此内容之前是1快速入门和2列表数据,链接已经在后面了,欢迎一起交流学习!0(≧▽≦)0:
https://www.cnblogs.com/sebastiane-root/p/9175575.html
3结构化数据
字典(查找表)、集合、元组、列表
3.1字典
是有两列任意多行的表,第一列存储一个键,第二列存储一个值。
它存储键/值对,每个唯一的键有一个唯一与之关联的值。(类似于映射、表)
它不会维持插入时的顺序。
Python的字典实现为一个大小可变的散列表,它针对大量特殊情况进行了充分的优化。因此,字典可以非常快速的完成查找。
For循环可以用来迭代处理一个字典。每次迭代时,键会赋给循环变量,用来访问数据值。
''' 字典的存储结构: 各个键与相应的值用:连接; 每个值与下一个值之间用逗号连接; 开始结束用大括号{}包围 ''' person3={'Name':'ting', 'Genger':'male', 'Occupation':'Researcher', 'Home Planet':'shaanxi province'} #在查看person3时,不是按照定义的顺序,字典中的数据是无序的。 #使用键来访问字典中的数据。 person3['Home Planet'] #会显示shaanxi province Person3[‘Age’]=33 #向字典增加一行数据,将一个对象赋值一个新键。
回顾vowels3.py程序:
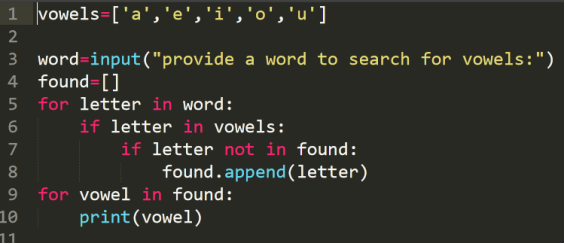
它返回的是一个单词中的元音:

而现在需要一个新的功能是列出任意一个单词中的元音以及它出现的频度。
下面研究使用字典来改进这个元音程序:
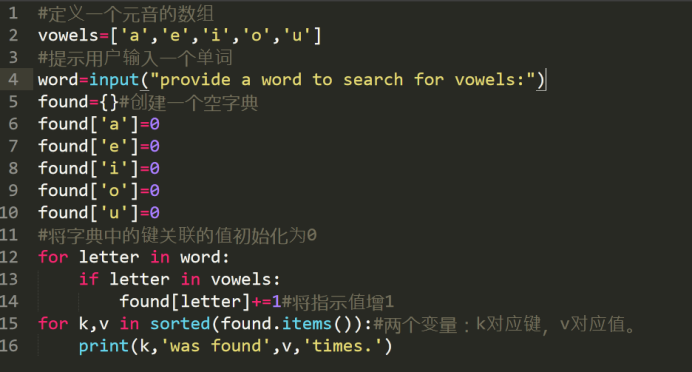
1.如何把这个字典初始化,使其中的值都为0?

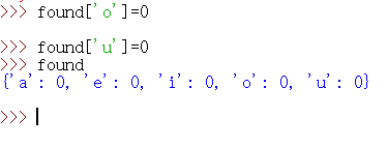
2.如何递增字典中的值?

‘e’对应的数字已经变成2
3.如何迭代处理字典?
用for处理字典时,解释器只处理字典的键,而不处理值。

4.如何指定输出时的顺序?
使用sorted(found) #sorted是一个内置函数,可按照字母顺序组织输出。
用items迭代处理字典:
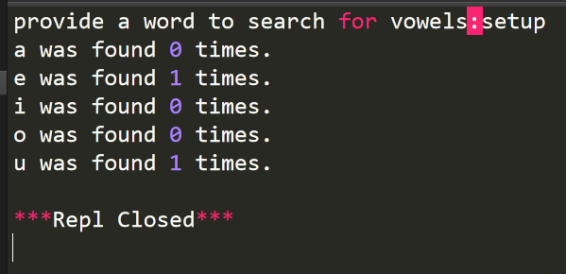
执行结果:
使用setdefault:为了缩短代码,减少初始化的语句,先判断键的存在并初始化。

键必须初始化!!!

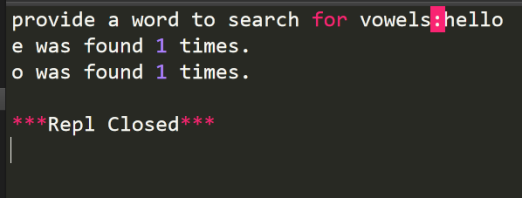
只打印单词中出现的元音。这样不会输出无意义的结果。
指令:
setdefault()访问一个键之前需要确保它的存在
对于使用 if 'pear' not in fruits:
fruits['pear']=0 来初始化相比,setdefault更简单。
items()迭代处理字典。
sorted()排序。
3.2集合(set)
集合的查找速度快于列表,不允许有重复值。用’{ }’包围,对象之间用’,’分隔,
1合并集合:union

Union将一个集合与另一个集合合并,再把合并结果赋给一个新变量u,
u集合由两个集合中所有唯一的对象组成。

使用SORTED LIST函数输出一个有序的由唯一字母组成的列表u_list。
2找到非交集元素:difference
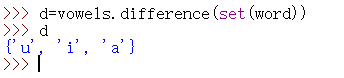
difference函数将vowels中的对象和Word中的对象进行比较,然后返回一个新的集合(d),是包含在vowels中但不在Word中的对象。
3找到交集元素:intersection

i集合由即在vowels又在set(word)中的所有对象组成。
简化vowels2程序:

3.3元组(tuple)

元组用()定义列表是【】,
一旦创建和填充数据,元组就不可变。
注意只有一个对象的元组
定义时必须在()中加上一个逗号,否则就被当作为字符串类型
这个编辑器(黑色背景那个)很漂亮,是吗?
在官网上可以下载sublime text3 然后找个破解版,不过在使用Python交互的函数如input时需要添加一个包,详细的步骤见链接: