一、Node.js中的模块
Node.js使用require引入依赖的模块,因此模块是Node.js中的重要组成部分,这篇博客主要罗列一下常用的Node.js模块,并且在后期会添加在工作中用到的模块参考备用。
二、Node.js EventEmitter
Node.js 所有的异步 I/O 操作在完成时都会发送一个事件到事件队列。Node.js里面的许多对象都会分发事件,所有这些产生事件的对象都是 events.EventEmitter 的实例。
events 模块只提供了一个对象: events.EventEmitter。EventEmitter 的核心就是事件触发与事件监听器功能的封装。你可以通过require("events");来访问该模块。
-
// 引入 events 模块
-
var events = require( 'events');
-
// 创建 eventEmitter 对象
-
var eventEmitter = new events.EventEmitter();
-
//event.js 文件
-
var events = require( 'events');
-
var emitter = new events.EventEmitter();
-
emitter.on( 'someEvent', function(arg1, arg2) {
-
console.log( 'listener1', arg1, arg2);
-
});
-
emitter.on( 'someEvent', function(arg1, arg2) {
-
console.log( 'listener2', arg1, arg2);
-
});
-
emitter.emit( 'someEvent', 'arg1 参数', 'arg2 参数');
| 序号 | 方法 & 描述 |
|---|---|
| 1 | addListener(event, listener) 为指定事件添加一个监听器到监听器数组的尾部。 |
| 2 | on(event, listener) 为指定事件注册一个监听器,接受一个字符串 event 和一个回调函数。 server.on('connection', function (stream) { console.log('someone connected!'); }); |
| 3 | once(event, listener) 为指定事件注册一个单次监听器,即 监听器最多只会触发一次,触发后立刻解除该监听器。 server.once('connection', function (stream) { console.log('Ah, we have our first user!'); }); |
| 4 | removeListener(event, listener) 移除指定事件的某个监听器,监听器必须是该事件已经注册过的监听器。 它接受两个参数,第一个是事件名称,第二个是回调函数名称。 var callback = function(stream) { console.log('someone connected!'); }; server.on('connection', callback); // ... server.removeListener('connection', callback); |
| 5 | removeAllListeners([event]) 移除所有事件的所有监听器, 如果指定事件,则移除指定事件的所有监听器。 |
| 6 | setMaxListeners(n) 默认情况下, EventEmitters 如果你添加的监听器超过 10 个就会输出警告信息。 setMaxListeners 函数用于提高监听器的默认限制的数量。 |
| 7 | listeners(event) 返回指定事件的监听器数组。 |
| 8 | emit(event, [arg1], [arg2], [...]) 按参数的顺序执行每个监听器,如果事件有注册监听返回 true,否则返回 false。 |
类方法
| 序号 | 方法 & 描述 |
|---|---|
| 1 | listenerCount(emitter, event) 返回指定事件的监听器数量。 |
事件
| 序号 | 事件 & 描述 |
|---|---|
| 1 | newListener
该事件在添加新监听器时被触发。 |
| 2 | removeListener
从指定监听器数组中删除一个监听器。需要注意的是,此操作将会改变处于被删监听器之后的那些监听器的索引。 |
-
var events = require( 'events');
-
var emitter = new events.EventEmitter();
-
emitter.emit( 'error');
运行时会显示以下错误:
node.js:201
throw e; // process.nextTick error, or 'error' event on first tick
^
Error: Uncaught, unspecified 'error' event.
