知识点:
- Thread设置守护线程
- 写入csv
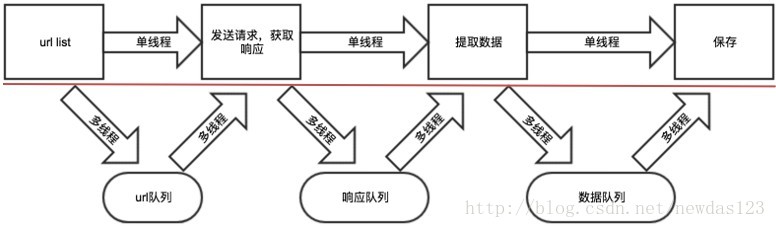
import re
from lxml import etree
import requests
from threading import Thread
from queue import Queue
class Qiubai(object):
def __init__(self):
self.queue_url = Queue()
self.queue_response = Queue()
self.queue_data = Queue()
self.main_url = 'https://www.qiushibaike.com'
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
' AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/60.0.3112.101 Safari/537.36'}
self.url_pattern = 'https://www.qiushibaike.com/8hr/page/{}/'
import csv
self.csvfile = open('qiubai_thread.csv', 'w', encoding='gbk')
fieldnames = ['username', 'laugh', 'comment', 'url', 'img_url']
self.writer = csv.DictWriter(self.csvfile, fieldnames=fieldnames)
self.writer.writeheader()
def generate_url(self):
for i in range(1,14):
self.queue_url.put(self.url_pattern.format(i))
def generate_response(self):
while True:
url = self.queue_url.get()
response = requests.get(url, headers=self.headers)
if response.status_code == 200:
print('{}请求成功'.format(url))
self.queue_response.put(response)
else:
print('{}请求失败'.format(url))
self.queue_url.put(url)
self.queue_url.task_done()
def save_to_csv(self):
while True:
data = self.queue_data.get()
self.writer.writerow(data)
self.queue_data.task_done()
def parse(self):
while True:
response = self.queue_response.get()
html = etree.HTML(response.content)
divs = html.xpath('//div[@id="content-left"]/div')
for div in divs:
item = {}
username = div.xpath('./div/a/h2/text()')
item['username'] = re.sub(r'["\s]', '' ,username[0]) if username else '匿名用户'
print(item['username'])
item['laugh'] = div.xpath('.//span[@class="stats-vote"]/i/text()')[0]
item['comment'] = div.xpath('.//span[@class="stats-comments"]/a/i/text()')[0]
item['url'] = self.main_url + div.xpath('./a/@href')[0]
img_url = div.xpath('./div[@class="thumb"]/a/img/@src')
if img_url:
img = img_url[0]
item['img_url'] = img if img.startswith('http:') else 'http:' + img
else:
item['img_url'] = 'NA'
self.queue_data.put(item)
self.queue_response.task_done()
def run(self):
thread_list = []
t_generate_url = Thread(target=self.generate_url)
thread_list.append(t_generate_url)
for i in range(3):
t = Thread(target=self.generate_response)
thread_list.append(t)
for i in range(3):
t = Thread(target=self.parse)
thread_list.append(t)
t_save = Thread(target=self.save_to_csv)
thread_list.append(t_save)
for t in thread_list:
t.setDaemon(True)
t.start()
for q in [self.queue_url, self.queue_response, self.queue_data]:
q.join()
if __name__ == '__main__':
qiubai = Qiubai()
qiubai.run()