基本概念
传统机器学习问题大多为单标记问题;比如数字识别,给计算机传入一张数字图像,程序会给你返回数字的预测,但它只会返回一个数字而不是多个,这就是单标记问题。而如果给计算机一张街道的图像,要求判断图像中有哪些物体,这便是一个多标记问题。
在这种多标记框架下,我们用
来表示一个样本集中的一个输入输出对;其中
是一个二进制向量
,
代表第i个样本的第j个标记,
表示该类别为负,
表示该类别为正。如果一个问题的类别标记有:蓝天,白云,大海,那
就是一个三维的行向量
。如果输入图片只有蓝天和白云,那
。这便是多标记学习的定义。
评价指标
和单标记问题一样,多标记学习问题也需要评价指标来衡量算法的性能。下面列举几个在论文中常用的评价指标 (在公式表述中 表示样本数, 表示标记总数):
Hamming Loss
这个评价指标考察的是样本在单个标记上的误分类情况,即相关标记未出现在预测的标记集合中或无关标记出现在预测的标记集合中。 用于度量两个集合之间的 对称差, 和 的对称差为 。
Ranking Loss
其中, 为集合 在标记空间中的“补集”。该评价指标用于考察在样本的类别标记排序序列中出现排序错误的情况,即无关标记在排序序列中位于相关标记之前。该指标取值越小则系统性能越优,最优值为 。
One Error
在这里 表示判断,符号中的条件满足时为1,不满足则为0。该评价指标用于考察样本的类别标记排序序列中,序列最前端的标记不属于相关标记集合的情况。该指标取值越小性能越优,最优值为 。
Coverage
其中 为与实值函数 对应的排序函数。该评价指标用于考察在样本的类别标记排序序列中,覆盖所有相关标记所需要的搜索深度情况。该指标取值越小性能越优,其最优值为 。
Average Precision
该评价指标用于考察在样本的类别标记排序序列中,排在相关标记之前的标记仍为相关标记的情况。该指标取值越大性能越优,最优值为 。
MicroAUC
在这里 ,即第j个标记为正的特征集合, 则表示第j个标记为负的特征集合。该评价指标用于考察样本的类别标记对应的正样本的置信概率大于负样本的置信概率的情况。该评价指标取值越大性能越优,最优值 。
上述指标在multi-label的相关论文中是最常用的评价指标,其python代码的github链接为 https://github.com/ZesenChen/PyLift/blob/master/evaluate.py。对多标记学习感兴趣的在做实验时可以直接调用这些评价指标函数对你的算法性能进行评估。
算法分类
对于多标记学习的算法分类,可以用下面这张图来概括:
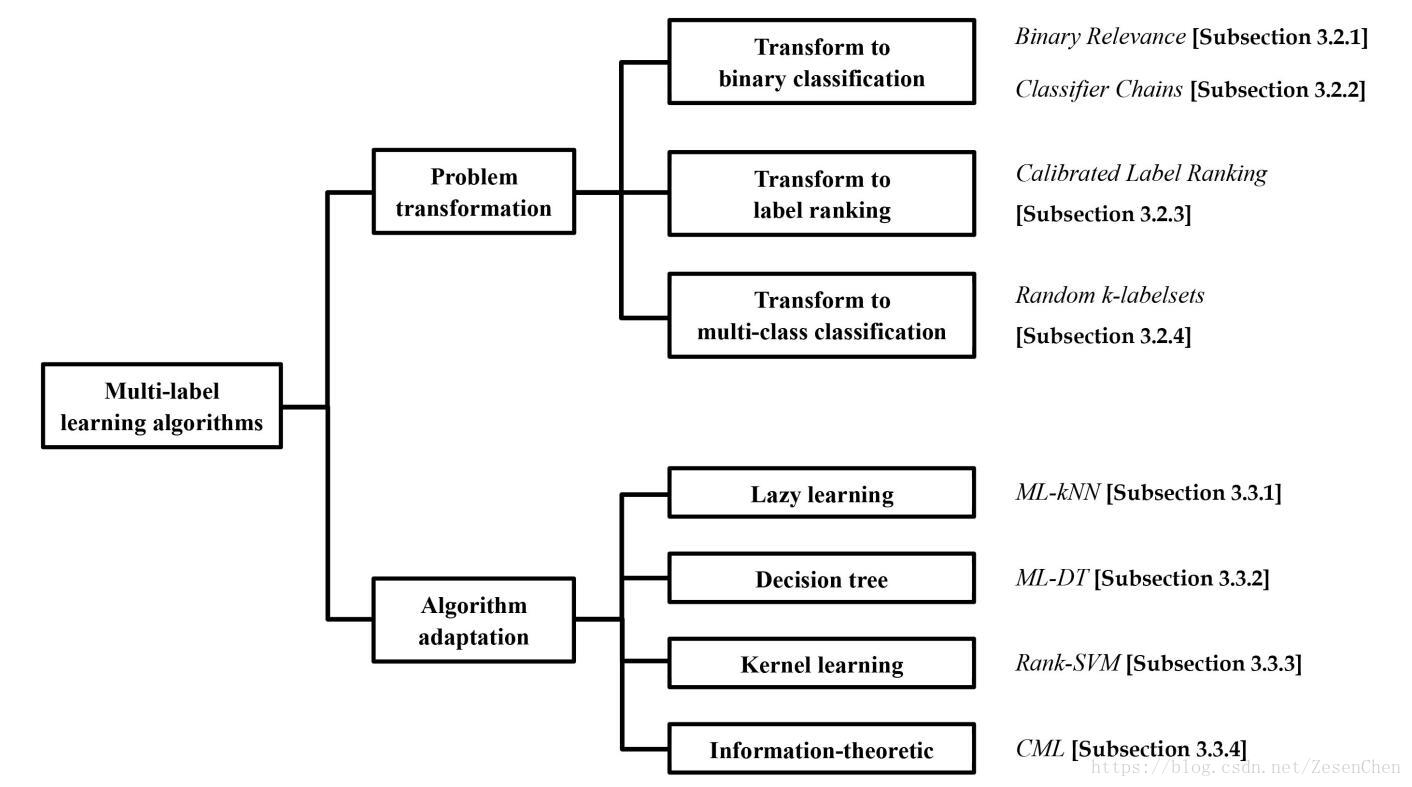
总的来说,多标记学习算法可以分为两大类:
a) “问题转换”方法:该类方法的基本思想是通过对多标记训练样本进行处理,将多标记学习问题转换为其它已知的学习问题进行求解。代表性学习算法有一阶方法Binary Relevance[2],该方法将多标记学习问题转化为“二类分类(binary classification)”问题求解;二阶方法 Calibrated Label Ranking[3],该方法将多标记学习问题转化为“标记排序(label ranking)”问题求解;高阶方法 Random k-labelsets[4],该方法将多标记学习问题转化为“多类分类(multi-classclassification)”问题求解。
