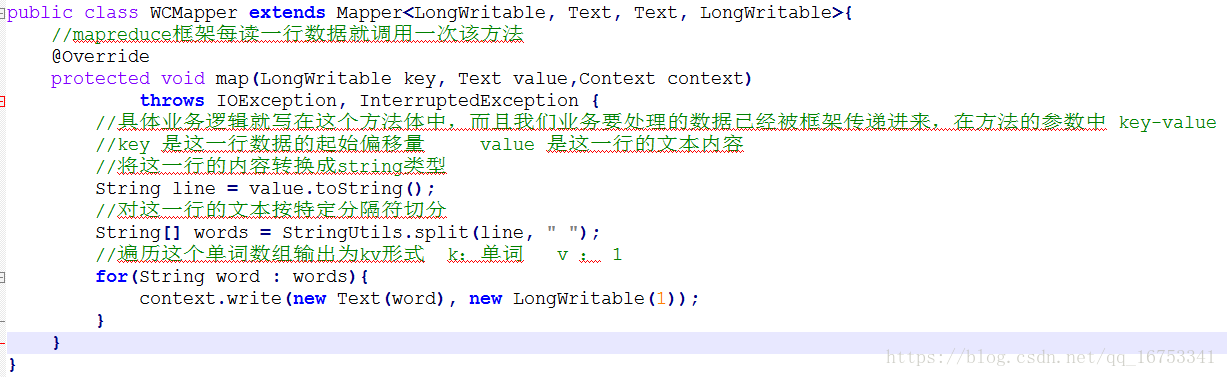
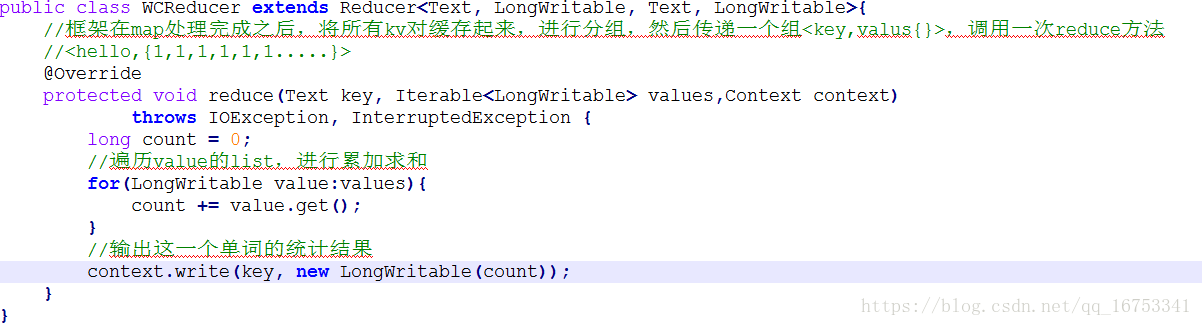
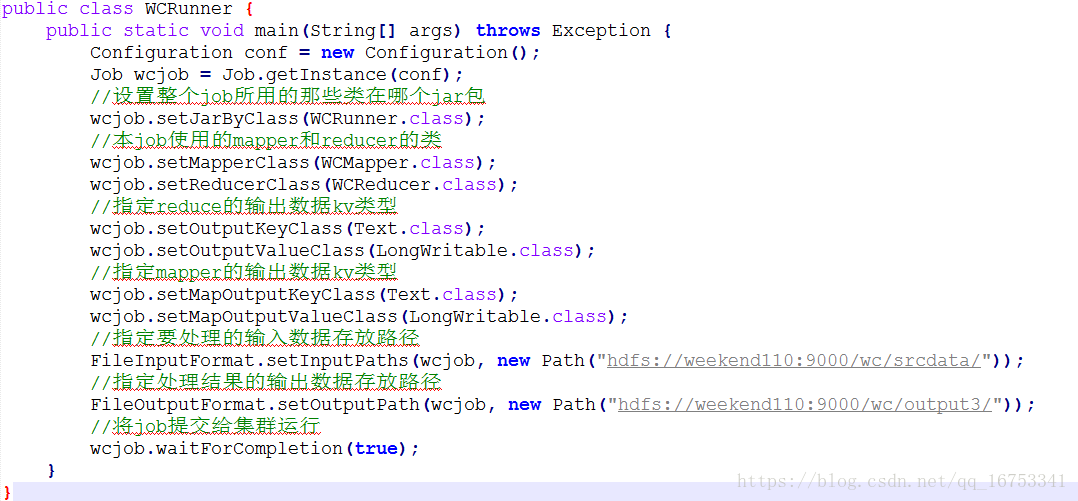
5、Mapreduce流程
1) 代码编写
2) 作业配置
3) 提交作业
4) 初始化作业
5) 分配任务
6) 执行任务
7) 更新任务和状态
8) 完成作业
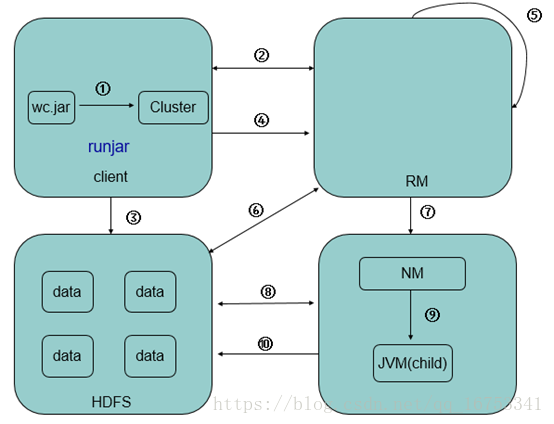
6、MR过程各个角色的作用:
Ø jobClient:提交作业
Ø JobTracker:初始化作业,分配作业,TaskTracker与其进行通信,协调监控整个作业
Ø TaskTracker:定期与JobTracker通信,执行Map和Reduce任务
Ø HDFS:保存作业的数据、配置、jar包、结果
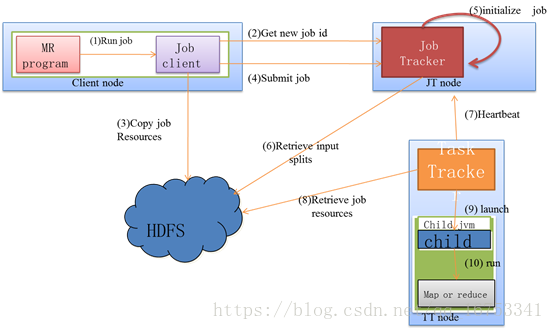
7、MR任务分配执行状态更新
1) TaskTracker与JobTracker之间的通信和任务分配是通过心跳机制实现的。
2) TaskTracker会主动定期向JobTracker发送心态信息,询问是否有任务要做,如果有,就会申请到任务。
3) 如果TaskTracker拿到任务,会将所有的信息拷贝到本地,包括代码、配置、分片信息等。
4) TaskTracker中的localizeJob()方法会被调用进行本地化,拷贝job.jar,jobconf,job.xml到本地。
5) TaskTracker调用launchTaskForJob()方法加载启动任务。
6) MapTaskRunner和ReduceTaskRunner分别启动javachild进程来执行相应的任务。
7) Task会定期向TaskTraker汇报执行情况。
8) TaskTracker会定期收集所在集群上的所有Task的信息,并向JobTracker汇报。
9) JobTracker会根据所有TaskTracker汇报上来的信息进行汇总。
10) JobTracker是在接收到最后一个任务完成后,才将任务标记为成功。
11) 将数结果据写入到HDFS中。
8、JobTracker
负责接收用户提交的作业,负责启动、跟踪任务执行。
JobSubmissionProtocol是JobClient与JobTracker通信的接口。
InterTrackerProtocol是TaskTracker与JobTracker通信的接口。
TaskTracker负责执行任务。
JobClient负责提交作业的,负责启动、跟踪任务执行、访问任务状态和日志等。
Jobtracker调用顺序:main --> startTracker --> new JobTracker 在其构造方法中首先创建一个调度器,接着创建一个RPC的server(interTrackerServer)tasktracker会通过PRC机制与其通信
然后调用offerService方法对外提供服务,在offerService方法中启动RPC server,初始化jobtracker,调用taskScheduler的start方法 -->eagerTaskInitializationListener调用start方法,
--> 调用jobInitManagerThread的start方法,因为其是一个线程,会调用JobInitManager的run方法 --> jobInitQueue任务队列去取第一个任务,然后把它丢入线程池中,然后调用-->InitJob的run方法
--> jobTracker的initJob方法 --> JobInProgress的initTasks --> maps = new TaskInProgress[numMapTasks]和reduces = new TaskInProgress[numReduceTasks];
TaskTracker调用顺序:main--> new TaskTracker在其构造方法中调用了initialize方法,在initialize方法中调用RPC.waitForProxy得到一个jobtracker的代理对象
接着TaskTracker调用了本身的run方法,--> offerService方法 --> transmitHeartBeat返回值是(HeartbeatResponse)是jobTracker的指令,在transmitHeartBeat方法中InterTrackerProtocol调用了heartbeat将tasktracker的状态通过RPC机制发送给jobTracker,返回值就是JobTracker的指令
heartbeatResponse.getActions()得到具体的指令,然后判断指令的具体类型,开始执行任务
addToTaskQueue启动类型的指令加入到队列当中,TaskLauncher又把任务加入到任务队列当中,--> TaskLauncher的run方法 --> startNewTask方法 --> localizeJob下载资源 --> launchTaskForJob开始加载任务 -->launchTask --> runner.start()启动线程; --> TaskRunner调用run方法 --> launchJvmAndWait启动java child进程
9、序列化概念
序列化(Serialization)是指把结构化对象转化为字节流。
反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。
Java序列化(java.io.Serializable)
Hadoop序列化的特点:
1. 紧凑:高效使用存储空间。
2. 快速:读写数据的额外开销小
3. 可扩展:可透明地读取老格式的数据
4. 互操作:支持多语言的交互
序列化在分布式环境的两大作用:进程间通信,永久存储。
Hadoop节点间通信:

Writable接口:
Writable接口, 是根据 DataInput 和 DataOutput 实现的简单、有效的序列化对象.
MR的任意Key和Value必须实现Writable接口.


InputSplit:
为什么hadoop在处理很多小文件时效率不高?
Ø 在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
Ø FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
Ø 如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
