(这里的零拷贝指的是可以不需要cpu参与的拷贝)
许多web应用提供大量的静态内容服务,这意味着服务器要从硬盘读取内容并将完全相同的内容写到response的socket中。此活动过程看起来只要少量的cpu活动,但它的效率非常低下:操作系统内核从硬盘读取数据,然后将这些数据通过内核-用户边界传递给应用程序,然后应用程序又将读取到的数据再次通过内核-用户边界来写入内核中的socket。从这个过程中我们看到,在整个数据从硬盘文件中读取,然后写入socket,应用程序是作为一个非常低效的媒介存在。
每次数据通过内核-用户边界时,数据都必须被拷贝一次,这消耗了一定的cpu时钟周期和内存。幸运地是,通过zero-copy的技术你完全可以省略掉这些不必要的拷贝操作。使用zero-copy的应用程序可以请求内核直接将硬盘中的数据拷贝到socket中,而不需要经过应用程序这个中间层。zero-copy大大提升了应用程序的性能而且减少了操作系统在内核态和用户态之间切换的次数。
java类库通过FileChannel类中的transferIo()方法来支持zero-copy。通过此方法可以直接将字节从一个通道传输到另一个可写的通道,而不需要经过应用程序。本文首先演示通过传统的复制语义完成简单文件传输所产生的开销,然后展示zero-copy的技术带来了怎样的性能提升。
数据传输:传统实现
考虑一下从文件中读取数据然后通过网络传输到另一个程序的场景(这个场景描述了很多服务应用的行为,包括提供静态页面的web服务,ftp服务,邮件服务,等等)。这个操作的核心是通过Listing1描述的两个调用来实现的:
Listing 1:
File.read(fileDesc, buf, len);
Socket.send(socket, buf, len);
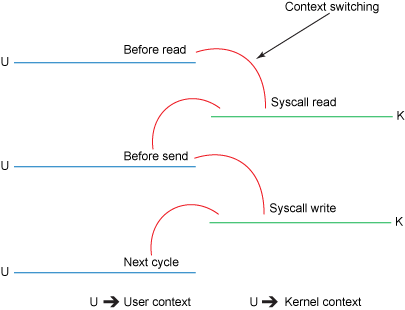
尽管Listing 1的操作看起来很简单,但其实,在整个操作完成之前,一共经历了四次内核态和用户态的转换和四次拷贝操作。图1将显示数据如何从文件转移到socket。
Figure 1. 传统数据拷贝实现
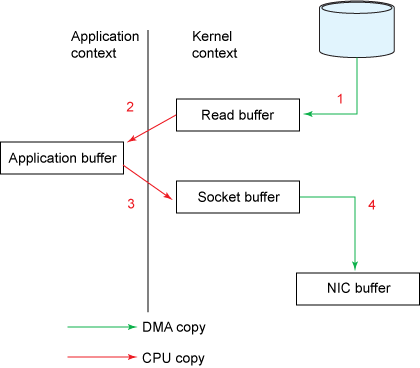
图2将显示操作中的上下文切换过程:
Figure 2. 传统的上下文切换
涉及的步骤如下:
1.read()调用会导致从内核态到用户态的上下文切换(如图2)。内部实现是通过调用sys_read()来从文件中读取数据。第一次拷贝由直接内存访问(DMA)引擎来完成,它会从硬盘上读取文件内容然后将这些读取到的数据存储在内核的一个缓存区read buffer(缓存区的设计是为了提升顺序访问和小文件访问的性能)中。
2.请求的数据然后又从read buffer也就是内核缓存区拷贝到user buffer也就是用户缓存区中,然后read()方法返回。返回操作会导致第二次的从内核态到用户态的上下文切换。现在我们需要的数据被存储在用户缓存区中,现在应用程序可以直接操作这些数据。
3.socket的send()调用会引起第三次的从用户态到内核态的上下文转换。然后第三次拷贝发生,数据将从user buffer拷贝到内核中的缓存区,但这个缓存区的地址和第一步中的read buffer不同,而是一个和目标套接字关联的内核缓存区,我们称之为socket buffer。
4.send()系统调用返回,会导致第四次的从内核态到用户态的上下文切换。当DMA引擎将数据从内核缓冲区传递到协议引擎时,会发生第四次复制,这个过程是异步(相对于应用程序的调用指令)进行地。
通过上面的介绍,内核中的缓存区看起来似乎非常低效,还不如直接将数据直接从硬盘中传输到用户缓存区中。但其实内核缓存区在很多时候是非常有用的,它被引入到操作系统中就是为了提升io的性能表现的。因为大多数的io操作为顺序操作,当一次io调用时,内核将本次调用的所需的数据所在的数据页和之后的几个数据页都放入缓存区中,这样下次io访问到来之时,就可以不用进行低效的硬盘访问了,而是直接命中缓存区中的数据,然后将缓存区中的数据拷贝到用户缓存区中,这是为了平衡硬盘访问效率低的一种措施。事实上,在请求数据为小文件或者请求的io操作为顺序操作时,内核的缓存区是非常有效的。而且内核缓存区的存在也为写操作的异步进行提供了基础。
然而不幸的是,当请求数据所在的文件远大于内核缓存区的大小时,内核缓存区的存在本身也会成为性能瓶颈。在将数据完全递送到应用程序之前,数据在硬盘,内核缓存区,用户缓存区中进行了大量的复制。(其实如果是顺序访问的话,从硬盘到内核缓存区的复制大部分时候都是异步的,此时就算是大文件,也不会有多大的性能影响,具体参考:
