



————————————











————————————

前两期我们讲解了HashMap的基本原理,以及高并发场景下存在的问题。没看过的小伙伴可以点击下面链接:
如果实在懒得看也没有关系,我们来简单回顾一下HashMap的结构:
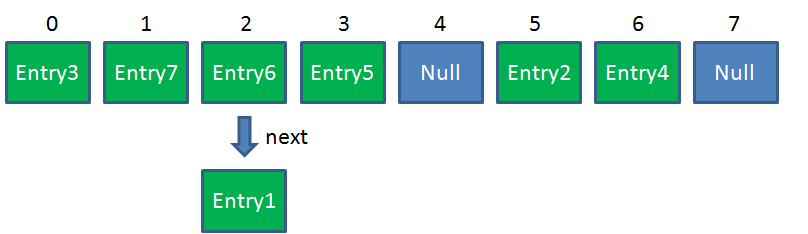
简单来说,HashMap是一个Entry对象的数组。数组中的每一个Entry元素,又是一个链表的头节点。
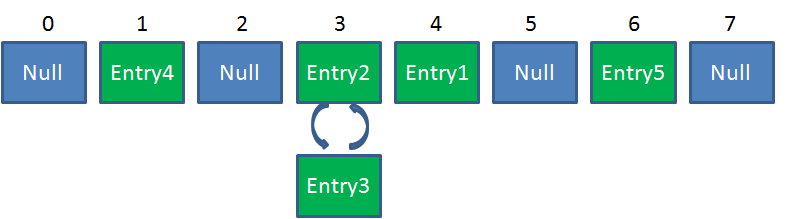
Hashmap不是线程安全的。在高并发环境下做插入操作,有可能出现下面的环形链表:


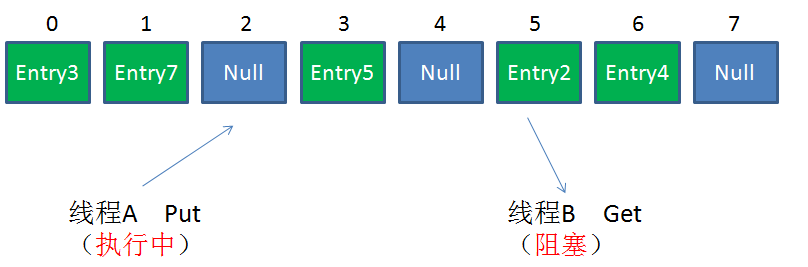
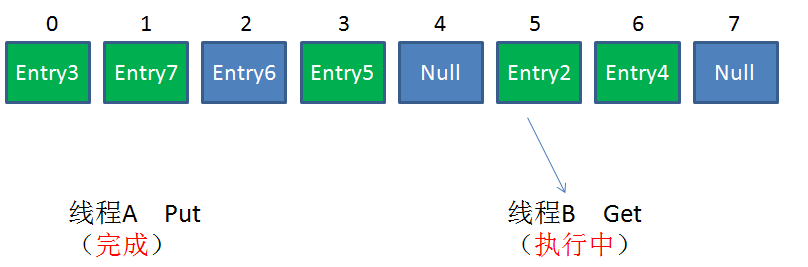



Segment是什么呢?Segment本身就相当于一个HashMap对象。
同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
单一的Segment结构如下:
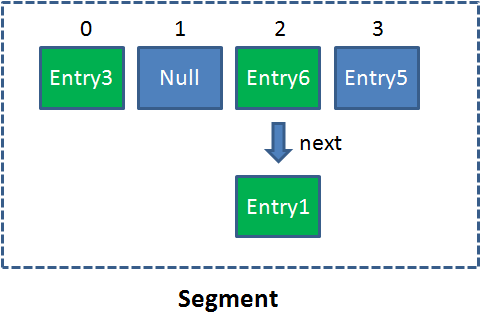
像这样的Segment对象,在ConcurrentHashMap集合中有多少个呢?有2的N次方个,共同保存在一个名为segments的数组当中。
因此整个ConcurrentHashMap的结构如下:
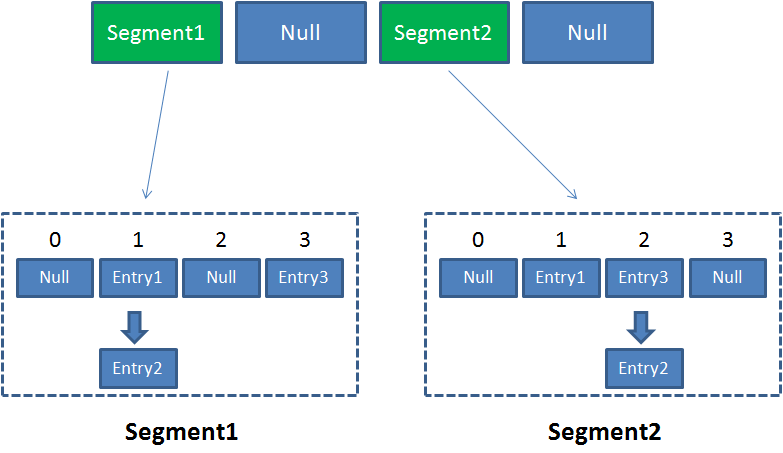
可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
这样的二级结构,和数据库的水平拆分有些相似。

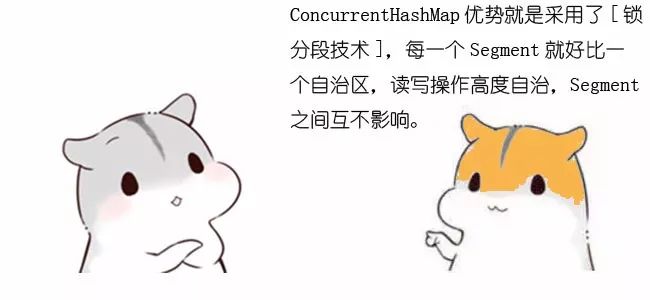

Case1:不同Segment的并发写入
不同Segment的写入是可以并发执行的。
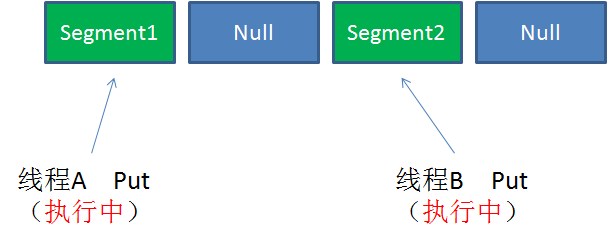
Case2:同一Segment的一写一读
同一Segment的写和读是可以并发执行的。
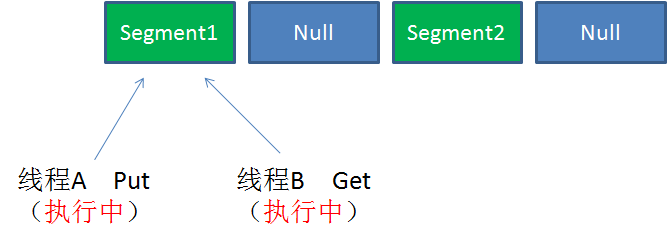
Case3:同一Segment的并发写入
Segment的写入是需要上锁的,因此对同一Segment的并发写入会被阻塞。
由此可见,ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。


Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。


Size方法的目的是统计ConcurrentHashMap的总元素数量, 自然需要把各个Segment内部的元素数量汇总起来。
但是,如果在统计Segment元素数量的过程中,已统计过的Segment瞬间插入新的元素,这时候该怎么办呢?
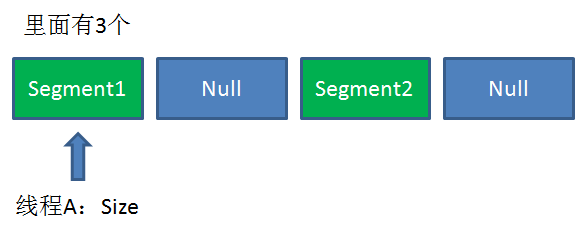
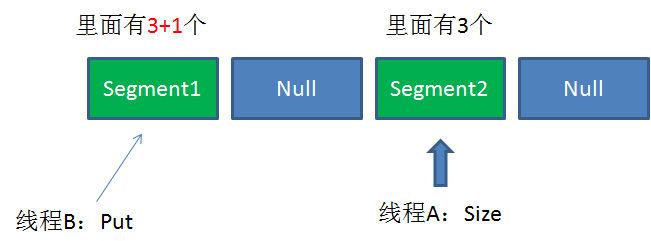


ConcurrentHashMap的Size方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
为什么这样设计呢?这种思想和乐观锁悲观锁的思想如出一辙。
为了尽量不锁住所有Segment,首先乐观地假设Size过程中不会有修改。当尝试一定次数,才无奈转为悲观锁,锁住所有Segment保证强一致性。

几点说明:
1. 这里介绍的ConcurrentHashMap原理和代码,都是基于Java1.7的。在Java8中会有些许差别。
2.ConcurrentHashMap在对Key求Hash值的时候,为了实现Segment均匀分布,进行了两次Hash。有兴趣的朋友可以研究一下源代码。
转载自:http://www.sohu.com/a/205451532_684445