一,mysql删除重复数据处理
首先找到所有重复的数据记录,使用如下sql语句进行
- select * from a group by cardno having count(cardno) > 1
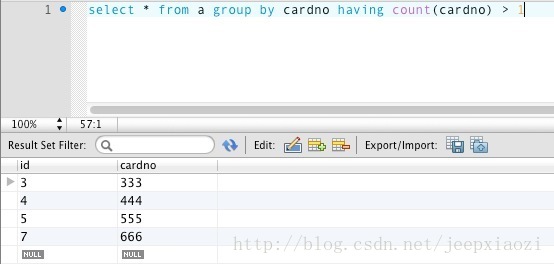
查询出来的是所有重复数据的第一条记录,但是这个是我们需要保留的,所以条件变成了,(改用如下的sql语句查询,根据cardno查询)重复数据中不包含本条记录的结果删除:
查询语句如下:
- select id,cardno from a where cardno in (select cardno from a group by cardno having count(cardno)>1)
- and id not in(select min(id) from a group by cardno having count(cardno)>1)
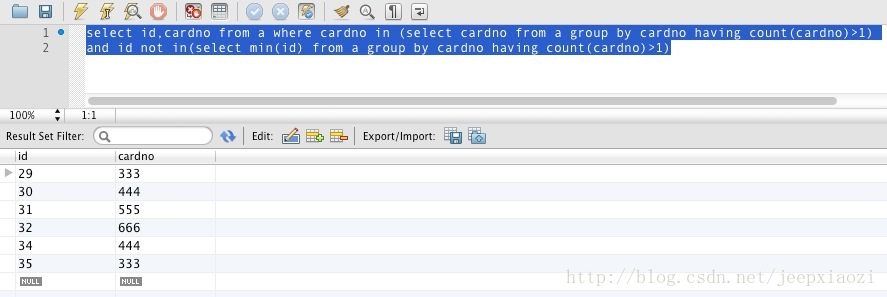
这些记录是我们需要删除的,OK,接下来我们就直接删除掉这些数据就OK了,我们根据id主键来删除,sql语句如下:
- delete from a where id in(select id from a where cardno in (select cardno from a group by cardno having count(cardno)>1)
- and id not in(select min(id) from a group by cardno having count(cardno)>1))

Oops!报错了,这条提示信息说的是,诶同学,在MySql里你不能先查询了然后再删除诶!哦,好吧,这个就只能等官方升级支持这个新特性了,但是我们现在就要解决这个棘手的问题啊,肿么办?我们用临时表来解决,然后我们的删除语句变成了,这个样子:
- delete from a where id in (select id from (select id from a where cardno in (select cardno from a group by cardno having count(cardno)>1)
- and id not in(select min(id) from a group by cardno having count(cardno)>1)) as tmpresult)
执行,OK,可以看到我们上面查询的出来要删除的6条重复数据已经被清理掉了,结果如下:

OK,那么群里的那位朋友的问题是,他只想删除固定的卡号的话该怎么办呢?
这个就相当于附加的条件筛选了,我们直接在临时表的查询里附加条件:(注:红色加粗字体是附加条件)- delete from a where id in (select id from (select id from a where cardno in (select cardno from a group by cardno having count(cardno)>1 <strong>and cardno=333</strong>)
- and id not in(select min(id) from a group by cardno having count(cardno)>1)) as tmpresult)
这样儿就完成了Mysql删除重复数据的需求。
如果不能解决任务需求:
看下面两个sql:
delete from `offcn_market_clients` where id in(select id from (select max(id) as id,telephone from `offcn_market_clients` where disabled=0 group by telephone having count(telephone)>1) as temtable );
delete from `offcn_market_clients` where id in (select id from `offcn_market_clients` where telephone in (select telephone from `offcn_market_clients` where disabled=1 group by telephone having count(telephone)>1))
二,mysql超时时间设置
(1)避免一些有性能问题的语句长时间执行占用大量资源,影响其他用户的使用;
(2)避免请求都被中断了服务端还在长时间的执行SQL语句,无谓的消耗资源;
有两种方式来设置执行超时,任选一种:
1. 客户端代码中设置
例如:使用 mysql 的 .net 驱动
MysqlCommand.CommandTimeout = xxx (秒)
驱动的实现原理:
(1)超时时间到时,驱动会另行和 mysql 建立一个连接;
(2)在新建的连接中,执行 kill query id,请求 mysql 把超时的查询给 kill 掉;
(3)mysql 接受到命令后,主动终止语句的执行,但保留链接,终止后向新连接返回成功消息;
(4)新连接收到消息后,关闭自己;
(5)抛出异常:Timeout expired. The timeout period elapsed prior to completion of the operation or the server is not responding.
**
2.服务端设置
**
mysql 5.6 及以后,有语句执行超时时间变量,用于在服务端对 select 语句进行超时时间限制;
mysql 5.6 中,名为: max_statement_time (毫秒)
mysql 5.7 以后,改成: max_execution_time (毫秒)
超过这个时间,mysql 就终止 select 语句的执行,客户端抛异常:
1907: Query execution was interrupted, max_execution_time exceeded.
三种设置粒度:
(1)全局设置
SET GLOBAL MAX_EXECUTION_TIME=1000;
(2)对某个session设置
SET SESSION MAX_EXECUTION_TIME=1000;
(3)对某个语句设置
SELECT max_execution_time=1000 SLEEP(10), a.* from test a;
查看:
mysql> show variables like 'max_execution_time';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| max_execution_time | 10000 |
+--------------------+-------+
1 row in set (0.00 sec)
目前只支持select 语句
或者用如下用法 :
select /*+ max_execution_time(3000)*/ count(*) from t1 where status=0;