at EventEmitter.emit (events.js:50:15)
at Object.<anonymous> (/home/byvoid/error.js:5:9)
at Module._compile (module.js:441:26)
at Object..js (module.js:459:10)
at Module.load (module.js:348:31)
at Function._load (module.js:308:12)
at Array.0 (module.js:479:10)
at EventEmitter._tickCallback (node.js:192:40) 三、Node.js Buffer
JavaScript 语言自身只有字符串数据类型,没有二进制数据类型。但在处理像TCP流或文件流时,必须使用到二进制数据。因此在 Node.js中,定义了一个 Buffer 类,该类用来创建一个专门存放二进制数据的缓存区。在 Node.js 中,Buffer 类是随 Node 内核一起发布的核心库。Buffer 库为 Node.js 带来了一种存储原始数据的方法,可以让 Node.js 处理二进制数据,每当需要在 Node.js 中处理I/O操作中移动的数据时,就有可能使用 Buffer 库。原始数据存储在 Buffer 类的实例中。一个 Buffer 类似于一个整数数组,但它对应于 V8 堆内存之外的一块原始内存。
Buffer 实例一般用于表示编码字符的序列,比如 UTF-8 、 UCS2 、 Base64 、或十六进制编码的数据。 通过使用显式的字符编码,就可以在 Buffer 实例与普通的 JavaScript 字符串之间进行相互转换。Node.js 目前支持的字符编码包括:
- ascii - 仅支持 7 位 ASCII 数据。如果设置去掉高位的话,这种编码是非常快的。
- utf8 - 多字节编码的 Unicode 字符。许多网页和其他文档格式都使用 UTF-8 。
- utf16le - 2 或 4 个字节,小字节序编码的 Unicode 字符。支持代理对(U+10000 至 U+10FFFF)。
- ucs2 - utf16le 的别名。
- base64 - Base64 编码。
- latin1 - 一种把 Buffer 编码成一字节编码的字符串的方式。
- binary - latin1 的别名。
- hex - 将每个字节编码为两个十六进制字符。
Buffer类中的方法如下:
| 序号 | 方法 & 描述 |
|---|---|
| 1 | new Buffer(size) 分配一个新的 size 大小单位为8位字节的 buffer。 注意, size 必须小于 kMaxLength,否则,将会抛出异常 RangeError。废弃的: 使用 Buffer.alloc() 代替(或 Buffer.allocUnsafe())。 |
| 2 | new Buffer(buffer) 拷贝参数 buffer 的数据到 Buffer 实例。废弃的: 使用 Buffer.from(buffer) 代替。 |
| 3 | new Buffer(str[, encoding]) 分配一个新的 buffer ,其中包含着传入的 str 字符串。 encoding 编码方式默认为 'utf8'。 废弃的: 使用 Buffer.from(string[, encoding]) 代替。 |
| 4 | buf.length 返回这个 buffer 的 bytes 数。注意这未必是 buffer 里面内容的大小。length 是 buffer 对象所分配的内存数,它不会随着这个 buffer 对象内容的改变而改变。 |
| 5 | buf.write(string[, offset[, length]][, encoding]) 根据参数 offset 偏移量和指定的 encoding 编码方式,将参数 string 数据写入buffer。 offset 偏移量默认值是 0, encoding 编码方式默认是 utf8。 length 长度是将要写入的字符串的 bytes 大小。 返回 number 类型,表示写入了多少 8 位字节流。如果 buffer 没有足够的空间来放整个 string,它将只会只写入部分字符串。 length 默认是 buffer.length - offset。 这个方法不会出现写入部分字符。 |
| 6 | buf.writeUIntLE(value, offset, byteLength[, noAssert]) 将 value 写入到 buffer 里, 它由 offset 和 byteLength 决定,最高支持 48 位无符号整数,小端对齐,例如: const buf = Buffer.allocUnsafe(6); buf.writeUIntLE(0x1234567890ab, 0, 6); // 输出: <Buffer ab 90 78 56 34 12> console.log(buf);noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| 7 | buf.writeUIntBE(value, offset, byteLength[, noAssert]) 将 value 写入到 buffer 里, 它由 offset 和 byteLength 决定,最高支持 48 位无符号整数,大端对齐。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 const buf = Buffer.allocUnsafe(6); buf.writeUIntBE(0x1234567890ab, 0, 6); // 输出: <Buffer 12 34 56 78 90 ab> console.log(buf); |
| 8 | buf.writeIntLE(value, offset, byteLength[, noAssert]) 将value 写入到 buffer 里, 它由offset 和 byteLength 决定,最高支持48位有符号整数,小端对齐。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| 9 | buf.writeIntBE(value, offset, byteLength[, noAssert]) 将value 写入到 buffer 里, 它由offset 和 byteLength 决定,最高支持48位有符号整数,大端对齐。noAssert 值为 true 时,不再验证 value 和 offset 的有效性。 默认是 false。 |
| 10 | buf.readUIntLE(offset, byteLength[, noAssert]) 支持读取 48 位以下的无符号数字,小端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 11 | buf.readUIntBE(offset, byteLength[, noAssert]) 支持读取 48 位以下的无符号数字,大端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 12 | buf.readIntLE(offset, byteLength[, noAssert]) 支持读取 48 位以下的有符号数字,小端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 13 | buf.readIntBE(offset, byteLength[, noAssert]) 支持读取 48 位以下的有符号数字,大端对齐。noAssert 值为 true 时, offset 不再验证是否超过 buffer 的长度,默认为 false。 |
| 14 | buf.toString([encoding[, start[, end]]]) 根据 encoding 参数(默认是 'utf8')返回一个解码过的 string 类型。还会根据传入的参数 start (默认是 0) 和 end (默认是 buffer.length)作为取值范围。 |
| 15 | buf.toJSON() 将 Buffer 实例转换为 JSON 对象。 |
| 16 | buf[index] 获取或设置指定的字节。返回值代表一个字节,所以返回值的合法范围是十六进制0x00到0xFF 或者十进制0至 255。 |
| 17 | buf.equals(otherBuffer) 比较两个缓冲区是否相等,如果是返回 true,否则返回 false。 |
| 18 | buf.compare(otherBuffer) 比较两个 Buffer 对象,返回一个数字,表示 buf 在 otherBuffer 之前,之后或相同。 |
| 19 | buf.copy(targetBuffer[, targetStart[, sourceStart[, sourceEnd]]]) buffer 拷贝,源和目标可以相同。 targetStart 目标开始偏移和 sourceStart 源开始偏移默认都是 0。 sourceEnd 源结束位置偏移默认是源的长度 buffer.length 。 |
| 20 | buf.slice([start[, end]]) 剪切 Buffer 对象,根据 start(默认是 0 ) 和 end (默认是 buffer.length ) 偏移和裁剪了索引。 负的索引是从 buffer 尾部开始计算的。 |
| 21 | buf.readUInt8(offset[, noAssert]) 根据指定的偏移量,读取一个无符号 8 位整数。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 如果这样 offset 可能会超出buffer 的末尾。默认是 false。 |
