在Linux系统中,每个NUMA体系下只有一个Node,而node下面一般会有三个zone,分别为NORMAL ZONE,DMA ZONE以及HIGHMEM ZONE,其中HIGHMEM ZONE为32位系统特有的ZONE,通过分析各种android手机中的zone发现,每个系统只会有2个zone,其中32位系统一般为HIGHMEM ZONE和NORMAL ZONE,而64位系统一般不会有HIGHMEM ZONE,它一般会有NORMAL ZONE和DMA ZONE。
先讲32位系统ZONE size的设置:
函数调用流程为如下:
start_kernel()->setup_arch()->paging_init()->bootmem_init()->zone_sizes_init()
初始化的主要函数是zone_sizes_init(),代码如下:
static void __init zone_sizes_init(unsigned long min, unsigned long max_low,
unsigned long max_high)
{
unsigned long zone_size[MAX_NR_ZONES], zhole_size[MAX_NR_ZONES];
struct memblock_region *reg;
/*
* initialise the zones.
*/
memset(zone_size, 0, sizeof(zone_size));
/*
* The memory size has already been determined. If we need
* to do anything fancy with the allocation of this memory
* to the zones, now is the time to do it.
*/
zone_size[0] = max_low - min;
#ifdef CONFIG_HIGHMEM
zone_size[ZONE_HIGHMEM] = max_high - max_low;
#endif
/*
* Calculate the size of the holes.
* holes = node_size - sum(bank_sizes)
*/
memcpy(zhole_size, zone_size, sizeof(zhole_size));//将zone_size的值赋给zhole_size
for_each_memblock(memory, reg) {
unsigned long start = memblock_region_memory_base_pfn(reg);
unsigned long end = memblock_region_memory_end_pfn(reg);
if (start < max_low) {
unsigned long low_end = min(end, max_low);
zhole_size[0] -= low_end - start; //zhole_size减掉memblock type为memory的region,剩下的就是memblock type为reserved
}
#ifdef CONFIG_HIGHMEM
if (end > max_low) {
unsigned long high_start = max(start, max_low);
zhole_size[ZONE_HIGHMEM] -= end - high_start;//同上描述,一个是highmem zone,还有一个是normal zone
}
#endif
}
#ifdef CONFIG_ZONE_DMA
/*
* Adjust the sizes according to any special requirements for
* this machine type.
*/
if (arm_dma_zone_size)
arm_adjust_dma_zone(zone_size, zhole_size,
arm_dma_zone_size >> PAGE_SHIFT);
#endif
free_area_init_node(0, zone_size, min, zhole_size);
}函数有三个参数:
min:内存的起始地址的页帧号;
max_low:highmemory高端内存的起始地址页帧号;
max_high:高端内存的结束地址,也是内存的结束地址页帧号;
由上可得zhole_size数据的内容为各个zone空间reserved的memory的页数。
其初始化如下:
static void __init find_limits(unsigned long *min, unsigned long *max_low,
unsigned long *max_high)
{
*max_low = PFN_DOWN(memblock_get_current_limit());
*min = PFN_UP(memblock_start_of_DRAM());
*max_high = PFN_DOWN(memblock_end_of_DRAM());
}其中max_low为memblock的current_limit值,其值为当前memblock的大小限制,其值初始化代码如下:
void __init sanity_check_meminfo(void)
{
phys_addr_t memblock_limit = 0;
int highmem = 0;
phys_addr_t vmalloc_limit = __pa(vmalloc_min - 1) + 1;
struct memblock_region *reg;
#ifdef CONFIG_ENABLE_VMALLOC_SAVING
struct memblock_region *prev_reg = NULL;
for_each_memblock(memory, reg) {
if (prev_reg == NULL) {
prev_reg = reg;
continue;
}
vmalloc_limit += reg->base - (prev_reg->base + prev_reg->size);
prev_reg = reg;
}
#endif
for_each_memblock(memory, reg) {
phys_addr_t block_start = reg->base;
phys_addr_t block_end = reg->base + reg->size;
phys_addr_t size_limit = reg->size;
if (reg->base >= vmalloc_limit)
highmem = 1;
else
size_limit = vmalloc_limit - reg->base;
if (!IS_ENABLED(CONFIG_HIGHMEM) || cache_is_vipt_aliasing()) {
if (highmem) {
pr_notice("Ignoring RAM at %pa-%pa (!CONFIG_HIGHMEM)\n",
&block_start, &block_end);
memblock_remove(reg->base, reg->size);
continue;
}
if (reg->size > size_limit) {
phys_addr_t overlap_size = reg->size - size_limit;
pr_notice("Truncating RAM at %pa-%pa to -%pa",
&block_start, &block_end, &vmalloc_limit);
memblock_remove(vmalloc_limit, overlap_size);
block_end = vmalloc_limit;
}
}
if (!highmem) {
if (block_end > arm_lowmem_limit) {
if (reg->size > size_limit)
arm_lowmem_limit = vmalloc_limit;
else
arm_lowmem_limit = block_end;
}
/*
* Find the first non-pmd-aligned page, and point
* memblock_limit at it. This relies on rounding the
* limit down to be pmd-aligned, which happens at the
* end of this function.
