4.4.3 应用架构
4.4.3.1 应用架构定义
应用架构定义了系统由哪些应用组成,以及应用之间如何分工和合作。
应用作为独立可部署的单元,为系统划分了明确的边界,深刻影响系统功能组织、代码开发、部署和运维等各方面。
应用架构设计过程中,应用的分有两种方式:
1.水平拆分,按照功能处理顺序划分应用,比如把系统分为web前端、中间服务、后台任务,这是面向业务深度的划分。
2.垂直拆分,按照不同的业务类型划分应用,比如进销存系统可以划分为三个独立的应用,这是面向业务广度的划分。
应用的合反映应用之间如何协作,共同完成复杂的业务,主要体现在应用之间的通讯机制和数据格式。通讯机制可以是同步调用/异步消息/共享DB访问等,数据格式可以是文本/XML/JSON/二进制等。
应用的分偏向于业务,反映业务架构,应用的合偏向于技术,影响技术架构。
在应用架构设计过程中,应用的分降低了业务复杂度,使系统更有序。应用的合增加了技术复杂度,系统更无序。
应用架构的本质是通过系统拆分,平衡业务和技术复杂性,保证系统形散神不散。
应用架构设计的初衷是为了减少应用程序之间的关系,让系统内部程序实现松耦合。
4.4.3.2 应用架构设计原则4.4.3.2.1 架构分解原则
在系统分解过程中,可供参考的原则如下:

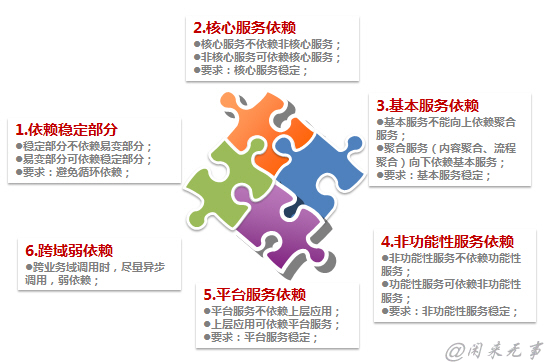
4.4.3.2.2 架构依赖原则
在系统分解和组合过程中,可供参考的原则如下:
4.4.3.2.3 服务设计原则
在服务设计过程中,应该遵循如下规则:
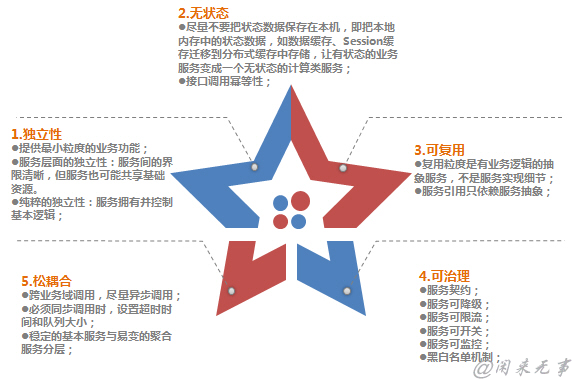
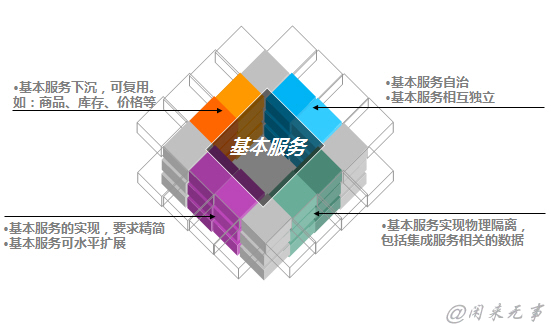
对于处于业务核心的基本服务(即原子服务),在设计过程中,还应该遵循如下规则:
4.4.3.3 应用架构实践
在应用架构设计过程中,主要考虑如下内容:
1.子系统划分:依据架构分解原则,对概念架构阶段设计的系统进行分解。
2.接口定义:明确各子系统、各模块之间的接口定义;
3.交互机制:明确各子系统、各模块之间的交互机制,如基于接口编程、消息机制或RPC调用等;
在进行应用架构设计时,应该根据系统的复杂性进行合理的拆分、组合,然后针对不同的部分,分别进行描述。
1.对于简单的系统,如系统内部由少量的子系统、模块构成,并且与外围系统交互比较少,甚至无交互,则建议在一张应用架构视图上表现整体系统的组件、接口和交互机制。
2.对于复杂的系统,如系统由多个子系统组成,每个子系统由多个模块组成,并且每个子系统单独开发、测试、部署,这些子系统之间通过某种交互机制进行通讯,协作完成指定的功能集,服务于用户。另外,这些子系统需要与其它已经存在的系统进行通讯。
针对这样的系统,建议通过多张应用架构视图分别展示每个子系统的组件、接口和交互机制,以及该子系统与其它子系统的交互机制。此时,其它子系统以黑盒的方式存在,不必细化其内部组成。
在每张应用架构视图内部,如果涉及的组件比较多,并且存在比较复杂的组件,如本地数据缓存组件、自动任务调度组件等。针对这样的组件,如果以黑盒的方式展示,比较笼统,对开发人员缺乏指导和限制的作用。如果以标准的应用架构图方式展示(组件、接口、交互机制),则会与所属的子系统的展示方式存在冲突,有些喧宾夺主的效果,导致主次不分,概念混乱。对于这种情况,建议在子系统内部以黑盒的方式展示组件,然后针对这些复杂的组件,单独使用一张应用架构视图展示组件的应用架构设计;
对于子系统之间或子系统与其它系统的交互机制,如果简单、明确,则直接在应用架构视图中展示。如果比较复杂,则单独使用一张交互机制图进行补充说明;
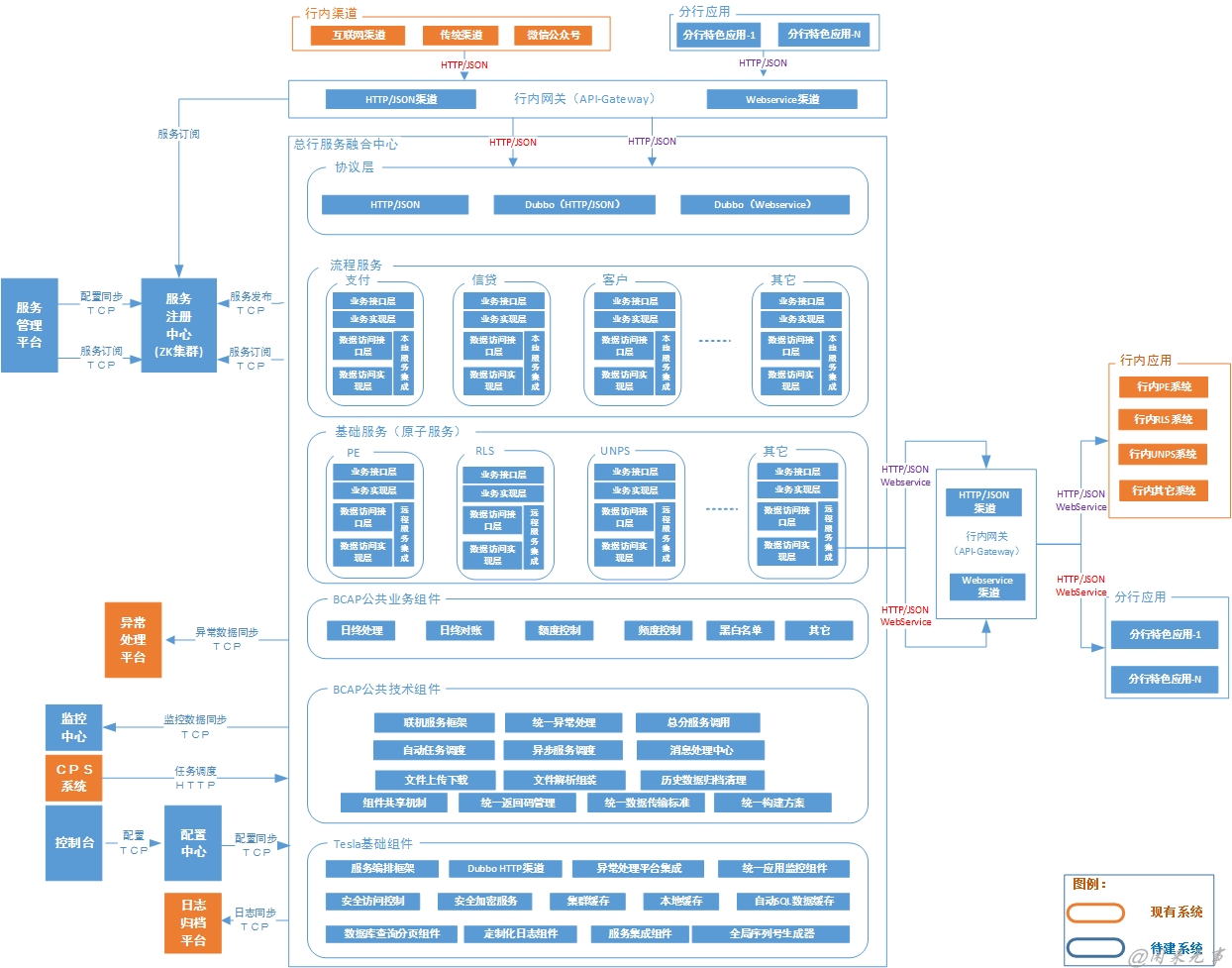
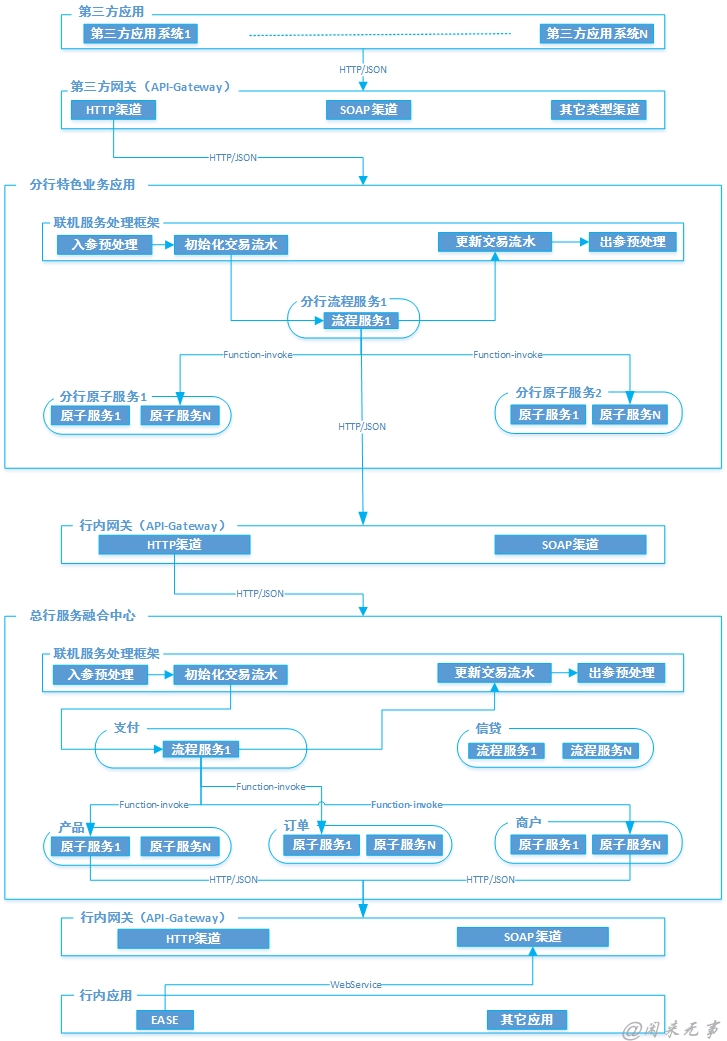
4.4.3.3.1 服务融合中心
分行特色业务云平台由多个系统构成,主要包括:特色业务总平台,即服务融合中心、特色业务分平台、控制台、监控中心、服务管理平台、特色业务开放平台、API网关等。其中每个系统又由多个子系统、模块、组件构成。针对这样比较复杂的系统,采用先整体、然后部分的多张应用架构视图进行展示,以最大限度地展示系统的组成,以及这些系统如何协作完成业务功能。
以服务融合中心为例,描述应用架构的设计过程:
1.对整个应用先按照组件的通用性进行水平拆分,从下到上依次为:Tesla基础组件层、BCAP公共技术组件层、BCAP公共业务组件层、基础服务层、流程服务层、协议层;
2.Tesla基础组件层:由于采用Tesla平台提供的组件,只需要以黑盒的方式展示所需要的组件即可,无需细化每个组件。
3.BCAP公共技术组件层:这些技术组件需要根据具体的需求进行设计、开发、测试、集成。另外,某些组件实现比较复杂。所以,在整体的应用架构视图中以黑盒的方式展示,然后针对复杂的组件,分别使用单独的视图展示组件的应用架构设计。
4.BCAP公共服务组件层:同BCAP公共技术组件层。
5.基础服务层:定义原子服务,实现服务复用。
首先按照业务域进行垂直拆分,分为RLS(零售贷款系统)、UNPS(统一网络支付系统)、PE(支付引擎)等模块;
这些模块可以集成部署在一个应用内,也可以按单个模块或几个模块的组合分别单独部署;
对于每个模块进行水平拆分,如RLS,遵循按接口编程规范的分层设计,如业务接口层、业务实现层、数据访问接口层、数据访问实现层、远程服务调用;
对于已经在总行核心业务系统中实现的服务,不进行二次开发,而是直接按照原子服务开发规范进行封装,在业务实现层通过Tesla平台提供的基于Dubbo客户端访问远程服务的功能调用远程服务;
对于未在总行核心业务系统中实现的服务,按照业务需求进行二次开发;
每个原子服务要独立完成一个完整的功能;
对于参与到补偿型TCC分布式事务模型的原子服务,必须提供对应的冲正服务,用于业务补偿,抵消或部分抵消正向业务操作的业务结果,冲正服务满足幂等性;
