Java虚拟机内存分布
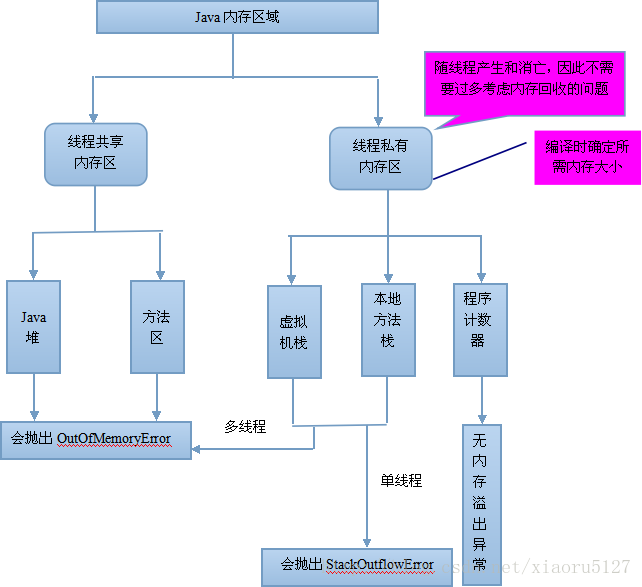
- 虚拟机栈:Java方法的内存模型,即每个方法的执行都会创建一个虚拟机栈帧,方法的执行过程就是栈帧的入栈出栈,每个栈帧用于存储局部变量表、操作数栈、动态链接、方法返回地址和一些额外的附加信息(运行期会有JIT优化,但我们理论上认为这部分所需内存编译期可知);线程独立;StackOverflowError和OutOfMemoryError
- 局部变量表:存储编译期可知的基本数据类型、对象引用reference、返回值类型returnAddress(它指向了一条字节码指令的地址);局部变量表的空间在java编译成class文件时就已经确定其最大容量,运行期间不会改变;局部变量表是可以复用的,当指令执行超过某变量的作用范围则该指令占有的slot可以被重用
- 操作数栈:方法开始时为空,执行过程中将各种操作入栈出栈(即执行)。编译成class时确定栈大小,java虚拟机是基于操作数栈的,执行速度相对慢,但可移植性强;Android虚拟机是基于寄存器的,执行速度快,移植性差
- 方法返回地址:正常时,调用者的PC计数器的值作为返回地址;异常退出则由异常处理器决定
- 本地方法栈:native方法的内存模型,与虚拟机栈雷同。
- Java堆:存放对象实例和数组;线程共享;OutOfMemoryError
- 方法区:存储虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等,线程共享;这个内存区可不实现垃圾回收,若实现主要回收废弃的常量(如方法区中有“abc”常量,当前系统无String对象引用“abc”即可回收)和无用类(满足下列条件:1.堆中不存在实例2.加载该类的ClassLoader被回收3.类对应的Class对象没有引用,无法通过反射加载);OutOfMemoryError
- 运行时常量池:方法区的一部分,用于存放编译期生成的各种字面量和符号引用;
- 程序计数器:当前线程(线程独立)所执行的字节码的行号指示器。即正在执行的虚拟机字节码指令的地址。此外执行Java代码时指向字节码地址,执行Native方法则为空,不会OOM
- 直接内存:非虚拟机规范内容,受本机总内存的大小及处理器寻址空间限制;OutOfMemoryError
对象创建过程
Person person = new Person();我们看下一个对象的大致创建过程:
- 在方法区常量池中查看是否有Person类的符号引用,若无,加载、解析、初始化Person类
- 在Java堆中分配所需内存(加载Person类后其所需内存大小便以可知)
2.1内存分配方法:1.内存规整,移动指针至空间足够的区域进行内存分配2.内存不规整,这时候会有一个空闲内存表来记录内存使用情况,在表中寻找足够大的内存空间进行分配。何种分配方法取决于使用何种垃圾回收机制(即看所选择的垃圾回收机制是否具有压缩整理功能)