| 22 | buf.readUInt16LE(offset[, noAssert]) 根据指定的偏移量,使用特殊的 endian 字节序格式读取一个无符号 16 位整数。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 23 | buf.readUInt16BE(offset[, noAssert]) 根据指定的偏移量,使用特殊的 endian 字节序格式读取一个无符号 16 位整数,大端对齐。若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 24 | buf.readUInt32LE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian 字节序格式读取一个无符号 32 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 25 | buf.readUInt32BE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian 字节序格式读取一个无符号 32 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 26 | buf.readInt8(offset[, noAssert]) 根据指定的偏移量,读取一个有符号 8 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 27 | buf.readInt16LE(offset[, noAssert]) 根据指定的偏移量,使用特殊的 endian 格式读取一个 有符号 16 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 28 | buf.readInt16BE(offset[, noAssert]) 根据指定的偏移量,使用特殊的 endian 格式读取一个 有符号 16 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出 buffer 的末尾。默认是 false。 |
| 29 | buf.readInt32LE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian 字节序格式读取一个有符号 32 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 30 | buf.readInt32BE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian 字节序格式读取一个有符号 32 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 31 | buf.readFloatLE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian 字节序格式读取一个 32 位双浮点数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer的末尾。默认是 false。 |
| 32 | buf.readFloatBE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian 字节序格式读取一个 32 位双浮点数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer的末尾。默认是 false。 |
| 33 | buf.readDoubleLE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian字节序格式读取一个 64 位双精度数,小端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 34 | buf.readDoubleBE(offset[, noAssert]) 根据指定的偏移量,使用指定的 endian字节序格式读取一个 64 位双精度数,大端对齐。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 offset 可能会超出buffer 的末尾。默认是 false。 |
| 35 | buf.writeUInt8(value, offset[, noAssert]) 根据传入的 offset 偏移量将 value 写入 buffer。注意:value 必须是一个合法的无符号 8 位整数。 若参数 noAssert 为 true 将不会验证 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则不要使用。默认是 false。 |
| 36 | buf.writeUInt16LE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的无符号 16 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 37 | buf.writeUInt16BE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的无符号 16 位整数,大端对齐。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 38 | buf.writeUInt32LE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式(LITTLE-ENDIAN:小字节序)将 value 写入buffer。注意:value 必须是一个合法的无符号 32 位整数,小端对齐。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着value 可能过大,或者offset可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 39 | buf.writeUInt32BE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式(Big-Endian:大字节序)将 value 写入buffer。注意:value 必须是一个合法的有符号 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者offset可能会超出buffer的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 40 | buf.writeInt8(value, offset[, noAssert])<br根据传入的 offset="" 偏移量将="" value="" 写入="" buffer="" 。注意:value="" 必须是一个合法的="" signed="" 8="" 位整数。="" 若参数="" noassert="" 为="" true="" 将不会验证="" 和="" 偏移量参数。="" 这意味着="" 可能过大,或者="" 可能会超出="" 的末尾从而造成="" 被丢弃。="" 除非你对这个参数非常有把握,否则尽量不要使用。默认是="" false。<="" td=""> |
| 41 | buf.writeInt16LE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false 。 |
| 42 | buf.writeInt16BE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 16 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false 。 |
| 43 | buf.writeInt32LE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 44 | buf.writeInt32BE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个合法的 signed 32 位整数。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 45 | buf.writeFloatLE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer 。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 46 | buf.writeFloatBE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer 。注意:当 value 不是一个 32 位浮点数类型的值时,结果将是不确定的。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value可能过大,或者 offset 可能会超出 buffer 的末尾从而造成 value 被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 47 | buf.writeDoubleLE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个有效的 64 位double 类型的值。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成value被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 48 | buf.writeDoubleBE(value, offset[, noAssert]) 根据传入的 offset 偏移量和指定的 endian 格式将 value 写入 buffer。注意:value 必须是一个有效的 64 位double 类型的值。 若参数 noAssert 为 true 将不会验证 value 和 offset 偏移量参数。 这意味着 value 可能过大,或者 offset 可能会超出 buffer 的末尾从而造成value被丢弃。 除非你对这个参数非常有把握,否则尽量不要使用。默认是 false。 |
| 49 | buf.fill(value[, offset][, end]) 使用指定的 value 来填充这个 buffer。如果没有指定 offset (默认是 0) 并且 end (默认是 buffer.length) ,将会填充整个buffer。 |
四、Node.js Stream
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口。例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出)。Node.js,Stream 有四种流类型:
- Readable - 可读操作。
- Writable - 可写操作。
- Duplex - 可读可写操作.
