这是本专题的第三节,在这一节我们将以David Silver等人的Natrue论文Mastering the game of Go without human knowledge为基础讲讲AlphaGo Zero的基本框架,力求简洁清晰,具体的算法细节参见原论文。之后我们为AlphaGo家族做一下总结,展望未来AI革命会将我们带向何方,西部世界乐园是否只能存在于美剧中?本人水平有限,如有错误还望指正。
相较AlphaGo的改进
只通过自我对局强化学习进行训练学习
无需人类大师的数据指引,只需要围棋规则知识
简化版蒙特卡洛树搜索,无需 RollOut 策略
将蒙特卡洛树搜索纳入到学习过程中,而不是只用于规划中的动作选择
策略网络和价值网络结合为一,最终网络输出为双头,动作概率和值函数
使用最先进的残差神经网络
轻微改进输入与特征,以适应更多围棋规则
值得注意的是,AlphaGo本身有多个版本,在没有特指的情况下,AlphaGo即指Nature论文里的版本
框架
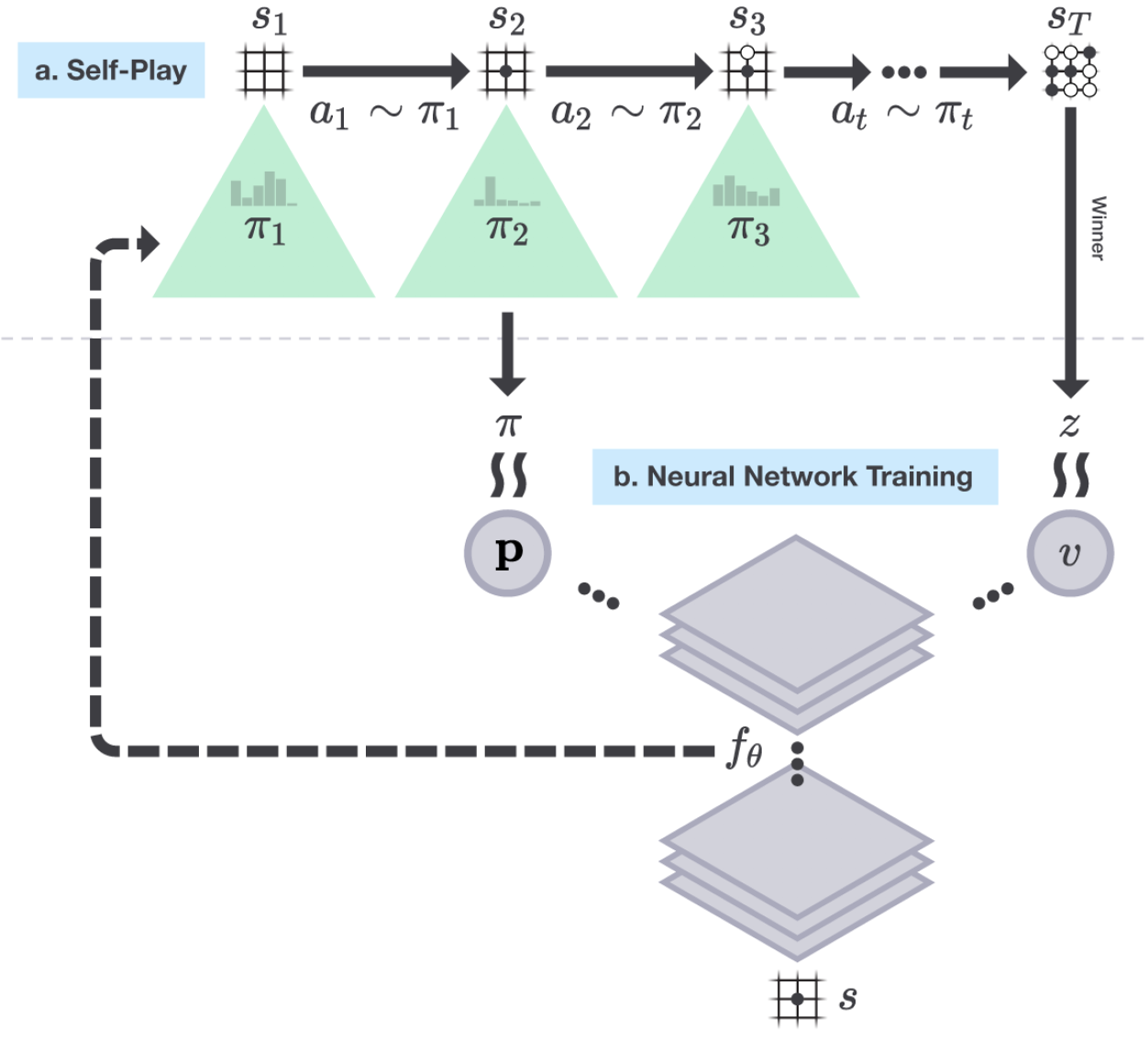
这里的自我对局强化学习采用了通用策略迭代框架。定义蒙特卡洛策略为 \(p_{aug}\),神经网络输出策略为 \(p_{out}\)。
策略评估:在自我对局中加上搜索树,对每个棋面运用蒙特卡洛搜索,选择落子位置,最终得到奖励作为棋面的评估 \(z_T\),同时得到策略 \(p_{aug}\),导入神经网络进行训练。
策略提升:对得到的评估 \(z_T\) 和策略神经网络所输出的策略 \(p_{out}\) 经过蒙特卡洛搜索得到了提升,生成了新的策略 \(p_{aug}\)。
流程
神经网络以随机权重 \(\theta_0\) 进行初始化,并设为当前最佳的网络 \(f_{\theta_*}\)
\(\qquad\)在每个循环 \(i\),用当前最佳的网络 \(f_{\theta_*}\) 进行自我对局
\(\qquad\qquad\)在每个时间点 \(t\),MCTS 使用前一次循环的神经网络 \(f_{\theta_{i-1}}\),依据动作概率进行采样 \(\pi_t = \alpha_{\theta_{i-1}}(s_t)\)
\(\qquad\)当双方都选择跳过 或 搜索时评估值低于投降线 或 棋盘无地落子,棋局结束,得到相应奖励 \(r_T\)
\(\qquad\)每个时间点的数据都存储为 \((s_t, \pi_t, z_t)\),其中 \(z_t = \pm r_T\)
\(\qquad\)从上一局自我对局的棋局中的数据 \((s, \pi, z)\) 里进行采样,训练神经网络参数 \(\theta_i\)
\(\qquad\)网络每训练1000步,就用训练出的策略和当前最好的策略 \(f_{\theta_*}\) 进行400局对战,若胜率大于55%,则选其为当前最佳网络 \(f_{\theta_*}\)
蒙特卡洛搜索树