2.2保证原子性:对象分配是非常频繁的,Java堆又是线程共享的,多线程情况下会有线程安全问题。解决方法有两种:1.同步处理2.堆中分配一块本地线程分配缓冲,每个线程在自己的缓冲区分配后再移动到堆内存中,移动过程也需要同步处理 - 初始化内存空间(内存置0,类变量如果没有赋值则会有一个默认初始值就是因为这一步)
- 初始化头信息(类原数据指针 + 哈希码 + GC分代年龄 + 锁状态 …)
- 对象初始化
对象的内存分布(Java堆)
上面说到对象的创建,创建完成后对象在Java堆中的内存分布如下:
1. 对象头
1.1: 存储对象自身运行时数据,如哈希码、GC分代年龄、锁状态…
1.2: 类型指针,不一定有(因为还有其他方法可以确认),指向方法区中的类信息,用以确认该对象是哪个类的实例
2.实例数据:自身定义的数据和父类继承下来的数据,默认会以类型为顺序一一分配。
3.对齐填充:不是必然存在(刚好填充满了就不需要了),无特殊含义,起占位符作用
对象的访问定位(两种方式)
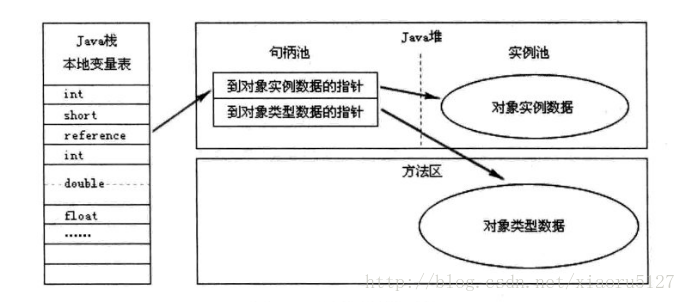
Java栈-本地变量表 存 Java堆-句柄池(对象实例数据指针+对象类型数据指针),句柄池指针指向堆实例地址和方法区类信息地址(稳定,堆实例经常移动只需改变句柄池地址 变量表无需更改)
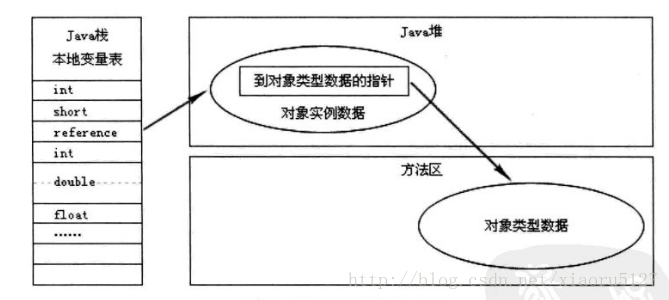
Java栈-本地变量表 存 Java堆-实例地址,Java堆-实例地址 存 方法区类信息地址(减少一次指针定位的时间和内存)
垃圾回收机制
虚拟机栈、本地方法栈、程序计数器中的数据随线程的生命而创建回收,随方法的入栈出栈而创建回收,无需垃圾回收机制。垃圾回收机制的重点在Java堆和方法区
对象是否已经无用判断?
1.引用计数法:每个对象有一个引用计数器来记录当前引用数,为0则可回收。缺陷:很难解决对象之间互相循环引用的问题
2.可达性分析法:GC Roots枚举根节点(一个集合)没有引用链相连的对象就是不可用对象。GC Roots的集合对象包括:①虚拟机栈(栈帧中本地变量表)中引用的对象②方法区中类静态属性引用的对象③方法区中常量引用的对象④本地方法栈中JNI引用的对象
对象的回收
GC Roots不可达则标记对象;判断是否执行finalize()方法(对象没有覆盖finalize方法或finalize已经被虚拟机调用过则不执行),若需要执行,则执行后再次判断对象是否GC Roots可达,还是不可达则回收(可在finalize中与GC Roots对象关联)
GC Roots枚举根节点集合的维护
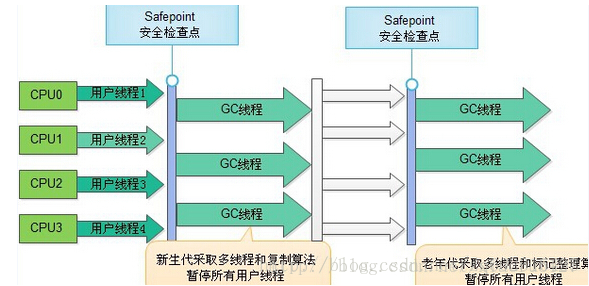
代码执行过程中有符合条件的对象都需要加入到GC Roots集合中,且获取时需要暂停整个系统,否则分析结果无法得到保障。通常,代码执行到安全点才会停下来维护GC Roots枚举(主动式中断:GC设置一个标志,各线程执行时执行到安全点会去轮询,主动挂起,维护GC Roots枚举)