*
* With this algorithm, the start or end of almost any
* bank can be non-pmd-aligned. The only exception is
* that the start of the bank 0 must be section-
* aligned, since otherwise memory would need to be
* allocated when mapping the start of bank 0, which
* occurs before any free memory is mapped.
*/
if (!memblock_limit) {
if (!IS_ALIGNED(block_start, PMD_SIZE))
memblock_limit = block_start;
else if (!IS_ALIGNED(block_end, PMD_SIZE))
memblock_limit = arm_lowmem_limit;
}
}
}
high_memory = __va(arm_lowmem_limit - 1) + 1;
/*
* Round the memblock limit down to a pmd size. This
* helps to ensure that we will allocate memory from the
* last full pmd, which should be mapped.
*/
if (memblock_limit)
memblock_limit = round_down(memblock_limit, PMD_SIZE);
if (!memblock_limit)
memblock_limit = arm_lowmem_limit;
memblock_set_current_limit(memblock_limit);
}从以上代码可以看出current_limit值是有memblock_limit值得来,memblock_limit的等于arm_lowmem_limit,而arm_lowmem_limit等于vmalloc_limit,vmalloc_limit为vmalloc_min对应的物理地址,其中vmalloc_min值初始化如下:
static int __init early_vmalloc(char *arg)
{
unsigned long vmalloc_reserve = memparse(arg, NULL);
if (vmalloc_reserve < SZ_16M) {
vmalloc_reserve = SZ_16M;
pr_warn("vmalloc area too small, limiting to %luMB\n",
vmalloc_reserve >> 20);
}
if (vmalloc_reserve > VMALLOC_END - (PAGE_OFFSET + SZ_32M)) {
vmalloc_reserve = VMALLOC_END - (PAGE_OFFSET + SZ_32M);
pr_warn("vmalloc area is too big, limiting to %luMB\n",
vmalloc_reserve >> 20);
}
vmalloc_min = (void *)(VMALLOC_END - vmalloc_reserve);
return 0;
}其中VMALLOC_END为VMALLOC区域的结束地址,为0xff800000,VMALLOC_OFFSET为VMALLOC区域相对于HIGHMEM起始地址的偏移8MB,而VMALLOC区域大小为kernel启动是BootLoader通过cmdline传进来的参数为496MB,所以由以上初始化函数可以得出,vmalloc_min的值为highmem开始的地址0xe0800000。
例如如下log:
[ 0.000000] <0> vector : 0xffff0000 - 0xffff1000 ( 4 kB)
[ 0.000000] <0> fixmap : 0xffc00000 - 0xfff00000 (3072 kB)
[ 0.000000] <0> vmalloc : 0xe1000000 - 0xff800000 ( 488 MB)
[ 0.000000] <0> lowmem : 0xc0000000 - 0xe0800000 ( 520 MB)
[ 0.000000] <0> pkmap : 0xbfe00000 - 0xc0000000 ( 2 MB)
[ 0.000000] <0> modules : 0xbf000000 - 0xbfe00000 ( 14 MB)
[ 0.000000] <0> .text : 0xc0008000 - 0xc1000000 (16352 kB)
[ 0.000000] <0> .init : 0xc1600000 - 0xc1800000 (2048 kB)
[ 0.000000] <0> .data : 0xc1800000 - 0xc19a273c (1674 kB)
[ 0.000000] <0> .bss : 0xc19a4000 - 0xc2545924 (11911 kB) #define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))以上的high_memory的值等于vmalloc_min的值为0xe0800000,所以VMALLOC_START的值为0xe1000000。而整个vmalloc区域的大小为0xff800000-0xe1000000=488MB.
多嘴一句:当cmdline里面不包含vmalloc区域的大小,则其初始化按照如下语句:
static void * __initdata vmalloc_min =
(void *)(VMALLOC_END - (240 << 20) - VMALLOC_OFFSET);由以上分析可以得出zone_sizes_init()函数的max_low为memblock的current_limit值,即为highmem的起始地址。
分析完上面的参数之后,接着需要分析的是zone的初始化,zone的初始化从free_area_init_node()开始:
void __paginginit free_area_init_node(int nid, unsigned long *zones_size,
unsigned long node_start_pfn, unsigned long *zholes_size)
{
pg_data_t *pgdat = NODE_DATA(nid);
unsigned long start_pfn = 0;
unsigned long end_pfn = 0;
/* pg_data_t should be reset to zero when it's allocated */
WARN_ON(pgdat->nr_zones || pgdat->classzone_idx);
pgdat->node_id = nid;//只有一个node,所以nid为0
pgdat->node_start_pfn = node_start_pfn;//node的起始页帧号为物理地址的起始页帧号
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
get_pfn_range_for_nid(nid, &start_pfn, &end_pfn);
printk(KERN_INFO "Initmem setup node %d [mem %#010Lx-%#010Lx]\n", nid,
(u64) start_pfn << PAGE_SHIFT, (u64) (end_pfn << PAGE_SHIFT) - 1);
#endif
calculate_node_totalpages(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);//计算kernel总的可用内存
alloc_node_mem_map(pgdat);//为所有的物理页面分配存储空间,并将起始页框地址保存在padat->node_mem_map中,也就是初始化pgdat->node_mem_map
#ifdef CONFIG_FLAT_NODE_MEM_MAP
printk(KERN_DEBUG "free_area_init_node: node %d, pgdat %08lx, node_mem_map %08lx\n",
nid, (unsigned long)pgdat,
(unsigned long)pgdat->node_mem_map);
#endif
free_area_init_core(pgdat, start_pfn, end_pfn,
zones_size, zholes_size);
}下面看一下alloc_node_mem_map()
static void __init_refok alloc_node_mem_map(struct pglist_data *pgdat)
{
/* Skip empty nodes */
if (!pgdat->node_spanned_pages)//去掉没有内存页的node
return;
#ifdef CONFIG_FLAT_NODE_MEM_MAP
/* ia64 gets its own node_mem_map, before this, without bootmem */
if (!pgdat->node_mem_map) {//如果node_mem_map没有被初始化
unsigned long size, start, end;
struct page *map;
/*
* The zone's endpoints aren't required to be MAX_ORDER
* aligned but the node_mem_map endpoints must be in order
* for the buddy allocator to function correctly.
*/
start = pgdat->node_start_pfn & ~(MAX_ORDER_NR_PAGES - 1);//起始页帧号,以MAX_ORDER_PAGES为单位对齐
end = pgdat_end_pfn(pgdat);
end = ALIGN(end, MAX_ORDER_NR_PAGES);//终止页帧号也按照MAX_ORDER_PAGES为对齐
size = (end - start) * sizeof(struct page);//管理所有的页帧所需要的内存大小
map = alloc_remap(pgdat->node_id, size);//代码未初始化完成,此时返回NULL
if (!map)
map = memblock_virt_alloc_node_nopanic(size,
pgdat->node_id);//起始bootmem分配方式分配内存,map为内存第一个page描述符的地址
pgdat->node_mem_map = map + (pgdat->node_start_pfn - start);//map后面的偏移,由于前面在计算start时进行了一个偏移,所以此时第一个page描述符的地址也需要加上这个偏移
}//pgdat->node_mem_map里面存放的是管理所有物理页面的struct page数组的起始地址
#ifndef CONFIG_NEED_MULTIPLE_NODES
/*
* With no DISCONTIG, the global mem_map is just set as node 0's
*/
if (pgdat == NODE_DATA(0)) {
mem_map = NODE_DATA(0)->node_mem_map;
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
if (page_to_pfn(mem_map) != pgdat->node_start_pfn)
mem_map -= (pgdat->node_start_pfn - ARCH_PFN_OFFSET);
#endif /* CONFIG_HAVE_MEMBLOCK_NODE_MAP */
}
#endif
#endif /* CONFIG_FLAT_NODE_MEM_MAP */
}接下来讲free_area_init_core()
static void __paginginit free_area_init_core(struct pglist_data *pgdat,
unsigned long node_start_pfn, unsigned long node_end_pfn,
unsigned long *zones_size, unsigned long *zholes_size)
{
enum zone_type j;
int nid = pgdat->node_id;
unsigned long zone_start_pfn = pgdat->node_start_pfn;
int ret;
pgdat_resize_init(pgdat);//初始化pgdat自旋锁成员node_size_lock
#ifdef CONFIG_NUMA_BALANCING
spin_lock_init(&pgdat->numabalancing_migrate_lock);
pgdat->numabalancing_migrate_nr_pages = 0;
pgdat->numabalancing_migrate_next_window = jiffies;
#endif
init_waitqueue_head(&pgdat->kswapd_wait);//初始化两个等待队列
init_waitqueue_head(&pgdat->pfmemalloc_wait);
pgdat_page_cgroup_init(pgdat);//初始化pgdat->node_page_cgroup = NULL,若未打开CGROUP相关宏,则为空函数
for (j = 0; j < MAX_NR_ZONES; j++) {
struct zone *zone = pgdat->node_zones + j;
unsigned long size, realsize, freesize, memmap_pages;
size = zone_spanned_pages_in_node(nid, j, node_start_pfn,
node_end_pfn, zones_size);//zone实际所包含的页数
realsize = freesize = size - zone_absent_pages_in_node(nid, j,
node_start_pfn,
node_end_pfn,
zholes_size);//zone里面除去孔洞以后所包含的页数
/*
* Adjust freesize so that it accounts for how much memory
* is used by this zone for memmap. This affects the watermark
* and per-cpu initialisations
*/
memmap_pages = calc_memmap_size(size, realsize);//当前内存管理page所需要的页描述符page struct占内存总大小
if (freesize >= memmap_pages) {
freesize -= memmap_pages;去除掉page struct占用内存大小
if (memmap_pages)
printk(KERN_DEBUG
" %s zone: %lu pages used for memmap\n",
zone_names[j], memmap_pages);
} else
printk(KERN_WARNING
" %s zone: %lu pages exceeds freesize %lu\n",
zone_names[j], memmap_pages, freesize);
/* Account for reserved pages */
if (j == 0 && freesize > dma_reserve) {
freesize -= dma_reserve;//如果管理区是dma区,还得减去dma reserve部分
printk(KERN_DEBUG " %s zone: %lu pages reserved\n",
zone_names[0], dma_reserve);
}
if (!is_highmem_idx(j))
nr_kernel_pages += freesize;//如果当前zone不是highmem,则freesize计入nr_kernel_pages,此变量描述可以一一映射的内存页数
/* Charge for highmem memmap if there are enough kernel pages */
else if (nr_kernel_pages > memmap_pages * 2)
nr_kernel_pages -= memmap_pages;//如果是highmem,则kernel pages减掉highmem部分的struct page占内存大小,应该是页面管理的page在kernel的lowmem区
nr_all_pages += freesize;//nr_all_pagees包含了highmem的pages
zone->spanned_pages = size;//zone的spanned,present and managed pages初始化位置
zone->present_pages = realsize;
/*
* Set an approximate value for lowmem here, it will be adjusted
* when the bootmem allocator frees pages into the buddy system.