- Transform - 操作被写入数据,然后读出结果。
- data - 当有数据可读时触发。
- end - 没有更多的数据可读时触发。
- error - 在接收和写入过程中发生错误时触发。
- finish - 所有数据已被写入到底层系统时触发。
如下代码展示了Stream ReadStream的用法:
-
var fs = require( "fs");
-
var data = '';
-
-
// 创建可读流
-
var readerStream = fs.createReadStream( 'input.txt');
-
-
// 设置编码为 utf8。
-
readerStream.setEncoding( 'UTF8');
-
-
// 处理流事件 --> data, end, and error
-
readerStream.on( 'data', function(chunk) {
-
data += chunk;
-
});
-
-
readerStream.on( 'end', function(){
-
console.log(data);
-
});
-
-
readerStream.on( 'error', function(err){
-
console.log(err.stack);
-
});
-
-
console.log( "程序执行完毕");
-
var fs = require( "fs");
-
var data = '菜鸟教程官网地址:www.runoob.com';
-
-
// 创建一个可以写入的流,写入到文件 output.txt 中
-
var writerStream = fs.createWriteStream( 'output.txt');
-
-
// 使用 utf8 编码写入数据
-
writerStream.write(data, 'UTF8');
-
-
// 标记文件末尾
-
writerStream.end();
-
-
// 处理流事件 --> data, end, and error
-
writerStream.on( 'finish', function() {
-
console.log( "写入完成。");
-
});
-
-
writerStream.on( 'error', function(err){
-
console.log(err.stack);
-
});
-
-
console.log( "程序执行完毕");
管道流:
-
var fs = require( "fs");
-
-
// 创建一个可读流
-
var readerStream = fs.createReadStream( 'input.txt');
-
-
// 创建一个可写流
-
var writerStream = fs.createWriteStream( 'output.txt');
-
-
// 管道读写操作
-
// 读取 input.txt 文件内容,并将内容写入到 output.txt 文件中
-
readerStream.pipe(writerStream);
-
-
console.log( "程序执行完毕");
链式流:
链式是通过连接输出流到另外一个流并创建多个流操作链的机制。链式流一般用于管道操作。
接下来我们就是用管道和链式来压缩和解压文件。创建 compress.js 文件, 代码如下:
-
var fs = require( "fs");
-
var zlib = require( 'zlib');
-
-
// 压缩 input.txt 文件为 input.txt.gz
-
fs.createReadStream( 'input.txt')
-
.pipe(zlib.createGzip())
-
.pipe(fs.createWriteStream( 'input.txt.gz'));
-
-
console.log( "文件压缩完成。");
五、Node.js路由
Node.js路由中对HTTP请求的URL的解析需要依赖以下url 和querystring 模块:
url.parse(string).query
|
url.parse(string).pathname |
| |
| |
------ -------------------
http://localhost:8888/start?foo=bar&hello=world
--- -----
| |
| |
querystring.parse(queryString)["foo"] |
|
querystring.parse(queryString)["hello"]
-
var http = require( "http");
-
var url = require( "url");
-
-
function start() {
-
function onRequest(request, response) {
-
var pathname = url.parse(request.url).pathname;
-
console.log( "Request for " + pathname + " received.");
-
response.writeHead( 200, { "Content-Type": "text/plain"});
-
response.write( "Hello World");
-
response.end();
-
}
-
-
http.createServer(onRequest).listen( 8888);
-
console.log( "Server has started.");
-
}
-
-
exports.start = start;
-
function route(pathname) {
-
console.log( "About to route a request for " + pathname);
-
}
-
-
exports.route = route;
-
var http = require( "http");
-
var url = require( "url");
-
-
function start(route) {
-
function onRequest(request, response) {
-
var pathname = url.parse(request.url).pathname;
-
console.log( "Request for " + pathname + " received.");
-
-
route(pathname);
-
-
response.writeHead( 200, { "Content-Type": "text/plain"});
