- 如何查看语句执行速度
- 查看Mysql关于profile的设置

- 打开profiling

- 查看profiles的记录情况

- 执行SQL,查看其执行情况;再查看profiles记录,就能看到刚SQL的执行耗时

2.如何查看语句执行计划
使用explain
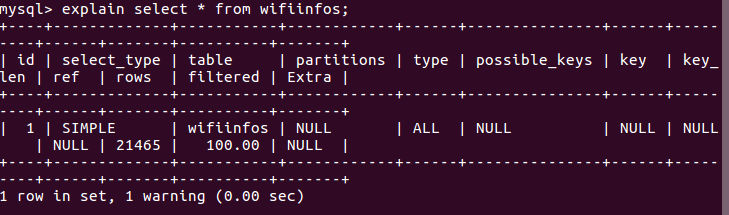
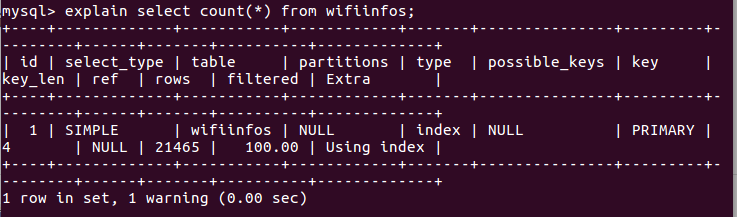
Extra列中,列出了该SQL在执行中是否使用Index,大家可以根据该列去判断是否SQL Query是高效的。
3. 增加索引提高查询效率
- 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
例子: 未在timestamp上建立索引时耗时0.04s

在timestamp上建立索引后查询耗时明显缩短了

- 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0 - in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3 - 如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num - 索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
- 尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会 逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
- 任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
- 下面的查询也将导致全表扫描:(不能前置百分号)
select id from t where name like ‘%c%’
若要提高效率,可以考虑全文检索。
4. 添加索引语句
/*添加PRIMARY KEY(主键索引) */
mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
/*添加UNIQUE(唯一索引) */
mysql>ALTER TABLE `table_name` ADD UNIQUE ( `column` )
/*添加INDEX(普通索引) */
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
/*添加FULLTEXT(全文索引) */
mysql>ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
/*添加多列索引 */
mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )