上一节说的顺序表是分配实际物理内存连续的存储区域用来存取的,而链式表是逻辑上连续的表,它们之间通过一个next指针指向下一个结点,即一个节点保存了下一个节点的地址
先看她的结构定义

基础讲解:一个新的数据类型List型,它的成员类型有两个,一个记录链表长度的len,一个指向链表头结点的头指针;新类型Node型,它成员也有两个。
那么 List mylist;就会定义一个名为mylist的List型变量。若我们在定义List mylist2,他们内部都有len 和phead两个成员。
实际上,这里是定义一个stuct List型,然后用typedef将该类型另行别名,但和#define是不一样的。
链式栈ADT:

初始化:

新生成一个结点作为头结点,它不存数据,先将它的next置为NULL表示空表状态,然后表长len为0表示没有结点
而需要头结点的原因,是为了让后续的结点操作统一,若直接让头指针指向有效结点,那么第一个结点的位置要作为特例操作,具体请看插入函数讲解
先来个简单的,尾追加结点函数

【习惯】:最好将自己的代码,用空行分隔成不同的部分,如上:8 9 10是变量定义初始化以及新分配结点相关;12 13是对新节点的操作,15-20是将新结点与原表相结合相关
思路: 1,先声明一个指针指向一个新生成的结点(注意,先检查分配是否成功,虽然不成功的几率很小,但这是一个好的编程习惯)
2,通过该指针访问这块结点,先存入结点数据域值,然后将其next置NULL(因为它是尾节点)
3,我们后面的函数都会用到这个find指针,通过它的名字,我把他的作用定义为:让它指向我想找的那个结点。我们让find指向尾结点,因为while是循环到find->next = NULL那个结点。现在我们可以通过find访问尾结点了
4,将新结点“挂”到尾结点后面,然后len长加1.
【方法】:这里我讲解一个我个人理解的一个关键点,事实上。正是有了这个思想后,我才开始觉悟数据结构,各种各样的操作,以及为什么有些语句顺序不能随便写等等。极大的激发了我的学习兴趣,让我之后的学习效率可以这么说:基本看一遍书就能懂,然后自己不看书,直接可以自己敲代码实现了。是什么呢?
不知道你有没有听过左值和右值的概念。它很容易分辨但是不容易理解。比如 (假设a,b均适当定义声明了)a = b,这里把b赋给a。a 就是左值,b就是右值。照我自己的理解:左值是一个地址相关,右值就是一个简单值,这里,是把b的值赋给a变量所在地址内覆盖内容(理解不准确不严谨,请见谅,我只是菜鸟一枚)。但是在数构里面,我把左值当做小概念的点,而右值当做大的“一个结点”。现在来理解一下插入函数的那关键的两步操作
插入函数:
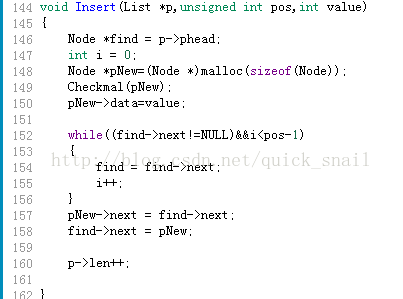
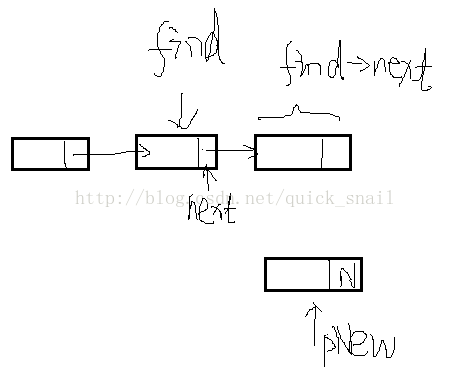
前面几步是pNew相关操作,这里pos是第pos个结点,意思是将新节点插入第pos个前面,这里我们假设要插到第三个节点前面,我假设叫它操作对象,find指针是索引寻找作用,不论是插入,删除操作,要对那个结点操作,就叫它操作对象,find都指向它前一个
关键理解:pNew->next = find->next;find->next = pNew两步,第一句,右边的find->next,照我之前的理解,它指的是第三个结点整个结点,而左边pNew->next指小的点,它指的是pNew这个结点的next点,所以,是将第三个结点(操作对象)“挂”到pNew结点的next点,第二句,同理,是将pNew这个结点挂到find所指的节点的next点,显然,这两句中的find->next不是同一个对象。至于为什么 不能反过来,因为若先直接将pNew挂到到find的next下,那么我们就不能再通过find->next找到操作对象这个结点了。
同样若是删除这个结点,先用q=find->next(操作对象结点)暂存要删除的结点地址(以用来free释放,这样不会早场内存泄漏),然后再将find->next->next这个结点(就是操作对象结点的后一个结点)挂到find的next点即find->next = find->next->next(也可以用q->next)