原子服务只供流程服务通过本地调用(即JVM内部调用)方式调用,不对外提供服务,即其它系统无法直接访问原子服务。原因:现阶段,联机服务处理框架只针对流程服务进行了接入封装,包括前置处理(初始化上下文、报文解压、验证签名、模块级个性化前处理、服务级个性化前处理、初始化接入流水等)、后置处理(服务级个性化后处理、模块级个性化后处理、更新接入流水、生成签名、压缩报文等);后期建议联机服务处理框架可以直接对原子服务进行接入封装,这样原子服务按照规范直接对外提供服务;
原子服务之间不能互相调用;
6.聚合服务层:定义流程服务,实现业务功能。
首先按照业务域进行垂直拆分,分为支付、贷款、信息查询辅助服务等模块;
这些模块可以集成部署在一个应用内,也可以按单个模块或几个模块的组合分别单独部署;
这些模块可以集群部署,实现水平扩展,以达到高性能、高可用性、可伸缩性;
对于每个模块进行水平拆分,如支付,遵循按接口编程规范的分层设计,如业务接口层、业务实现层、数据访问接口层、数据访问实现层、本地服务调用;
流程服务依赖原子服务。
当流程服务只依赖一个原子服务,则在业务实现层通过Tesla平台提供的function-invoke,在JVM内部调用原子服务;
当流程服务依赖2个及其以上个原子服务时,则通过服务编排框架进行服务编排;
在流程服务层,采用补偿型TCC分布式事务模型实现服务层的分布式事务;
流程服务通过Dubbo对外发布服务,至少支持HTTP/JSON、Webservice协议;
流程服务之间可以相互调用;
7.协议层:
针对同一个服务接口,以不同的传输协议和传输的数据格式进行发布,如HTTP/JSON、Webservice、Hessian等,支持多种渠道接入;
提供服务治理功能,如服务注册、发现、订阅机制,服务开关、服务降级、服务限流等功能;
8.接口设计
