1. 赛题背景
通过自动化细胞核检测,有利于检测细胞对各种治疗方法的反应,了解潜在生物学过程。队伍需要分析数据观察模式,抽象出问题并通过建立计算机模型识别各种条件下的一系列细胞核。
2. 数据预处理
数据分析
数据集包含部分的分割核图像。由于其获取方式、细胞类型、放大倍数和呈现模式不同(brightfield vs. fluorescence),对算法的抽象概括能力较高。
对于每个图片都有对应的ImageId,训练集包含有原始图片和图中每个细胞核的分割图像,对于测试集只有原始图片。
- 其中训练集有670幅图片,测试集1有65幅图片,测试集2有3019幅图。
- 训练集中共有9种分辨率图片,测试集1有11种,测试集2有26种。
- 对于原始图片,分为灰度图和彩图。(虽然都是3或者四通道,但是其中有些图片多个通道数值一样,实际为灰度图。)
- 训练集的每一张图片对应多个mask,即一张图中会有多个细胞核。
图片大小归一化
对于不同分辨率的图片,我们使用skimage.transform.resize将图片的分辨率统一为256x256。之所以选择这个分辨率,是因为大部分图片都是此分辨率。
同时对于训练集中出现的灰度图片(只有一个),将其转换为三通道相同的RGB图片以便被预测。
训练集mask分割
训练集中一副图片包含多个单细胞核的mask,当我们将所有mask合并时,难免mask之间会重叠,为了将合并后的图中mask之间分隔开。我们使用将重叠置为0。下面为处理前后的结果。
但是分析发现本赛题的数据中mask之间几乎没有重叠,大部分mask都是十分接近,因此我们将单个mask识别出边界,然后对边界使用合成图片,对于边界重叠的地方像素置为0以分隔开mask。
下图为获得的边界重叠: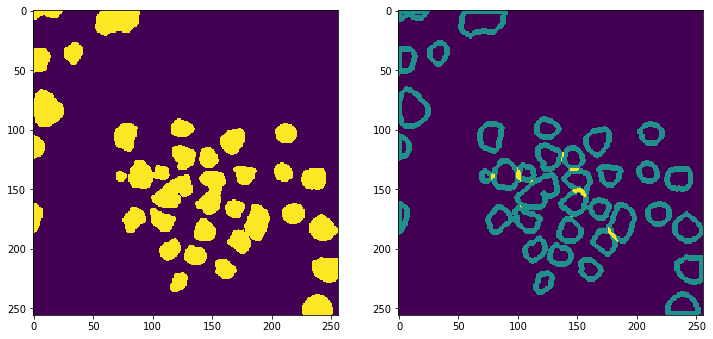
对于重叠的边界我们将其化为背景,来将每个细胞核分开,分割后的效果见下图
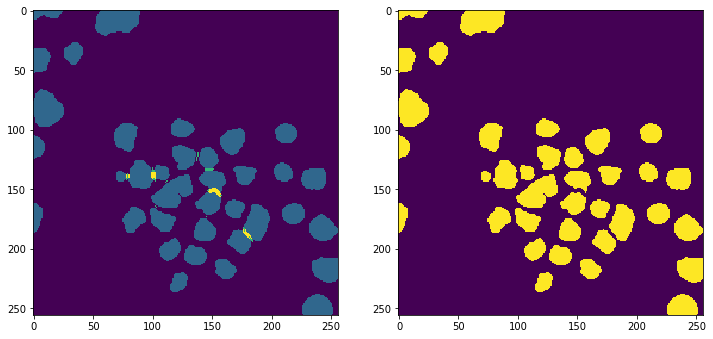
之后将其转化为bool类型矩阵,上述操作将成绩提高了0.01左右。
3. U-Net
建模
我们假设图像中有两个类,一类是背景,另一类是细胞核,即转化为一个二分类问题,因此,构建一个目标是预测一个bool类型的矩阵,即对应像素点是否为细胞核。
Architecture
U-Net实际是一个端到端的完全卷积编码网络,我们基于论文 U-Net: Convolutional Networks for Biomedical Image Segmentation 和 this repo。