-
response.write( "Hello World");
-
response.end();
-
}
-
-
http.createServer(onRequest).listen( 8888);
-
console.log( "Server has started.");
-
}
-
-
exports.start = start;
-
var server = require( "./server");
-
var router = require( "./router");
-
-
server.start(router.route);
五、Node.js 全局变量
JavaScript 中有一个特殊的对象,称为全局对象(Global Object),它及其所有属性都可以在程序的任何地方访问,即全局变量。
在浏览器 JavaScript 中,通常 window 是全局对象, 而 Node.js 中的全局对象是 global,所有全局变量(除了 global 本身以外)都是 global 对象的属性。在 Node.js 我们可以直接访问到 global 的属性,而不需要在应用中包含它。
global 最根本的作用是作为全局变量的宿主。按照 ECMAScript 的定义,满足以下条 件的变量是全局变量:
- 在最外层定义的变量;
- 全局对象的属性;
- 隐式定义的变量(未定义直接赋值的变量)。
注意: 永远使用 var 定义变量以 避免引入全局变量 ,因为全局变量会污染 命名空间,提高代码的耦合风险。
Node.js中常用的全局变量有:
- __filename __filename 表示当前正在执行的脚本的文件名。它将输出文件所在位置的绝对路径,且和命令行参数所指定的文件名不一定相同。 如果在模块中,返回的值是模块文件的路径。
- __dirname __dirname 表示当前执行脚本所在的目录。
- setTimeout(cb, ms) setTimeout(cb, ms) 全局函数在指定的毫秒(ms)数后执行指定函数(cb)。:setTimeout() 只执行一次指定函数。
- 返回一个代表定时器的句柄值。
- clearTimeout(t) clearTimeout( t ) 全局函数用于停止一个之前通过 setTimeout() 创建的定时器。 参数 t 是通过 setTimeout() 函数创建的定时器。
- setInterval(cb, ms) setInterval(cb, ms) 全局函数在指定的毫秒(ms)数后执行指定函数(cb)。返回一个代表定时器的句柄值。可以使用 clearInterval(t) 函数来清除定时器。setInterval() 方法会不停地调用函数,直到 clearInterval() 被调用或窗口被关闭。
- console console 用于提供控制台标准输出,它是由 Internet Explorer 的 JScript 引擎提供的调试工具,后来逐渐成为浏览器的实施标准。Node.js 沿用了这个标准,提供与习惯行为一致的 console 对象,用于向标准输出流(stdout)或标准错误流(stderr)输出字符。
| 序号 | 方法 & 描述 |
|---|---|
| 1 | console.log([data][, ...]) 向标准输出流打印字符并以换行符结束。该方法接收若干 个参数,如果只有一个参数,则输出这个参数的字符串形式。如果有多个参数,则 以类似于C 语言 printf() 命令的格式输出。 |
| 2 | console.info([data][, ...]) 该命令的作用是返回信息性消息,这个命令与console.log差别并不大,除了在chrome中只会输出文字外,其余的会显示一个蓝色的惊叹号。 |
| 3 | console.error([data][, ...]) 输出错误消息的。控制台在出现错误时会显示是红色的叉子。 |
| 4 | console.warn([data][, ...]) 输出警告消息。控制台出现有黄色的惊叹号。 |
| 5 | console.dir(obj[, options]) 用来对一个对象进行检查(inspect),并以易于阅读和打印的格式显示。 |
| 6 | console.time(label) 输出时间,表示计时开始。 |
| 7 | console.timeEnd(label) 结束时间,表示计时结束。 |
| 8 | console.trace(message[, ...]) 当前执行的代码在堆栈中的调用路径,这个测试函数运行很有帮助,只要给想测试的函数里面加入 console.trace 就行了。 |
| 9 | console.assert(value[, message][, ...]) 用于判断某个表达式或变量是否为真,接收两个参数,第一个参数是表达式,第二个参数是字符串。只有当第一个参数为false,才会输出第二个参数,否则不会有任何结果。 |
| 序号 | 事件 & 描述 |
|---|---|
| 1 | exit 当进程准备退出时触发。 |
| 2 | beforeExit 当 node 清空事件循环,并且没有其他安排时触发这个事件。通常来说,当没有进程安排时 node 退出,但是 'beforeExit' 的监听器可以异步调用,这样 node 就会继续执行。 |
| 3 | uncaughtException 当一个异常冒泡回到事件循环,触发这个事件。如果给异常添加了监视器,默认的操作(打印堆栈跟踪信息并退出)就不会发生。 |
| 4 | Signal 事件 当进程接收到信号时就触发。信号列表详见标准的 POSIX 信号名,如 SIGINT、SIGUSR1 等。 |
六、Node.js util 工具
util 是一个Node.js 核心模块,提供常用函数的集合,用于弥补核心JavaScript 的功能 过于精简的不足。
util.inherits
util.inherits(constructor, superConstructor)是一个实现对象间原型继承 的函数。JavaScript 的面向对象特性是基于原型的,与常见的基于类的不同。JavaScript 没有 提供对象继承的语言级别特性,而是通过原型复制来实现的。
-
var util = require( 'util');
-
function Base() {
-
this.name = 'base';
-
this.base = 1991;
-
this.sayHello = function() {
-
console.log( 'Hello ' + this.name);
-
};
-
}
-
