手写Hashmap代码:
首先我们需要了解jdk里面hashmap的源码部分,如果对于hashmap的源码有了解的朋友,就应该会知道hashmap里面的这段代码:

是的,这是一段经典的node节点代码,我们可以吧hashmap看成一个存储单向链表的数组,然后每个链表里面的元素都是包含有相应的k v值。
参考源码的内容,我写了一小段自己关于hashmap的设计代码:
首先是一个父类接口的设计:
/**
* 作者:idea
* 日期:2018/6/25
* 描述:
*/
public interface MyMap<K,V> {
public V get(K key);
public V put(K key,V value);
interface IEntry<K,V>{
public K getKey();
public V getValue();
}
}
设计好了父类接口之后,编写一个MyHashMap类实现这个接口即可了。
在MyHashMap类里面需要编写相应的初始化参数:
/**
* 作者:idea
* 日期:2018/6/25
* 描述:
*/
public class MyHashMap<K,V> implements MyMap<K,V> {
private static final int DEAFULT_SIZE=1<<4; //16
private static final float DEFAULT_LOAD_SIZE=0.76f; //负载因子
private int deaultInitSize; //默认大小
private float deaultLoadSize; //默认负载因子
private int entrySize; //默认的entry数组数量
private Entry<K,V>[] table=null;
public MyHashMap(){
this(DEAFULT_SIZE,DEFAULT_LOAD_SIZE);
}
//采用了门面模式
//仔细观察下,你会发现,其实这里使用到了“门面模式”。这里的2个构造方法其实指向的是同一个,但是对外却暴露了2个“门面”!
public MyHashMap(int deaultInitSize,float deaultLoadSize){
this.deaultInitSize=deaultInitSize;
this.deaultLoadSize=deaultLoadSize;
table=new Entry[this.deaultInitSize];
}接下来便是核心的get和put方法了:
get方法的实现如下所示:

@Override
public V get(K key) {
int index=hash(key)&(deaultInitSize-1);
if(table[index]==null){
return null;
}else{
Entry<K,V> e=table[index];
do{
if(e.getKey().equals(key)){
return e.getValue();
}
e=e.next;
}while(e!=null);
}
return null;
}关于put部分方法的实现如下所示:从函数的实现可以看出resize是一个比较消耗性能的部分。
@Override
public V put(K key, V value) {
if(entrySize>=deaultInitSize*deaultLoadSize){
//扩容操作
resize(deaultInitSize*2);
}
int index=hash(key)&(deaultInitSize-1);
if(table[index]==null){
table[index]=new Entry<K,V>(key,value,null);
entrySize++;
}else{
Entry<K,V> tempEntry=table[index];
Entry<K,V> e=tempEntry;
while(e!=null){
if(key ==e.getKey()||e.getKey().equals(key)){
e.setValue(value);
break;
}
e=e.next;
}
//这里面需要联想一下链表那边的引用,next指示了原有的链表地址,所以第三个参数是tempentry
table[index]=new Entry<K,V>(key,value,tempEntry);
entrySize++;
}
return value;
}在上述的截图里面,读者会看到一个叫做hash的函数,这是我自己封装的一个关于hash值计算的函数,可以通过输入的key自动算出相应的hash值。以及一个rehash函数和resize函数都是用于提供扩容数组的功能。
关于hash函数里面的>>>和^操作符,可能大多数人在平时编程里面接触的不多,在这里我简单提及一下:
<< 左移运算符,num << 1,相当于num乘以2
>> 右移运算符,num >> 1,相当于num除以2
>>> 无符号右移,忽略符号位,空位都以0补齐
如:
a=00110111,则a>>2=00001101,a>>>2=00001101,
b=11010011,则b>>2=11110100,b>>>2=00110100
//自定义的hash算法
private int hash(Object key){
int hashcode= Objects.hashCode(key);
hashcode^=(hashcode>>>20)^(hashcode>>>12);
return hashcode^(hashcode>>>7)^(hashcode>>>4);
}
//重新扩容,核心在rehash里面
private void resize(int i){
Entry[] newTable=new Entry[i];
this.deaultInitSize=i;
this.entrySize=0;
System.out.println("newTable size:--------->"+newTable.length);
rehash(newTable);
}
//扩容算法的核心部分
private void rehash(Entry<K,V>[] newTable){
List<Entry<K,V>> entryList=new ArrayList<Entry<K,V>>();
for(Entry<K,V> e:table){
while(e!=null) {
entryList.add(e);
e=e.next;
}
}
if(newTable.length>0){
table=newTable;
}
for (Entry<K,V> entry : entryList) {
put(entry.getKey(),entry.getValue());
}
}如果读者有兴趣的话,可以去看看jdk源码里面关于hashcode的生成函数:
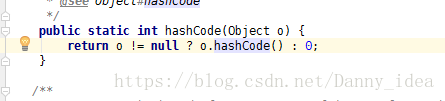
在Objects类里面,点开源码追溯hashCode函数,你会看到以下内容:(jdk1.8环境里面)

这个时候会看到一个叫做native的声明修饰符。
关于native这个关键字而言,说明修饰的方法是一个原生态的函数,方法的对应实现并不是在当前文件中,而是在别的C/C++文件里面。
由于在java语言里面,不允许直接对操作系统的底层进行直接的访问和操作,于是在jdk里面提供了一个JNI接口用于供java代码调用其他语言编写的代码内容。
最后便是相应的测试代码了:
/**
* 作者:idea
* 日期:2018/6/25
* 描述:
*/
public class Test {
public static void main(String[] args) {
MyHashMap mh=new MyHashMap();
for(int i=0;i<10000;i++){
mh.put(i,i);
}
for(int i=0;i<10000;i++) {
if (mh.get(i) != null) {
System.out.println(mh.get(i));
}
}
}
}测试成功之后,相应的输出如下所示:

当然,自己写的hashmap和jdk里面的源码差距还是有些大的,但是自己亲自手写过一遍集合框架的内容之后,确实能提升自己一些能力。