结构包含收缩路径(contracting path)和对称扩展路径(symmetric expanding path),收缩路径是典型的卷积编码网络,每一层卷积核大小是3x3,并通过一个ReLU和2x2的最大池化操作组成一次下采样。每一个下采样后将特征通道数加倍。扩展路径每一层对特征映射进行上采样,包含2x2的上卷积,同样3x3的卷积核和ReLU层。在最后一层使用1x1卷积来将16个特征分量映射到类别中(即正负,是否为核)。
网络结构见下图,

3.1 Training
选用损失函数为binary_crossentropy,即
其中l是每个像素的真实标签,w是权重地图,表示训练中某些像素更加重要。
使用adam优化器来训练网络。训练过程中为了防止过拟合,将训练节划分1/10作为验证集,通过keras的callbacks函数中添加early_stopper和check_pointer来提前停止训练并保存最优的模型。验证函数见下公式,加入smooth是为了防止分母出现0。
实现如下。
# Metric function
def dice_coef(y_true, y_pred):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)3.2 visualization
通过keras调用tensorboard来可视化整个训练的过程,前期通过较大的迭代次数下,观察我们验证集上的验证函数dice_coef和binary_crossentropy的变化曲线,选择在曲线的梯度较小的迭代次数。
训练过程见下图,结合图分析在30次迭代时曲线下降的梯度已经较小,因此选择了30次迭代。
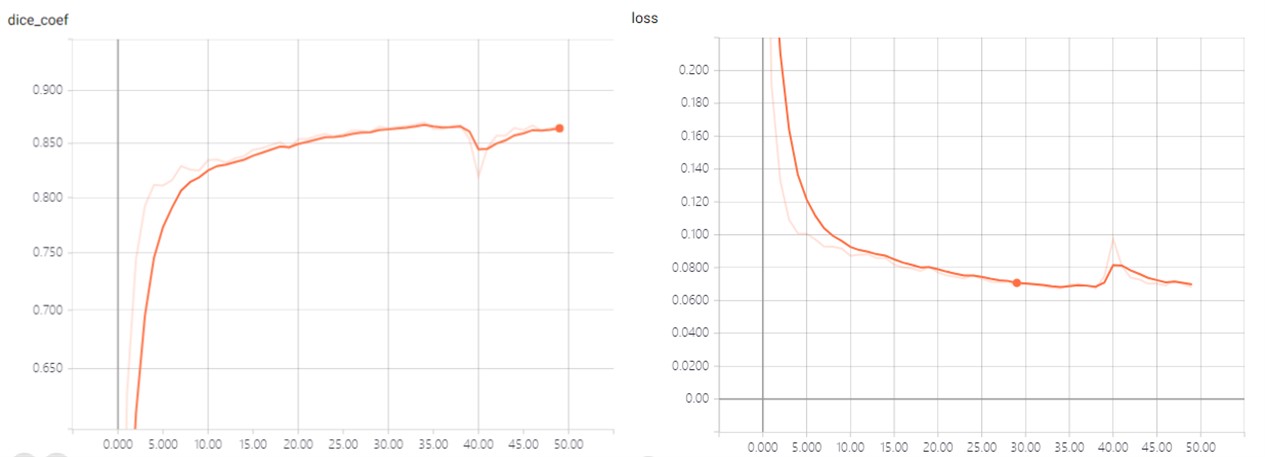
3.3 Result
U-Net预测结果
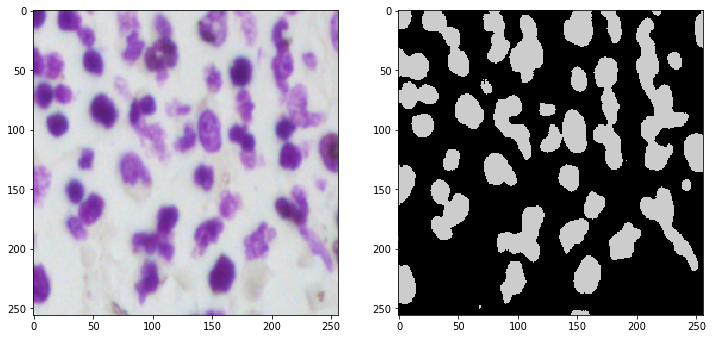
4. Post Process
分析U-Net输出结果发现,图像中重叠的细胞核被分到成了一个核,如何分理处单个的核。
我们假设核是凸的,通过凸性分析来分离被合并的核。
在分析分割前后的图片,我们发现有不错的分割也有过分割的案例,但是总体上来说好的分割多于坏的,同时也需要改进我们的分割方法。
分割后的前后结果:
单个对比:
整个对比

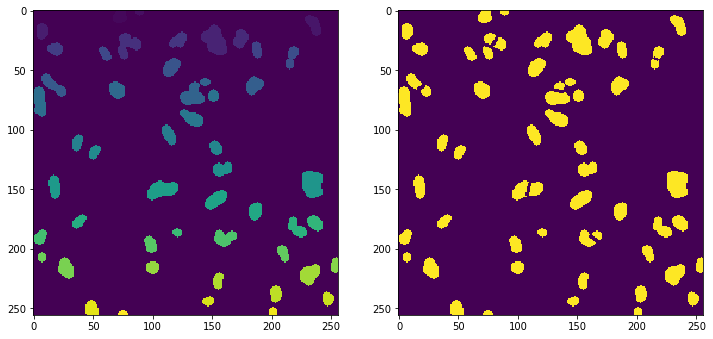
使用post process之后,整体成绩提高了0.04。
最终将mask转换为RLE编码参考于代码https://www.kaggle.com/rakhlin/fast-run-length-encoding-python
Conclusion
最终的方法即上面介绍的方法,最好的成绩是0.412,被选为最终提交的结果成绩是0.398,排名是507。
由于U-Net是一种端到端的方法,加上合适的数据预处理和后处理,使得最终能够对每个像素点做出预测。