Base.prototype.showName = function() {
-
console.log( this.name);
-
};
-
function Sub() {
-
this.name = 'sub';
-
}
-
util.inherits(Sub, Base);
-
var objBase = new Base();
-
objBase.showName();
-
objBase.sayHello();
-
console.log(objBase);
-
var objSub = new Sub();
-
objSub.showName();
-
//objSub.sayHello();
-
console.log(objSub);
-
base
-
Hello base
-
{ name: 'base', base: 1991, sayHello: [ Function] }
-
sub
-
{ name: 'sub' }
util.inspect
util.inspect(object,[showHidden],[depth],[colors])是一个将任意对象转换为字符串的方法,通常用于调试和错误输出。它至少接受一个参数 object,即要转换的对象。- showHidden 是一个可选参数,如果值为 true,将会输出更多隐藏信息。
- depth 表示最大递归的层数,如果对象很复杂,你可以指定层数以控制输出信息的多 少。如果不指定depth,默认会递归2层,指定为 null 表示将不限递归层数完整遍历对象。 如果color 值为 true,输出格式将会以ANSI 颜色编码,通常用于在终端显示更漂亮 的效果。
- util.inspect 并不会简单地直接把对象转换为字符串,即使该对 象定义了toString 方法也不会调用。
- util.isArray(object) 如果给定的参数 "object" 是一个数组返回true,否则返回false。
- util.isRegExp(object) 如果给定的参数 "object" 是一个正则表达式返回true,否则返回false。
- util.isDate(object) 如果给定的参数 "object" 是一个日期返回true,否则返回false。
- util.isError(object) 如果给定的参数 "object" 是一个错误对象返回true,否则返回false。
七、Node.js 文件系统
var fs = require("fs")Node.js 文件系统(fs 模块)模块中的方法均有异步和同步版本,例如读取文件内容的函数有异步的 fs.readFile() 和同步的 fs.readFileSync()。异步的方法函数最后一个参数为回调函数,回调函数的第一个参数包含了错误信息(error)。建议大家使用异步方法,比起同步,异步方法性能更高,速度更快,而且没有阻塞。
- path - 文件的路径。
- flags - 文件打开的行为。具体值详见下文。
- mode - 设置文件模式(权限),文件创建默认权限为 0666(可读,可写)。
- callback - 回调函数,带有两个参数如:callback(err, fd)。
flags 参数可以是以下值:
| Flag | 描述 |
|---|---|
| r | 以读取模式打开文件。如果文件不存在抛出异常。 |
| r+ | 以读写模式打开文件。如果文件不存在抛出异常。 |
| rs | 以同步的方式读取文件。 |
| rs+ | 以同步的方式读取和写入文件。 |
| w | 以写入模式打开文件,如果文件不存在则创建。 |
| wx | 类似 'w',但是如果文件路径存在,则文件写入失败。 |
| w+ | 以读写模式打开文件,如果文件不存在则创建。 |
| wx+ | 类似 'w+', 但是如果文件路径存在,则文件读写失败。 |
| a | 以追加模式打开文件,如果文件不存在则创建。 |
| ax | 类似 'a', 但是如果文件路径存在,则文件追加失败。 |
| a+ | 以读取追加模式打开文件,如果文件不存在则创建。 |
| ax+ | 类似 'a+', 但是如果文件路径存在,则文件读取追加失败。 |
-
var fs = require( "fs");
-
-
// 异步打开文件
-
console.log( "准备打开文件!");
-
fs.open( 'input.txt', 'r+', function(err, fd) {
-
if (err) {
-
return console.error(err);
-
}
-
console.log( "文件打开成功!");
-
});
-
var fs = require( "fs");
-
-
// 异步读取
-
fs.readFile( 'input.txt', function (err, data) {
-
if (err) {
-
return console.error(err);
-
}
-
console.log( "异步读取: " + data.toString());
-
});
-
-
// 同步读取
-
var data = fs.readFileSync( 'input.txt');
-
console.log( "同步读取: " + data.toString());
-
-
console.log( "程序执行完毕。");
八、Node.js GET/POST请求
由于GET请求直接被嵌入在路径中,URL是完整的请求路径,包括了?后面的部分,因此你可以手动解析后面的内容作为GET请求的参数。node.js 中 url 模块中的 parse 函数提供了这个功能。
-
var http = require( 'http');
-
var url = require( 'url');
-
var util = require( 'util');
-
-
http.createServer( function(req, res){
-
res.writeHead( 200, { 'Content-Type': 'text/plain'});
-
-
// 解析 url 参数
-
var params = url.parse(req.url, true).query;
-
res.write( "网站名:" + params.name);
-
res.write( "\n");
-
res.write( "网站 URL:" + params.url);
-
res.end();
-
-
}).listen( 3000);
POST 请求的内容全部的都在请求体中,http.ServerRequest 并没有一个属性内容为请求体,原因是等待请求体传输可能是一件耗时的工作。比如上传文件,而很多时候我们可能并不需要理会请求体的内容,恶意的POST请求会大大消耗服务器的资源,所以 node.js 默认是不会解析请求体的,当你需要的时候,需要手动来做。
-
var http = require( 'http');
-
var querystring = require( 'querystring');
-
-
http.createServer( function(req, res){
-
// 定义了一个post变量,用于暂存请求体的信息
-
var post = '';
-
-
// 通过req的data事件监听函数,每当接受到请求体的数据,就累加到post变量中
-
req.on( 'data', function(chunk){
-
post += chunk;
-
});
-
-
// 在end事件触发后,通过querystring.parse将post解析为真正的POST请求格式,然后向客户端返回。
-
req.on( 'end', function(){
-
post = querystring.parse(post);
-
res.end(util.inspect(post));
-
});
-
}).listen( 3000);
-
var http = require( 'http');
-
var querystring = require( 'querystring');
-
-
var postHTML =
-
'<html><head><meta charset="utf-8"><title>Node.js 实例</title></head>' +
-
'<body>' +
-
'<form method="post">' +
-
'网站名: <input name="name"><br>' +
-
'网站 URL: <input name="url"><br>' +
-
'<input type="submit">' +
-
'</form>' +
-
'</body></html>';
-
-
http.createServer( function (req, res) {
-
var body = "";
-
req.on( 'data', function (chunk) {
-
body += chunk;
-
});
-
req.on( 'end', function () {
-
// 解析参数
-
body = querystring.parse(body);
-
// 设置响应头部信息及编码
-
res.writeHead( 200, { 'Content-Type': 'text/html; charset=utf8'});
-
-
if(body.name && body.url) { // 输出提交的数据
-
res.write( "网站名:" + body.name);
-
res.write( "<br>");
-
res.write( "网站 URL:" + body.url);
-
} else { // 输出表单
-
res.write(postHTML);
-
}
-
res.end();
-
});
-
}).listen( 3000);

九、Node.js Web 模块
Node.js 提供了 http 模块,http 模块主要用于搭建 HTTP 服务端和客户端,使用 HTTP 服务器或客户端功能必须调用 http 模块,代码如下:
var http = require('http');
-
var http = require( 'http');
-
var fs = require( 'fs');
-
var url = require( 'url');
-
-
-
// 创建服务器
-
http.createServer( function (request, response) {
-
// 解析请求,包括文件名
-
var pathname = url.parse(request.url).pathname;
-
-
// 输出请求的文件名
-
console.log( "Request for " + pathname + " received.");
-
-
// 从文件系统中读取请求的文件内容
-
fs.readFile(pathname.substr( 1), function (err, data) {
-
if (err) {
-
console.log(err);
-
// HTTP 状态码: 404 : NOT FOUND
-
// Content Type: text/plain
-
response.writeHead( 404, { 'Content-Type': 'text/html'});
-
} else{
-
// HTTP 状态码: 200 : OK
-
// Content Type: text/plain
-
response.writeHead( 200, { 'Content-Type': 'text/html'});
-
-
// 响应文件内容
-
response.write(data.toString());
-
}
-
// 发送响应数据
-
response.end();
-
});
-
}).listen( 8080);
-
-
// 控制台会输出以下信息
-
console.log( 'Server running at http://127.0.0.1:8080/');
-
-
<html>
-
<head>
-
<meta charset="utf-8">
-
<title>My First Page </title>
-
</head>
-
<body>
-
<h1>我的第一个标题 </h1>
-
<p>我的第一个段落。 </p>
-
</body>
-
</html>
十、Node.js Express框架
Express 是一个简洁而灵活的 node.js Web应用框架, 提供了一系列强大特性帮助你创建各种 Web 应用,和丰富的 HTTP 工具。
使用 Express 可以快速地搭建一个完整功能的网站。Express 框架核心特性:
- 可以设置中间件来响应 HTTP 请求。
- 定义了路由表用于执行不同的 HTTP 请求动作。
- 可以通过向模板传递参数来动态渲染 HTML 页面。
$ npm install express --save
- body-parser - node.js 中间件,用于处理 JSON, Raw, Text 和 URL 编码的数据。
- cookie-parser - 这就是一个解析Cookie的工具。通过req.cookies可以取到传过来的cookie,并把它们转成对象。