在整个架构设计过程中,采用面向接口的编程方式,实现系统架构设计层面的开闭原则(对扩展开放,对修改关闭),当系统增加新功能时,不需要对现有系统的结构和代码进行修改。
按照上述设计过程进行拆分、整合以后,服务融合中心的应用架构视图如下所示:
4.4.3.3.2 服务融合中心内部及外部的调用关系
在整体应用架构视图中,由于涉及的系统、子系统、模块、组件比较多,只能简单地展示系统、子系统、模块之间的调用关系,不够直观。因此,增加了这个视图,详细地描述系统、子系统、模块之间的调用流程。
这个视图是可选的,根据具体情况确定是否需要此视图。
4.4.3.3.3 本地数据缓存组件
针对比较复杂的技术组件、业务组件,可以进行组件级应用架构视图的设计工作。
在此以本地数据缓存组件为例。
本地数据缓存组件在本地内存中缓存运行过程中极少变动的配置数据和业务数据,以提高数据的访问速度,提高系统的高并发性。
在此基础上,增加缓存管理器、抽象的缓存实体对象、缺省的缓存实体对象、缓存更新服务(远程服务、本地服务)等功能,实现基于内存的本地数据的缓存管理功能。
另外,基于Zookeeper的Watch机制,实现集群环境中,缓存更新事件的发布与订阅,以支持该组件在集群环境中的使用。本地数据缓存管理组件应该具有如下特性:
1.缓存数据的预加载;
2.缓存数据对应用透明;
3.同时支持本地缓存更新服务、远程缓存更新服务;
4.同时支持应用级和模块级本地缓存;
5.支持通过ZK的Watch机制,实现缓存更新的监听与发布;
6.支持多实例(集群)部署;
本地数据缓存组件的应用架构如下图所示:
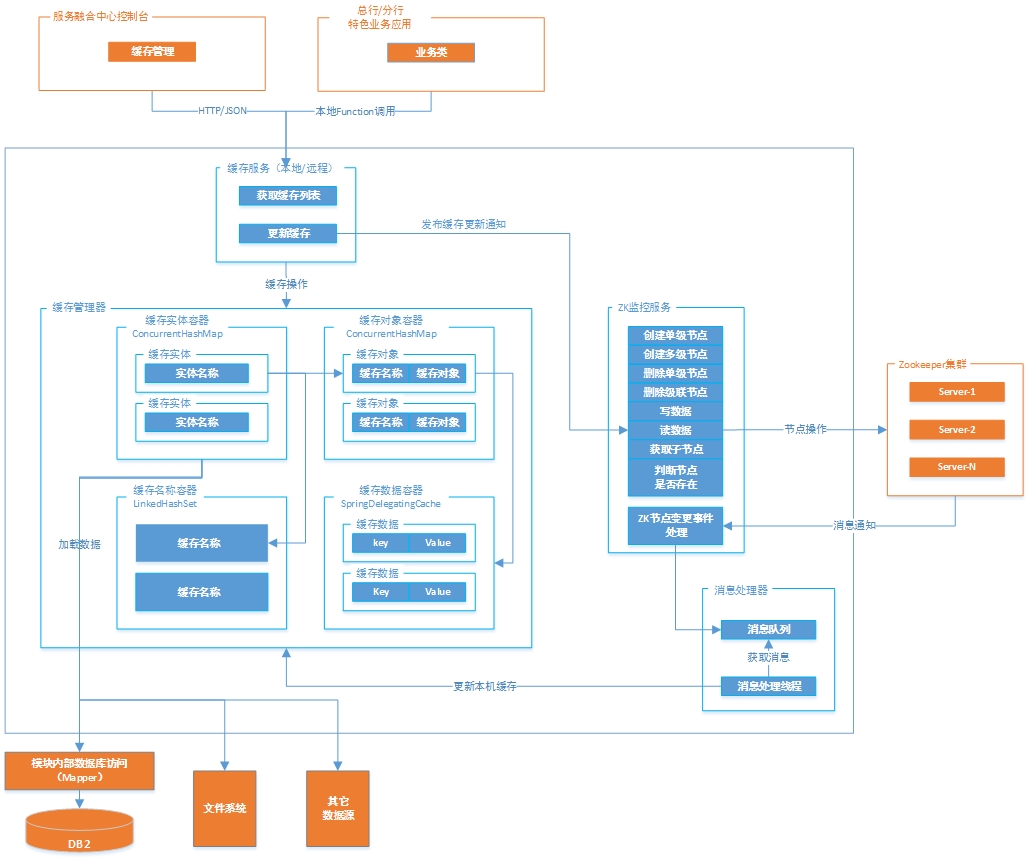
1.缓存管理器
缓存管理器主要负责缓存的存储、获取、更新、删除等;
2.ZK监控服务
基于Zookeeper的Watch机制,实现了集群环境中,缓存更新事件的发布与订阅,以及缓存通知的接收、处理,从而支持该组件在集群环境中的使用;
3.消息处理器
基于阻塞队列实现的单线程消息处理器,解耦了ZK消息监控和ZK消息处理,最大限度地提高了ZK消息处理能力,提高了组件的可用性。
4.缓存服务
提供本地和远程两种缓存更新服务。其中,本地缓存服务供应用内模块调用,远程缓存服务供控制台调用;
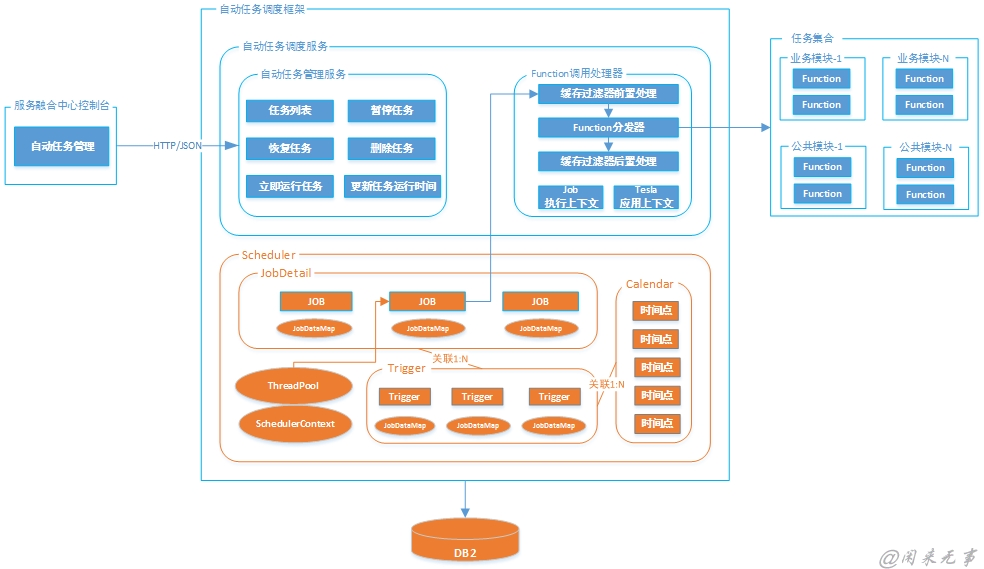
4.4.3.3.4 自动任务调度组件
自动任务调度是指基于给定时间点,给定时间间隔或者给定执行次数自动执行任务。
自动任务调度组件基于Tesla平台,使用已有开源框架Quartz(版本2.2.3),并结合Spring(版本4.2.0)实现对Tesla平台中各个模块提供的特定的Function任务的自动调度、运行,以及任务、计划的前端界面管理,具体要求如下:
1.任务定义及实现:
由于服务融合中心基于Tesla3.0平台进行开发,并且支持模块单独热部署,所以要求各模块提供的任务必须以Tesla平台Function组件提供,不接受其它任何形式的任务,如普通的Java Bean任务、实现Quartz Job接口的任务、继承Spring QuartzJobBean类的任务等。
2.任务管理功能:
为了方便管理人员维护任务,查看任务的执行状态、暂停或恢复任务的执行、修改任务的执行时间等,基于Quartz API实现相关的任务管理服务,并在服务融合中心提供管理界面,方便管理人员使用。任务管理服务主要包括:
获取任务列表(计划中的任务、运行中的任务);
暂停任务;
恢复任务;
删除任务;
立即运行任务;
更新任务运行时间;
自动任务调度组件具有如下特性:
1.支持Tesla平台Function功能的跨模块调用;
2.支持分布式任务和本地任务同时使用一套数据库表;
3.支持任务持久化;
4.支持集群和分布式任务;
5.良好的伸缩性;
6.软负载均衡;
7.高可用性;
自动任务调度组件的应用架构如下图示:
微信扫一扫,关注该公众号
该系列文章已经在微信公众号发布,如果感兴趣,请关注。
以后更多知识通过该微信公众号分享。
