KNN: 依赖数据,无数学模型可言。适用于可容易解释的模型。
对异常值敏感,容易受到数据不平衡的影响。
Bayesian: 基于条件概率, 适用于不同维度之间相关性较小的时候,比较容易解释。也适合增量训练,不必要再重算一遍。应用:垃圾邮件处理。
Decision Tree: 此模型更容易理解不同属性对于结果的影响程度(如在第几层)。可以同时处理不同类型的数据。但因为追踪结果只需要改变叶子节点的属性,所以容易受到攻击。应用:其他算法的基石。
Random Forest: 随机森林是决策树的随机集成,一定程度上改善了其容易被攻击的弱点。适用于数据维度不太高(几十)又想达到较高准确性的时候。不需要调整太多参数,适合在不知道适用什么方法的时候先用下。
SVM: SVM尽量保持样本间的间距,抗攻击能力强,和RandomForest一样是一个可以首先尝试的方法。
对数几率回归:Logistic regression,不仅可以输出结果还可以输出其对应的概率。拟合出来的参数可以清晰地看到每一个feature对结果的影响。但是本质上是一个线性分类器,特征之间相关度高时不适用。同时也要注意异常值的的影响。
Discriminat Analysis典型的是LDA,把高维数据投射到低维上,使数据尽可能分离。往往作为一个降维工具使用。但是注意LDA假设数据是正态分布的。
Neural Network. 准确来说还是一个黑箱,适用于数据量大的时候使用。
Ensemble-Boosting : 每次寻找一个可以解决当前错误的分类器,最后再通过权重加和。好处是自带了特征选择,发现有效的特征。也方便去理解高维数据。
Ensemble-Bagging: 训练多个弱分类器投票解决。随机选取训练集,避免了过拟合。
Ensemble-Stacking: 以分类器的结果为输入,再训练一个分类器。一般最后一层用logistic Regression. 有可能过渡拟合,很少使用。
其他:
Maximum entropy model
最大熵模型不是一个分类器,是用来判断预测结果好坏的。对于它来说,分类器预测是相当于是:针对样本,给每个类一个出现概率。比如说样本的特征是:性别男。我的分类器可能就给出了下面这样一个概率:高(60%),矮(40%)。
而如果这个样本真的是高的,那我们就得了一个分数60%。最大熵模型的目标就是让这些分数的乘积尽量大。
决策树的数学基础就是他。
LR其实就是使用最大熵模型作为优化目标的一个算法
Expactation-Maximization
EM也不是分类器,而是一个思路,很多算法基于此实现。如高斯混合模型,k-means聚类
Hidden Markov Model
马尔科夫模型不是一个分类器,主要用于通过前面的状态预测后面的状态。主要作用与序列。用于语音识别效果较好。
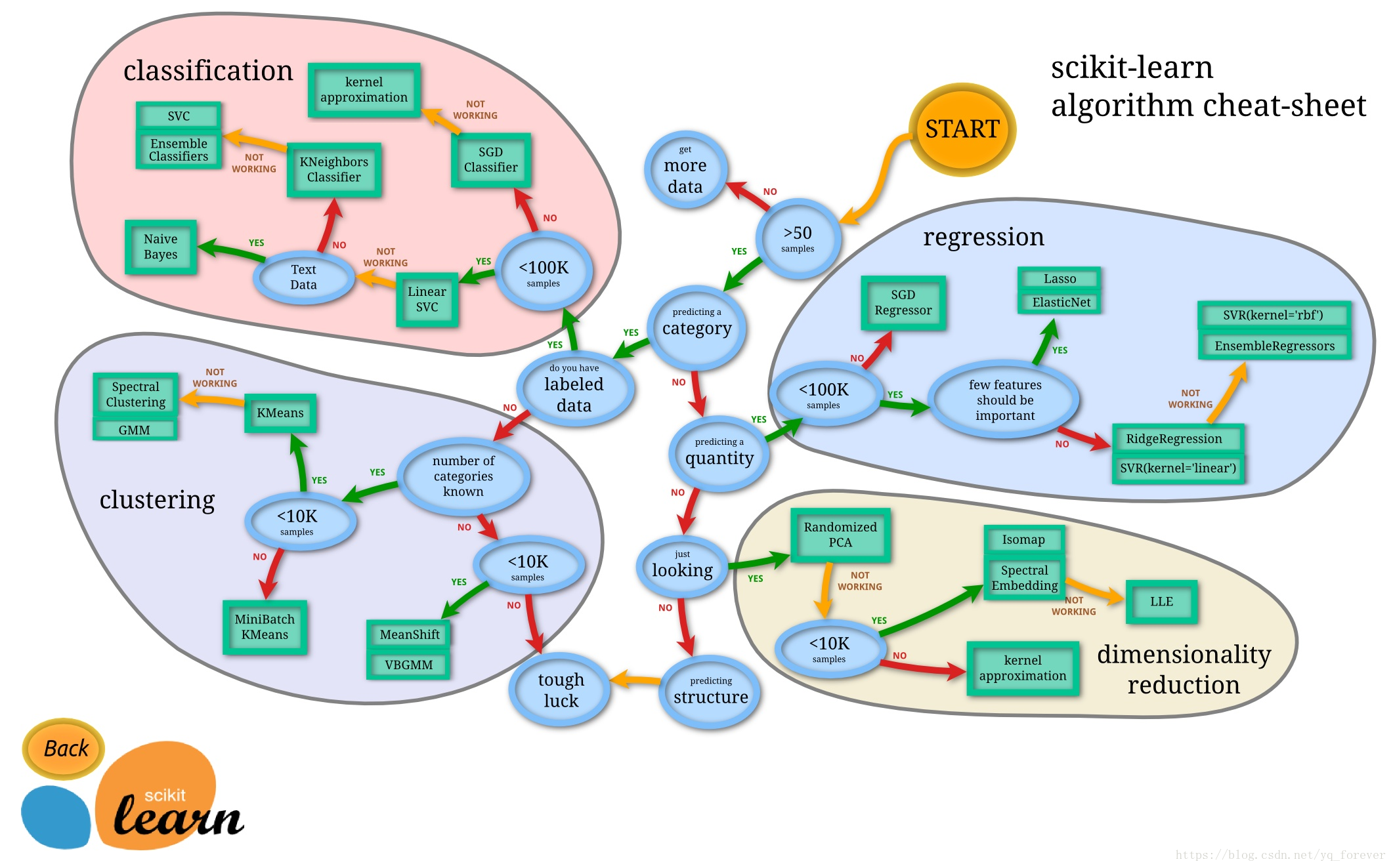
Reference: