5 .2 .2 连接
在正式环境下运行的系统中,往往存在大量的表关联情景,因此表连接的问题也就成
为了影响性能的重要因素。下面介绍一下连接问题。
1. 连接顺序
连接顺序经常会影响查询优化,因为不同的连接顺序所产生的优化方式会不同。在同
一个时刻,表连接只能是两表(或者是数据集,也就是表的一部分)之间的连接,其中用到
的关联条件(通常是列)则称为关联谓词。所以如果有n个表关联,那么必须进行n-1次关 联操作。但是需要说明的是,第一次关联并不一定就是后续关联的开始。
优化器在决定相关关联的时候,需要考虑两个方面:
□关联顺序的选择。
□关联算法的选择。
需要注意的是,编写T-SQL的表关联顺序不一定就是最终物理实现的顺序,优化器会
根据实际情况调整顺序。
2. 连接种类
SQL Server有 3 种物理连接:Nested Loop (嵌套循环)、Merge Join (合并联接)、Hash Join (哈希联接)。T-SQL中 的 inner/left/right/full join等在进行优化的过程中会转换成上面
的3 种物理连接。需要说明的是,没有绝对好的连接,只有最合适的连接。下面针对这3种物理连接逐一进行介绍。
(1 ) Nested Loop (嵌套循环)
先来看以下查询的实际执行计划。
USE A d v e n tu r e W o r k s 2 0 0 8R2
GO
SELECT e . B u s i n e s s E n t i t y l D FROM H u m a n R e s o u r c e s . E m p lo y e e AS e INNER JO IN S a l e s . S a l e s p e r s o n AS s ON e . B u s i n e s s E n t i t y l D = s . B u s i n e s s E n t i t y l D
执 行 计 划 如 图 5-2所示。
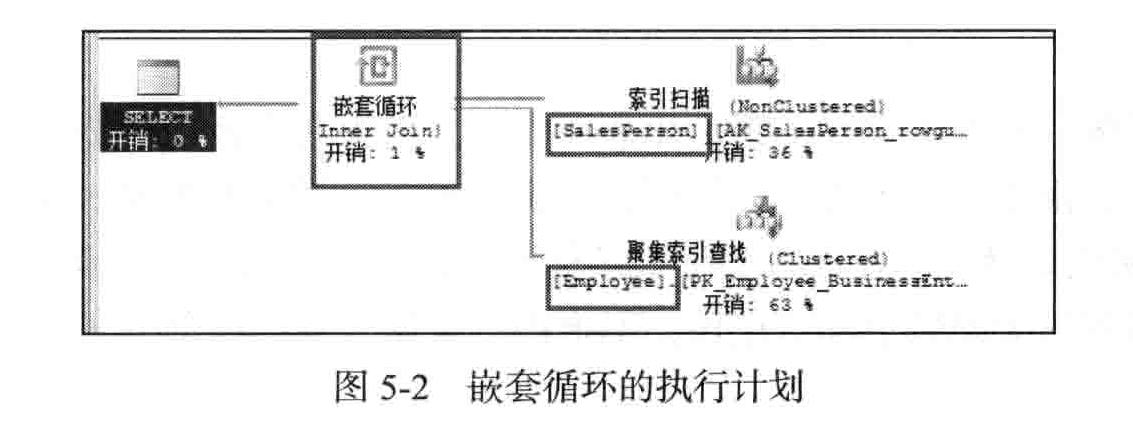
在嵌套循环中,处于上方的输入叫做外部输入,处于下方的输人叫做内部输人。这里