Ø 当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。
例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
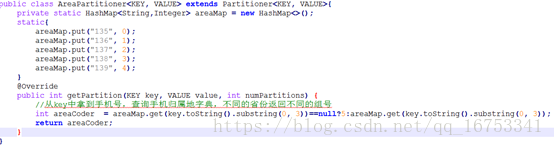
10、Partitioner编程(可以实现输出数据的分组)
Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类。
HashPartitioner是mapreduce的默认partitioner。计算方法是
which reducer=(key.hashCode() & Integer.MAX_VALUE) %numReduceTasks,得到当前的目的reducer。
在main中指定用的Partitioner,在map输出结果将调用我们指定的reduce。而每个ruduce都有自己的输出文件。

设置Reducer的数量,job.setNumReduceTasks(6);
11、Combiners编程(提高效率,减少传输)
每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。
combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。
如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reducer的输入,如果Combiner是可插拔的,添加Combiner绝不能改变最终的计算结果。所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
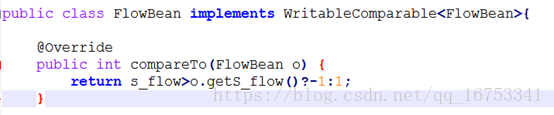
12、排序:
排序MR默认是按key2进行排序的,如果想自定义排序规则,被排序的对象要实现WritableComparable接口,在compareTo方法中实现排序规则,然后将这个对象当做k2,即可完成排序
13、Shuffle(洗牌或弄乱)

map()->shuffle->reduce()
1) map()输出结果->内存(环形缓冲区,当内存大小达到指定数值,如80%,开始溢写到本地磁盘)
2) 溢写之前,进行了分区partition操作,分区的目的在于数据的reduce指向,分区后进行二次排序,第一次是对partitions进行排序,第二次对各个partition中的数据进行排序,之后如果设置了combine,就会执行类似reduce的合并操作,还可以再进行压缩,因为reduce在拷贝文件时消耗的资源与文件大小成正比
3) 内存在达到一定比例时,开始溢写到磁盘上
4) 当文件数据达到一定大小时,本地磁盘上会有很多溢写文件,需要再进行合并merge成一个文件
5) reduce拷贝copy这些文件,然后进行归并排序(再次merge),合并为一个文件作为reduce的输入数据
更加详细的解释:https://blog.csdn.net/zengxiaosen/article/details/73189207
14、Job执行流程图
15、MapReduce的输出进行压缩