在此算法中,每个树枝 \((s, a)\) 都存储了一系列值:\[{P(s, a), N(s, a), W(s, a), Q(s, a)}\]
其中 \(P(s, a)\) 是先验概率,\(W(s, a)\) 是总的动作值,\(Q(s, a)\) 是平均动作值,\(N(s, a)\) 是访问次数。
蒙特卡洛搜索树总共分成三步执行:
- 选择。从根节点开始基于UCB1算法进行动作选择,直到到达叶结点。
\[ a_t = \arg\max (Q(s_t, a) + u(s_t, a)) \\ u(s, a) \varpropto \frac{P(s, a)}{1+N(s, a)} \]
一开始算法会倾向于高先验概率低访问次数的动作,但之后算法会倾向于选择动作值较大的动作。
扩展与评估。神经网络在当前叶结点 \(s_L\) 输出 \(P(s, a)\) 动作概率向量以及 \(v\) 值函数。
更新。
\[ W(s_t, a_t) = W(s_t, a_t) + v \\ N(s_t, a_t) = N(s_t, a_t) + 1 \\ Q(s_t, a_t) = \frac{W(s_t, a_t)}{N(s_t, a_t)} \]
搜索完成后,算法会按照访问次数生成动作概率
\[\pi(a|s_0) = \frac{N(s_0, a)^{1/\tau}}{\sum_b N(s_0, b)^{1/\tau}}\]
训练
神经网络输入的数据为 \(19*19*17\) 的三维数据,棋盘的每个位置由一个17维的二元向量表示,其中前8个特征表示在当前和之前7个棋面中,当前玩家的棋子是否在棋盘的某个位置上,后8个特征表示对手的相应局面,最后一个特征表示当前哪个颜色走子。
AlphaGo Zero 自我对局了超过490万局,耗时3天。棋局的每一步都是通过 MCTS 经过1600次循环所选出,耗时0.4秒。最终以100比0击败了当初和李世石对战的 AlphaGo。之后 AlphaGo Zero 采用更大的神经网络,又重新自我对局了超过2900万局,耗时40天,最终以89比11击败了当初以60比0击败众多人类高手的 AlphaGo Master。
现实意义
打破数据壁垒,无需标注数据,完全依靠自我生成数据并进行标注,放入神经网络进行训练输出策略和值函数。
AlphaGo 非常依赖自我对局以求生成数据,一是因为现有原始数据量太小无法有效地训练网络,为了样本的独立性浪费了大量棋局;二是因为左右互搏需要大量试错,一开始都是在随机走子。然而在现实世界中很难有自我对局的机会,比如金融市场就不存在对手,数据量明显不足。
围棋是一种特殊的情景,它是完美信息博弈,所有信息都在棋局上,而且棋局当前的局面是马尔科夫的,然而现实世界中大多情景是不完美博弈,环境中有大量信息不可知,比如星际争霸里的战争迷雾,状态也很难是马尔科夫的。围棋是可模拟的,我们完全可以下无数局棋,但现实中很多情景不可模拟,比如金融市场,或者搭建模拟器成本很高。围棋的状态动作空间都很小,而且是离散的,奖励是很显然的,然而在星际争霸中状态动作空间就相当的大。