- multer - node.js 中间件,用于处理 enctype="multipart/form-data"(设置表单的MIME编码)的表单数据。
10.1 Request和Response对象
Request 对象 - request 对象表示 HTTP 请求,包含了请求查询字符串,参数,内容,HTTP 头部等属性。常见属性有:
- req.app:当callback为外部文件时,用req.app访问express的实例
- req.baseUrl:获取路由当前安装的URL路径
- req.body / req.cookies:获得「请求主体」/ Cookies
- req.fresh / req.stale:判断请求是否还「新鲜」
- req.hostname / req.ip:获取主机名和IP地址
- req.originalUrl:获取原始请求URL
- req.params:获取路由的parameters
- req.path:获取请求路径
- req.protocol:获取协议类型
- req.query:获取URL的查询参数串
- req.route:获取当前匹配的路由
- req.subdomains:获取子域名
- req.accepts():检查可接受的请求的文档类型
- req.acceptsCharsets / req.acceptsEncodings / req.acceptsLanguages:返回指定字符集的第一个可接受字符编码
- req.get():获取指定的HTTP请求头
- req.is():判断请求头Content-Type的MIME类型
- res.app:同req.app一样
- res.append():追加指定HTTP头
- res.set()在res.append()后将重置之前设置的头
- res.cookie(name,value [,option]):设置Cookie
- opition: domain / expires / httpOnly / maxAge / path / secure / signed
- res.clearCookie():清除Cookie
- res.download():传送指定路径的文件
- res.get():返回指定的HTTP头
- res.json():传送JSON响应
- res.jsonp():传送JSONP响应
- res.location():只设置响应的Location HTTP头,不设置状态码或者close response
- res.redirect():设置响应的Location HTTP头,并且设置状态码302
- res.render(view,[locals],callback):渲染一个view,同时向callback传递渲染后的字符串,如果在渲染过程中有错误发生next(err)将会被自动调用。callback将会被传入一个可能发生的错误以及渲染后的页面,这样就不会自动输出了。
- res.send():传送HTTP响应
- res.sendFile(path [,options] [,fn]):传送指定路径的文件 -会自动根据文件extension设定Content-Type
- res.set():设置HTTP头,传入object可以一次设置多个头
- res.status():设置HTTP状态码
- res.type():设置Content-Type的MIME类型
路由
在HTTP请求中,我们可以通过路由提取出请求的URL以及GET/POST参数。接下来我们扩展 Hello World,添加一些功能来处理更多类型的 HTTP 请求。创建 express_demo2.js 文件,代码如下所示:
-
var express = require( 'express');
-
var app = express();
-
-
// 主页输出 "Hello World"
-
app.get( '/', function (req, res) {
-
console.log( "主页 GET 请求");
-
res.send( 'Hello GET');
-
})
-
-
-
// POST 请求
-
app.post( '/', function (req, res) {
-
console.log( "主页 POST 请求");
-
res.send( 'Hello POST');
-
})
-
-
// /del_user 页面响应
-
app.get( '/del_user', function (req, res) {
-
console.log( "/del_user 响应 DELETE 请求");
-
res.send( '删除页面');
-
})
-
-
// /list_user 页面 GET 请求
-
app.get( '/list_user', function (req, res) {
-
console.log( "/list_user GET 请求");
-
res.send( '用户列表页面');
-
})
-
-
// 对页面 abcd, abxcd, ab123cd, 等响应 GET 请求
-
app.get( '/ab*cd', function(req, res) {
-
console.log( "/ab*cd GET 请求");
-
res.send( '正则匹配');
-
})
-
-
-
var server = app.listen( 8081, function () {
-
-
var host = server.address().address
-
var port = server.address().port
-
-
console.log( "应用实例,访问地址为 http://%s:%s", host, port)
-
-
})
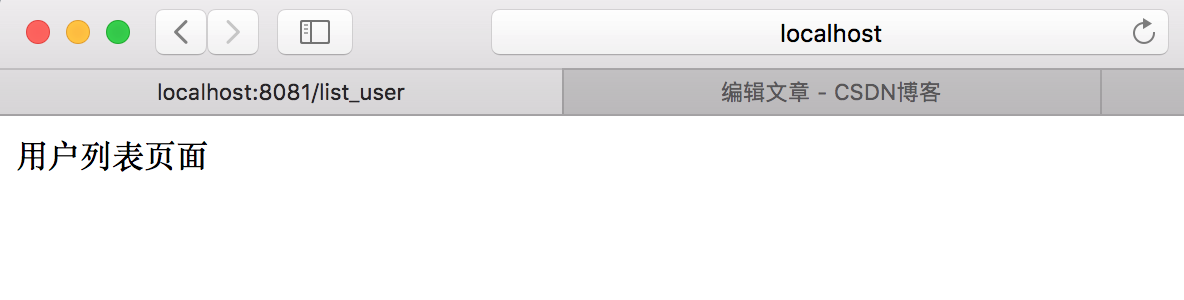
在浏览器中访问 http://127.0.0.1:8081/list_user,结果如下图所示:
访问不同url获得不同的响应结果。
静态文件
Express 提供了内置的中间件 express.static 来设置静态文件如:图片, CSS, JavaScript 等。你可以使用 express.static 中间件来设置静态文件路径。例如,如果你将图片, CSS, JavaScript 文件放在 public 目录下,你可以这么写:
app.use(express.static('public'));
node_modules
server.js
public/
public/images
public/images/logo.png