
《星际争霸》的国服重置版正在预售中,将在暑假期间登陆战网。今年是星际争霸发行20周年,这20年间RTS即时战略游戏从兴起到没落,在游戏届的地位已经大不如前。这其中的一个原因是它的高度复杂性,从宏观的战略,到微观的操作,需要考虑并迅速做出反应的点太多太多。这样的特点使得星际看的人多玩的人少,但却恰恰适合征服围棋后的AI来一展身手。当2016年AlphaGo击败李世石后DeepMind宣布进军星际2,众多媒体纷纷发文:既围棋之后,电子竞技也要被AI征服了。而到了2017年,DeepMind联合暴雪发布了星际2的机器学习环境SC2LE和PySC2,使得广大研究者都可以参与到这项挑战中来,但另一方面也说明了AI征服星际绝非易事。
SC2LE,即StarCraft II Learning Environment(地址附于文末),星际争霸2学习环境,它提供了完整的API接口来从外部对一局星际2游戏进行控制。并且还包含录像分析工具,可以把一局比赛中玩家的指令集依次提取出来。在windows、mac、linux上,SC2LE都有相应客户端。而PySC2,则是DeepMind基于SC2LE开发出的python组件,使得研究者可以更方便的使用python编写星际2的强化学习程序。并且PySC2中还额外包含7个小游戏(地图),分别是坐标寻路、寻找收集矿物、寻找消灭跳虫、枪兵vs蟑螂、枪兵vs毒爆跳虫、采集矿物和瓦斯、建造枪兵,以降低学习的难度。PySC2的安装很简单,安好星际2游戏后使用pip工具运行pip install pysc2就行了,详见文末链接。
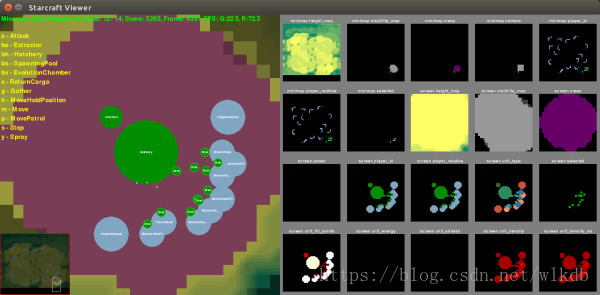
AlphaGo在围棋上之所以能表现的如此完美,根本原因自然是近年来卷积神经网络的进步和计算机性能的不断提升。但另一方面,围棋本身的简洁也很重要。虽然所需计算量很大,可围棋的规则和输入输出却非常简单。而星际2的输入输出呢?让我们来看看PySC2中是怎么定义的。输入共12种,可分为4类:
1. 游戏信息。
游戏画面信息。这类似围棋的棋盘输入,是最主要的输入信息。画面大小默认为84*84,分为13个子项。分别为:地形高度,地图可见性,是否有虫族菌毯,是否在己方神族水晶塔范围内,单位所属玩家ID,单位所属玩家与己方关系,单位类型,单位是否被选中,单位剩余生命值,单位剩余护盾值,单位剩余能量值,单位密度(部队有可能堆叠在一起),单位密度精细值。
小地图信息。与游戏画面信息类似,大小默认为64*64,只有7个子项:地形高度,地图可见性,是否有虫族菌毯,当前小地图位置,单位所属玩家ID,单位所属玩家与己方关系,单位是否被选中。
己方玩家信息。分为11个子项,包括:玩家ID,矿物数,瓦斯数,当前人口,当前人口上限,部队所占人口,农民所占人口,闲置农民数,部队数量,传送门数量(神族),幼虫数量(虫族)。
2. 单位信息。
单个单位信息。选择单个单位时提供,包括:单位类型,单位所属玩家与己方关系,单位剩余生命值,单位剩余护盾值,单位剩余能量值,运输单位(所选单位为运输机时),传送百分比(所选单位为正在传送的神族部队时)。
多个单位信息。选择多个单位时提供,每个单位的具体信息与上面一致。
运输机中所有单位信息。选择运输机时提供,每个单位的具体信息与上面一致。
建筑中所生产单位信息。选择产兵建筑时提供,每个单位的具体信息与上面一致。
运输机中可用空位。选择运输机时提供,代表运输机中还剩下多少位置。
编组信息。提供玩家各个编组的单位信息,最多10组,每组提供本组的单位数量和第一个单位的类型。
3. 环境信息。
游戏循环。代表当前游戏是第几局。
累计得分。提供当前游戏己方玩家的多项得分,以作为奖励进行强化学习。
4. 可用指令集信息。给出当前所有的可用指令,也就是对输出范围进行了指定。

可以看到,PySC2的输入拥有众多类别,复杂性远远超过围棋,当然玩过即时战略游戏的玩家对这些应该还是比较熟悉的哈哈。另一方面,以这样的形式给出输入,使得AI和人类玩家所获得的信息是一模一样的,严格保证了游戏公平性。而在输出时,PySC2还可以对AI的APM进行限制,默认为180,和中等水平人类玩家相当。所有的输出指令共计524个,每个指令又有各自的参数,所有的参数类型共13种。常用的指令比如:
·移动小地图位置。参数类型为小地图的坐标,显示这个坐标的画面。
·框选单位。参数类型为两个游戏画面的坐标,代表游戏画面中一个矩形的左上角和右下角,对这个矩形中的已方单位进行框选。
·基于游戏画面的移动攻击。参数类型为游戏画面的坐标,控制所选单位平A到游戏画面中的指定位置。
·建造建筑。参数类型为建筑类型,控制所选农民建造指定建筑物。
了解了输入输出,接下来我们就可以编写AI了。PySC2提供了一个在MoveToBeacon小游戏中的简单训练脚本AI。MoveToBeacon小游戏,类似各种即时战略游戏新手教程的第一关,就是控制一个机枪兵不停的移动到指定位置。
class MoveToBeacon(base_agent.BaseAgent):
"""An agent specifically for solving the MoveToBeacon map."""
def step(self, obs):
super(MoveToBeacon, self).step(obs)
if _MOVE_SCREEN in obs.observation["available_actions"]:
player_relative = obs.observation["screen"][_PLAYER_RELATIVE]
neutral_y, neutral_x = (player_relative == _PLAYER_NEUTRAL).nonzero()
if not neutral_y.any():
return actions.FunctionCall(_NO_OP, [])
target = [int(neutral_x.mean()), int(neutral_y.mean())]
return actions.FunctionCall(_MOVE_SCREEN, [_NOT_QUEUED, target])
else:
return actions.FunctionCall(_SELECT_ARMY, [_SELECT_ALL])代码结构为:继承BaseAgent定义一个类,实现step函数,参数obs包含了所有的输入信息。首先判断_MOVE_SCREEN控制单位移动指定是否可用,如果不可用则说明还没有选中机枪兵,那么就返回带_SELECT_ALL的_SELECT_ARMY指令(F2)选中所有部队。在可以调用_MOVE_SCREEN时,则查看输入中screen游戏画面中的_PLAYER_RELATIVE部队归属子项,统计出所有部队归属为_PLAYER_NEUTRAL中立单位的位置。再计算这些位置的平均值,得到需要移动到的Beacon的中心点target。最后调用带[_NOT_QUEUED, target]的_MOVE_SCREEN指令,让所选机枪兵立即移动到target位置。
我也编写了一个不带学习能力的脚本AI,在Simple64地图上用人族击败了各族的疯狂电脑。Simple64地图是一个比较小的双人对战地图,为正常的采矿造兵模式。这个脚本选的战术和当初我刚打星际2时所选的一样,6BB(表鄙视我- -)...流程相当简洁粗暴,就是不停造农民造满16个,要卡人口了就造房子,有钱了就造兵营直到6个,兵营不停出机枪兵,机枪兵够24个了就神圣的F2A(全部选中进攻敌人基地)。具体效果怎么样,相信用过的人都知道哈哈。而用脚本来实现的话,除了编写上述流程外,还有一些细节需要注意:基地与兵营集结点的设置,建筑位置的选择,让造完建筑的农民回来采矿,对人口增长速度的预判。通过这个脚本,我充分熟悉了PySC2环境,也清楚了强化学习AI在正常对战中的具体训练目标(代码地址见文末)。

那么对于一个强化学习的AI,每回合需要进行的操作流程是哪些呢:
·对输入的游戏信息进行数据处理,转换成自己模型所需的形式。
·搜索模型对于本轮输入,权值最大的输出。
·根据本轮的得分变化和最大权值,对模型的参数进行更新。
我用深度强化学习先后训练了MoveToBeacon移动到指定位置、CollectMineralShards收集矿物、DefeatRoaches机枪兵vs蟑螂、DefeatZerglingsAndBanelings机枪兵vs跳虫毒爆这四个小游戏。为了降低训练难度,每次都先选中所有部队,之后进行的指令限定为移动或移动攻击,通过卷积神经网络来学习指令参数中的坐标。那么在MoveToBeacon中,需求其实就是在screen中选出相应的_PLAYER_RELATIVE;在CollectMineralShards中,需求是选出距离枪兵最近的矿物;在DefeatRoaches中,则是选出血量最少的蟑螂进行攻击;在DefeatZerglingsAndBanelings中,需求是识别出最近的毒爆进行优先攻击。在这四个任务中,所需的输入信息其实有限,我也就只从screen游戏画面信息中选取了一部分,包括:unit_type单位类型、player_relative单位归属、unit_hit_points单位剩余生命值、selected选中单位。为了加速训练速度提升训练效果,我对这几个输入进行了进一步增强,把unit_type、player_relative、unit_hit_points按是否被选中又各分为了selected和unselected两部分。并且统计出了所有选中单位的平均坐标,计算了地图上各个点到这个坐标的距离作为又一个输入,从而让网络更容易学习到离机枪兵最近的矿物或者毒爆。最后,我为了程序又添加了基于录像的学习方式。相比于自主强化学习,从录像中学习的step函数中多了一个action参数,从而告诉程序在本轮中录像里玩家如何选择。使用从录像中学习时,AI可以通过一个几十秒的replay训练一遍就可以对MoveToBeacon、CollectMineralShards和DefeatRoaches学习完毕(github地址见文末)。

虽然这样的训练速度堪称光速,但毕竟不够通用,而且效果也只能算一般。最近DeepMind倒是又发了一篇PySC2的论文,提出了用Relational Deep Reinforcement Learning关系性深度强化学习来训练这7个小游戏,从而提升模型的泛化能力并更容易使用背景知识。通过RDRL,DeepMind在6个小游戏上达到了当前的最高水平,训练效果的视频地址见:http://bit.ly/2kQWMzE(需翻墙)。可以看到,在机枪兵vs跳虫毒爆的小游戏中,AI学会了用一两个机枪兵顶在前面吸引毒爆,用大部队在后面点毒爆疯狂输出,取到了很好的效果。当然,在这背后也仍然需要海量的模型迭代计算量,我们一般还是很难玩得起的。
PySC2已发布近一年之久,对于其中的7个小游戏,可以通过录像来迅速训练好模型,可以通过更先进的模型来取得超越人类的效果。这能让我们感到一些慰藉,看到一丝光亮,但真正能与人类玩家对战的星际2 AI仍旧遥远。相信在之后的研究中,从录像中学习、对输入的人为增强处理以及背景知识的录入在很长一段时间内仍然是必要的。另一方面,AlphaGo可以通过蒙特卡洛树、价值网络和快速走子来对棋局的发展做出预测,可星际2的AI呢?是通过暴雪的SC2LE来提前模拟比赛的发展,还是在AI中自己保存各单位的详细数据以对游戏进行粗略预测,这也是一个至关重要的问题。最后,上个月中国刚成年的智障人皇李中堂time宣布暂时离开星际,在此缅怀一下他在《中国好星际》第四季中的音容笑貌,期待他可能的回归,祝一切顺利~

相关链接
SC2LE:https://github.com/Blizzard/s2client-proto
PySC2:https://github.com/deepmind/pysc2
环境搭建:https://yq.aliyun.com/articles/176617
本文代码:https://github.com/wlkdb/SC2AI
DeepMind关系深度学习论文:https://arxiv.org/pdf/1806.01830.pdf