垃圾回收算法
- 标记清除算法:产生大量碎片
- 标记整理算法:耗时,有连续空间
- 复制算法:浪费内存空间
- 分代收集算法:年轻代(空间较小,垃圾收集频繁而快速)、老年代(空间较大,垃圾收集较少,一般采用标记整理法,较为耗时)
JDK1.7中垃圾回收器
- Serial (串行)收集器
- ParNew
与Serial类似,只不过新生代GC线程是多线程而已 - Parallel
与Serial类似,只不过新生代GC线程和老年代GC线程都是多线程而已
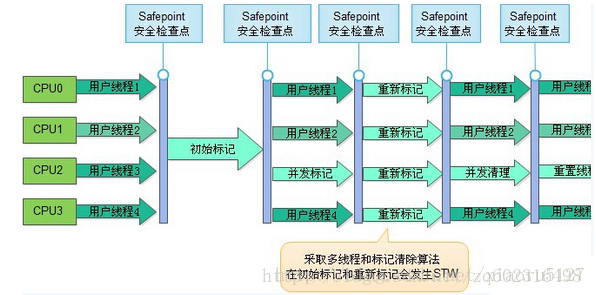
- CMS (优点:并发收集、低停顿 缺点:对CPU资源非常敏感,无法处理浮动垃圾,产生大量碎片)
①初始标记(CMS initial mark) 标记GC Roots能直接关联到的对象;阻塞,耗时短
②并发标记(CMS concurrenr mark) 标记回收对象;并发
③重新标记(CMS remark) 标记因用户运行产生的可回收对象;阻塞
④并发清除(CMS concurrent sweep) 清理;并发
- G1
①初始标记(Initial Marking)
②并发标记(Concurrent Marking)
③最终标记(Final Marking)
④筛选回收(Live Data Counting and Evacuation)
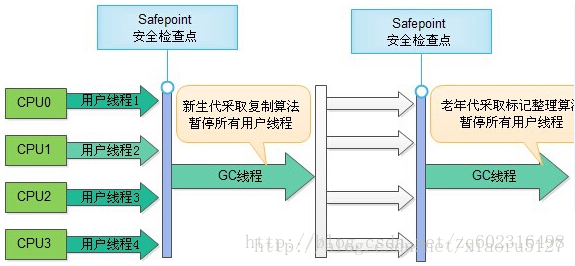

杂
- -Xmx –Xms:指定最大堆和最小堆
- -Xmn 设置新生代大小
- -XX:NewRatio 新生代(eden+2*s)和老年代(不包含永久区)的比值。例如:4,表示新生代:老年代=1:4,即新生代占整个堆的1/5
- -XX:SurvivorRatio 设置两个Survivor区和eden的比值。例如:8,表示两个Survivor:eden=2:8,即一个Survivor占年轻代的1/10
- -XX:+HeapDumpOnOutOfMemoryError OOM时导出堆到文件,根据这个文件,我们可以看到系统dump时发生了什么
- -XX:+HeapDumpPath 导出OOM的路径
- -XX:OnOutOfMemoryError 在OOM时,执行一个脚本。 可以在OOM时,发送邮件,甚至是重启程序
- -XX:PermSize -XX:MaxPermSize 设置方法区的初始空间和最大空间
- -Xss 设置栈空间的大小
成员变量存在于堆内存中,局部变量存在于栈内存中,静态变量存在于方法区中
Dalvik JVM 和 Art的区别
- Dalvik是基于寄存器的,而JVM是基于栈的。Dalvik运行dex文件,而JVM运行java字节码
- Dalvik:应用每次运行的时候,字节码都需要通过即时编译器(just in time ,JIT)转换为机器码,拖慢应用。Art:应用在第一次安装的时候,字节码就会预先编译成机器码,启动和运行会加快,安装变慢