的 Salesperson为 外 部 输 人 ,Employee为 内 部 输 人 。嵌 套 循 环 的 算 法 很 简 单 :它将一个联 接输人当作外部输人表(显示为图形执行计划中的顶端输人),将另一个联接输人当作内部
(底端)输人表。外部循环逐行处理外部输人表。内部循环会针对每个外部行在内部输入表
中进行搜索,以找出匹配行。如果把鼠标移到内部输人中可以看到,通过聚集索引查找,
返回了 17行数据,也就是说外部输人要进行17次匹配,如 图 5-3所示
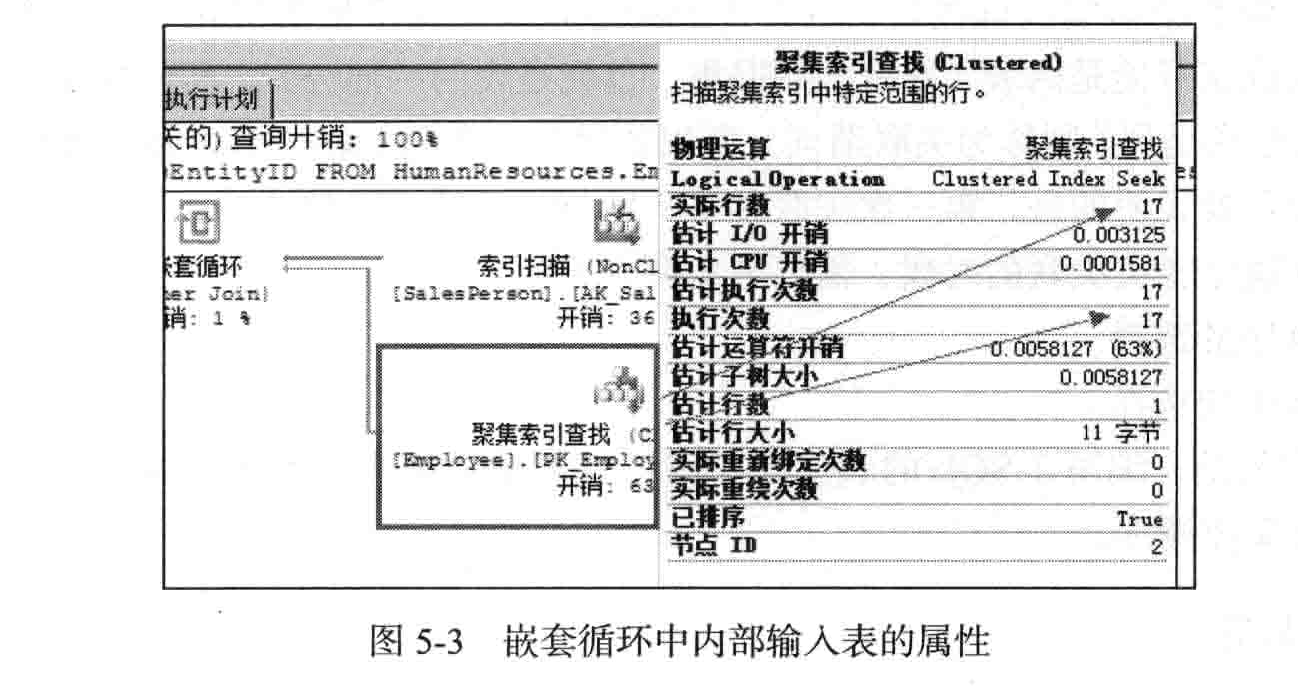
简单来说,在嵌套循环中,外部输人的操作符会被执行一次,内部输人中的每一行都
会和外部输人进行匹配,这种算法的开销是基于外部输人的行数乘以内部输入的行数来确
定的。当外部连接很小,并且内部连接在连接列上有索引时,优化器会倾向使用这种算法。
这种算法在外部输人可能很大,但是只有少数行可以和内部输人匹配上时尤其高效。这种
潜在信息需要依据统计信息得知。
(2 ) Merge Join (合并联接)
下面看看Merge Join语句的实际执行计划。
USE AdventureWorks2008R2
GO
SELECT Name FROM Sales.Store AS S JOIN Sales.Customer AS C ON S.BusinessEntitylD = C.CustomerlD WHERE C.TerritorylD =6
合并联接的执行计划如图5-4所示
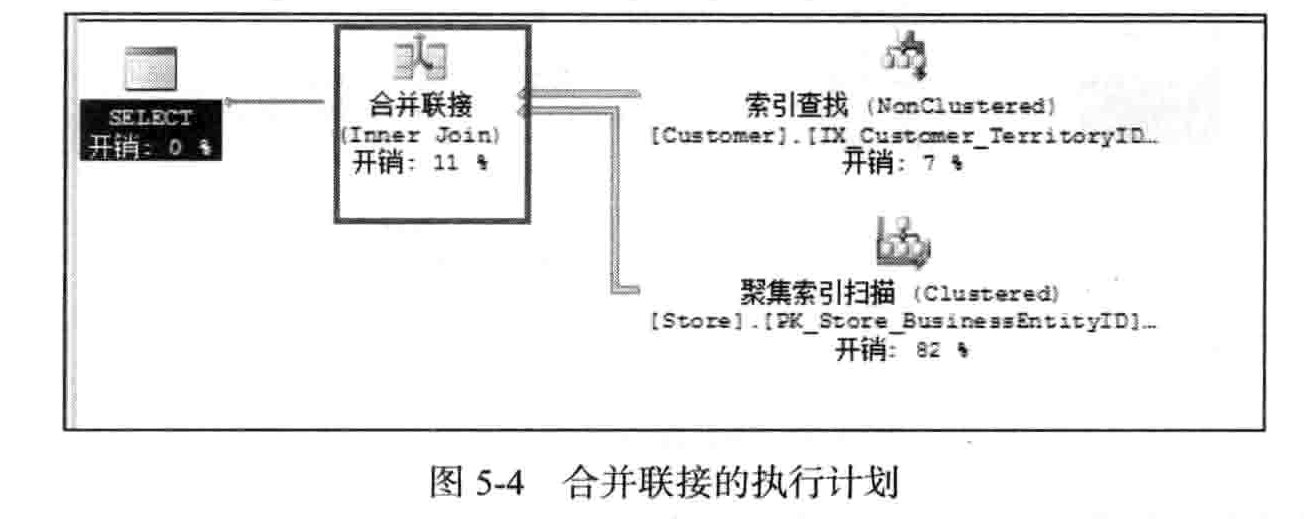
合并联接也分外部输人和内部输人,但不同的是,外部输人和内部输人都只会执行一
次。合并联接要求两个输人都在合并列上排序,而合并列由联接谓词的等效(ON)子句定
义。通常,査询优化器扫描合并列上的索引(如果在适当的一组列上存在索引,那么这个列
就有了顺序),或在合并联接的下面放一个排序运算符,从而实现合并联接中的"排序”要
求。在极少数情况下,虽然可能有多个等效子句,但只用到了其中一些可用的等效子句来
获得合并列。
由于每个输人都已排序,因此Merge Join运算符(中文版中显示合并联接)将从每个输 人中获取一行并对其进行比较。例如,对于内联接操作,如果行相等,则返回这个相等的
数据;如果行不相等,则废弃值较小的行,并从该输人中获得另一行。这一过程将重复进
行,直到处理完所有的行为止。
合并联接操作可以是常规操作(一对一),也可以是多对多操作。多对多合并联接使用
临时表存储行。如果每个输人中有重复值,则在处理其中一个输人中的每个重复项时,另
一个输入必须重新绕到重复项的开始位置,反复处理这个重复项,直到匹配完毕。
另外需要提醒的是,合并过程还需要考虑谓词条件,比如on、where中的条件。 合并联接本身的速度很快,但如果需要排序操作,选择合并联接就会非常费时。然而,
如果数据量很大且能够从现有B 树索引中获得预排序的所需数据,则合并联接通常是最快的可用联接算法。
(3 ) Hash Join (哈希联接)
以下是Hash Join语句的实际执行计划。
USE AdventureWorks2008R2
GO
SELECT pv.ProductID , v.BusinessEntitylD , v .Name FROM Purchasing.ProductVendor pv JOIN Purchasing.Vendor v ON ( pv.BusinessEntitylD = v.BusinessEntitylD ) WHERE StandardPrice > $10
如图5-5所示是哈希联接的执行计划。
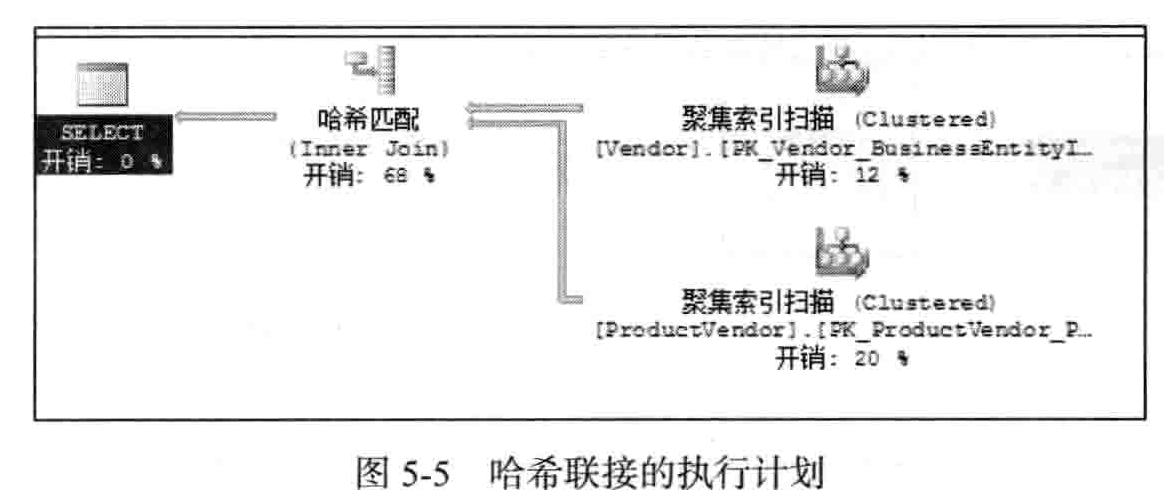
哈希联接有两种输人:生成输入和探测输入。查询优化器使用两个输入中较小的那个
作为生成输人。
哈希联接用于多种设置匹配操作:内部联接,左外部联接、右外部联接和完全外部联
接,左半联接和右半联接,交集、并集和差异。此外,哈希联接的某种变形可以进行重复
删除和分组,例如SUM(salary) GROUP BY department。对于生成和探测角色,这些修改将
只使用一个输人。
关联算法既简单又复杂,优化器根据输入的规模、统计信息、是否排序、需要查找的
列等信息,最终选出最低开销的算法。