建模过程和使用数据前文已经介绍。
通过adam优化器来训练网络使得损失降低。模型训练中通过keras的callbacks函数中添加early_stopper和check_pointer来提前停止训练并保存最优的模型。
- 本实验是一个目标检测的问题。数据集是医疗方面的数据。因此算法使用了针对小数据的U-Net.
Submit
| model | score |
|---|---|
| pixel threshold | 0.20 |
| base U-Net | 0.236 |
| U-Net V2 | 0.334 |
| U-Net with preprocess | 0.359 |
| U-Net with preprocess and postprocess | 0.412 |
| Add Batch Normalization | 0.426 |
Discussion
- 对于原始图片直接resize为固定的256x256,对于部分图形会有一定程度的变形(但是生物学上讲细胞变形很正常),可以尝试对图像使用padding查看效果。
- 看了很多大神预处理用了erosion operation,还未尝试。
- 模型只用了U-Net,还未来得及尝试其他模型。
- post process还可以继续深入做,对于细胞形态学深度地研究。
github源码:https://github.com/InsaneLife/nucleus_detection
持续更新中。。。。。
原文出处:https://blog.csdn.net/shine19930820/article/details/80098284
Reference
- https://www.kaggle.com/rakhlin/fast-run-length-encoding-python
- 『 论文阅读』U-Net Convolutional Networks for Biomedical Image Segmentation
- https://www.kaggle.com/rexhaif/morphological-postprocessing-on-unet-lb-0-429/notebook
- https://www.kaggle.com/voglinio/separating-nuclei-masks-using-convexity-defects
- https://www.kaggle.com/keegil/keras-u-net-starter-lb-0-277?scriptVersionId=2164855
- https://github.com/jocicmarko/ultrasound-nerve-segmentation