* And all highmem pages will be managed by the buddy system.
*/
zone->managed_pages = is_highmem_idx(j) ? realsize : freesize;//如果是highmem,则present和managed是一样的,如果不是,则present要大于managed
#ifdef CONFIG_NUMA
zone->node = nid;
zone->min_unmapped_pages = (freesize*sysctl_min_unmapped_ratio)
/ 100;
zone->min_slab_pages = (freesize * sysctl_min_slab_ratio) / 100;
#endif
zone->name = zone_names[j];
spin_lock_init(&zone->lock);
spin_lock_init(&zone->lru_lock);
zone_seqlock_init(zone);
zone->zone_pgdat = pgdat;
zone_pcp_init(zone);//zone的一些初始化
/* For bootup, initialized properly in watermark setup */
mod_zone_page_state(zone, NR_ALLOC_BATCH, zone->managed_pages);
lruvec_init(&zone->lruvec);//lru初始化
if (!size)
continue;
set_pageblock_order();//设置全局pageblock_order
setup_usemap(pgdat, zone, zone_start_pfn, size);//计算和分配pageblock_flag所需要的内存大小
ret = init_currently_empty_zone(zone, zone_start_pfn,
size, MEMMAP_EARLY);//初始化伙伴系统的free_area列表以及
BUG_ON(ret);
memmap_init(size, nid, j, zone_start_pfn);//将zone所有page都设置为初始默认值,可以理解为初始化每个struct page。
zone_start_pfn += size;
}
}参数:
pgdat: 内存node的描述符;
node_start_pfn和node_end_pfn: node起始和结束页帧号;
zones_size: zone的大小(包含孔洞);
zhole_size: 内存孔洞的大小。
static void __init setup_usemap(struct pglist_data *pgdat,
struct zone *zone,
unsigned long zone_start_pfn,
unsigned long zonesize)
{
unsigned long usemapsize = usemap_size(zone_start_pfn, zonesize);
zone->pageblock_flags = NULL;
if (usemapsize)
zone->pageblock_flags =
memblock_virt_alloc_node_nopanic(usemapsize,
pgdat->node_id);
}setup_usemap()函数首先通过usemap_size()计算出管理所有的pageblock所需要的memory大小,管理每个pageblock需要4bit来存放MYGRATE_TYPE,则每个zone管理pageblock所需的memory大小就是pageblock个数乘以4bit。然后通过memblock_virt_alloc_node_nopanic()函数来分配内存,起始地址存放在zone->pageblock_flags.
调用init_currently_empty_zone()函数初始化free_area列表的nr_free和nr_free_cma以及free_area列表下的migrate_type链表.伙伴系统结构如下:
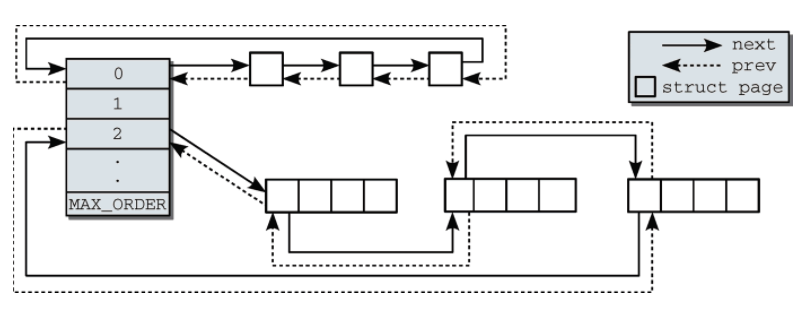
至此memory zone的初始化就讲完了。