b)“算法适应(algorithm adaptation)”方法:该类方法的基本思想是通过对常用监督学习算法进行改进,将其直接用于多标记数据的学习。代表性学习算法有一阶方法 ML-kNN[5],该方法将“惰性学习(lazy learning)”算法 k 近邻进行改造以适应多标记数据;二阶方法 Rank-SVM[6],该方法将“核学习(kernel learning)”算法 SVM 进行改造以适应多标记数据;高阶方法 LEAD[7],该方法将“贝叶斯学习(Bayes learning)算法”Bayes 网络进行改造以适应多标记数据。
换句话说,问题转换方法的核心是“改造数据适应算法”,算法适应方法的核心是“改造算法适应数据”。
数据集
多标记学习问题的数据集比较分散,我做过整理后一并上传到github上,链接如下:https://github.com/ZesenChen/multi-label-dataset,持续更新中。
参考文献
[1] Zhang M L, Zhou Z H. A Review on Multi-Label Learning Algorithms[J]. IEEE Transactions on Knowledge & Data Engineering, 2014, 26(8):1819-1837.
[2] Boutell M R, Luo J, Shen X, et al. Learning multi-label scene classification ☆[J]. Pattern Recognition, 2004, 37(9):1757-1771.
[3] Brinker K. Multilabel classification via calibrated label ranking[J]. Machine Learning, 2008, 73(2):133-153.
[4] Tsoumakas G, Vlahavas I. Random k-Labelsets: An Ensemble Method for Multilabel Classification[C]// European Conference on Machine Learning. Springer-Verlag, 2007:406-417.
[5] Zhang M L, Zhou Z H. ML-KNN: A lazy learning approach to multi-label learning[M]. Elsevier Science Inc. 2007.
[6] Elisseeff A, Weston J. A kernel method for multi-labelled classification[C]// International Conference on Neural Information Processing Systems: Natural and Synthetic. MIT Press, 2001:681-687.
[7] Zhang M L, Zhang K. Multi-label learning by exploiting label dependency[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2010:999-1008.