https://tech.meituan.com/about-desk-io.html)
Zero-copy通过省略掉不必要的拷贝操作提升了性能。
数据传输:zero-copy实现
如果你再考虑下上面介绍的数据传输的传统实现方法,你会发现,第二次和第三次数据复制完全是不必要的,在这个过程中的中间层应用程序没有对数据进行任何操作,仅仅是缓存内核缓存区中的数据然后又将这些缓存数据再传输到内核中的socket buffer中。实际上,数据完全可以直接从read buffer转移到socket buffer。transferInto()方法功能实际上就是和这一样的。Listing 2显示了transferInto()的方法签名:
Listing 1: the transferInto() method
public void transferTo(long position, long count, WritableByteChannel target);
transferInto()方法将数据从一个文件通道转移到另一个可写字节通道。在内部具体实现上依赖于底层操作系统对zero-copy的支持;在unix和各种类型的linux中,这个方法调用会引起sendfile()的系统调用,如下Listing 3的描述,它会将数据从一个文件描述符转移到另一个文件描述符。
Listing 1: the sendfile() system call
#include <
sys
/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
在Listing 1中的file.read()和socket.send()方法调用可以通过
transferInto()方法调用来代替,如Listing 4:
Listing 4. Using transferInto
() to copy data from a disk file to a socket
transferTo(position, count, writableChannel);
图3显示了
transferInto()方法调用时的数据流转路径:
Figure 3. Data copy with
transferInto()
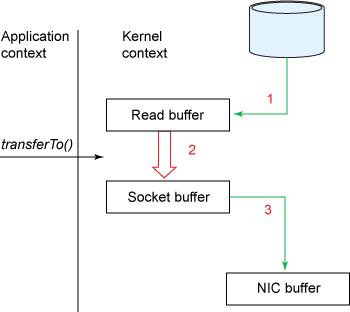
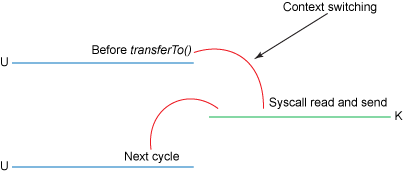
图4显示了
transferInto()方法调用时的上下文切换:
Figure 4. Context switch with
transferInto()
在Listing 4中使用
transferInto()方法时,内部主要经历了以下几个步骤:
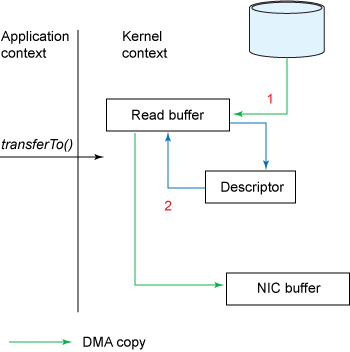
1.transferInto()方法导致DMA引擎将文件内容数据拷贝到read buffer中,然后read buffer中的数据又被拷贝到关联一个输出socket的内核缓
存区中,就是我们之前称的socket buffer。
2.第三次拷贝发生在DMA引擎将数据从socket buffer传送到NIC buffer中。
现在,相比之前传统的数据传输方式,我们有了一点优化:我们将系统在内核态和用户态之间的上下文切换次数从4次减少到2次,将数据拷贝从四次减少到三次(现在只有第二次复制需要cpu资源,其他复制都是DMA引擎执行,不耗费cpu资源)。但是这还没有达到我们的zero-copy的目的。如果底层网卡支持gather operation,我们可以进一步减少内核所做的数据复制。在Linux内核2.4和更高版本中,套接字缓冲区描述符已被修改以适应此要求。这样的话,不仅可以减少多个上下文切换,还可以消除需要CPU参与的重复数据拷贝。用户层面的用例和之前一样,但底层实现却发生了一些变化:
1.
transferInto()方法导致DMA引擎将文件内容数据拷贝到read buffer中
2.此时不会有任何数据被拷贝进socket buffer, 取而代之的是携带了数据的位置和长度的信息的描述符。DMA引擎直接将数据从read buffer
转移到NIC buffer。由此,消除了最后的需要cpu参与的拷贝操作。
图5显示了有了
gather operation支持后的transferInto()方法调用时的数据拷贝情况:
Figure 5. Data copy with
transferInto() and gather operation are used