以下面经总结自很多同学、同事高工的面试经历。
1、问到了redis 原子性
2、ArrayList内部实现,以及对于原生数组的优势(扩容,线程安全等)
3、多线程,分布式锁,分布式事务
ps:
问:如果保证3个线程都结束之后再继续执行业务?
答:我说用线程的栅栏;或者3个flag,while去判断。
问:多个线程同时访问数据库,如何保证多个线程同时成功,同时失败;如何保证同时操作数据库的时候,不发生写的覆盖?
答:若在主线程加事务,则线程结束后一起提交,性能上不是最优选项;可以在事后处理,通过日志发现哪些写操作有问题,然后补偿到数据库(部分场景适用);可以在数据库级别加锁(引出mysql隔离级别),默认写锁;redis的原子性也可以考虑是否可以解决类似问题。
4、redis
4、线程池的实现

5、mysql隔离级别
6、jvm相关
https://blog.csdn.net/stanlee_0/article/details/51171382
https://blog.csdn.net/luomingkui1109/article/details/72820232
java8的JVM有变化,持久代(PSPermGen)被元空间(Metaspace)取代
https://blog.csdn.net/yechaodechuntian/article/details/40341975
这篇博文提到了GC()算法,略有晦涩
https://blog.csdn.net/hui_yan2012/article/details/70194449
一系列JVM博客,包括GC()算法,这个讲的比较清爽
http://www.importnew.com/23752.html
运行时常量池是方法区的一部分(1.8之前)
----
静态常量是存放在方法区的
7、map内部实现(扩容,线程安全等)
8、String内存问题,Long内存问题等
9、== 和 equal 的区别
10、shell命令
11、zookeeper
维护配置信息
命名
分布式同步
提供组服务
---- https://www.cnblogs.com/raphael5200/p/5285583.html
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。
为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(
proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的
统治时期。低32位用于递增计数。
» 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
» 数据更新原子性,一次数据更新要么成功,要么失败
» 全局唯一数据视图,client无论连接到哪个server,数据视图都是一致的
» 实时性,在一定事件范围内,client能读到最新数据
ZooKeeper状态的每一次改变, 都对应着一个递增的Transaction id, 该id称为zxid. 由于zxid的递增性质, 如果zxid1小于zxid2, 那么zxid1肯定先于zxid2发生.
Server数目一般为奇数(3、5、7)如果有3个Server,则最多允许1个Server挂掉;如果有4个Server,则同样最多允许1个Server挂掉由此,
我们看出3台服务器和4台服务器的的容灾能力是一样的,所以为了节省服务器资源,一般我们采用奇数个数,作为服务器部署个数。
eureka和zookeeper
1、在Eureka平台中,如果某台服务器宕机,Eureka不会有类似于ZooKeeper的选举leader的过程;客户端请求会自动切换到新的Eureka节点;当宕机的服务器重新恢复后,Eureka会再次将其纳入到服务器集群管理之中;而对于它来说,所有要做的无非是同步一些新的服务注册信息而已。所以,再也不用担心有“掉队”的服务器恢复以后,会从Eureka服务器集群中剔除出去的风险了。Eureka甚至被设计用来应付范围更广的网络分割故障,并实现“0”宕机维护需求。(多个zookeeper之间网络出现问题,造成出现多个leader,发生脑裂)当网络分割故障发生时,每个Eureka节点,会持续的对外提供服务(注:ZooKeeper不会):接收新的服务注册同时将它们提供给下游的服务发现请求。这样一来,就可以实现在同一个子网中(same side of partition),新发布的服务仍然可以被发现与访问。
2、正常配置下,Eureka内置了心跳服务,用于淘汰一些“濒死”的服务器;如果在Eureka中注册的服务,它的“心跳”变得迟缓时,Eureka会将其整个剔除出管理范围(这点有点像ZooKeeper的做法)。这是个很好的功能,但是当网络分割故障发生时,这也是非常危险的;因为,那些因为网络问题(注:心跳慢被剔除了)而被剔除出去的服务器本身是很”健康“的,只是因为网络分割故障把Eureka集群分割成了独立的子网而不能互访而已。
幸运的是,Netflix考虑到了这个缺陷。如果Eureka服务节点在短时间里丢失了大量的心跳连接(注:可能发生了网络故障),那么这个Eureka节点会进入”自我保护模式“,同时保留那些“心跳死亡“的服务注册信息不过期。此时,这个Eureka节点对于新的服务还能提供注册服务,对于”死亡“的仍然保留,以防还有客户端向其发起请求。当网络故障恢复后,这个Eureka节点会退出”自我保护模式“。所以Eureka的哲学是,同时保留”好数据“与”坏数据“总比丢掉任何”好数据“要更好,所以这种模式在实践中非常有效。
3、Eureka还有客户端缓存功能(注:Eureka分为客户端程序与服务器端程序两个部分,客户端程序负责向外提供注册与发现服务接口)。所以即便Eureka集群中所有节点都失效,或者发生网络分割故障导致客户端不能访问任何一台Eureka服务器;Eureka服务的消费者仍然可以通过Eureka客户端缓存来获取现有的服务注册信息。甚至最极端的环境下,所有正常的Eureka节点都不对请求产生相应,也没有更好的服务器解决方案来解决这种问题
时;得益于Eureka的客户端缓存技术,消费者服务仍然可以通过Eureka客户端查询与获取注册服务信息,这点很重要。
在分布式系统领域有个著名的CAP定理(C-数据一致性;A-服务可用性;P-服务对网络分区故障的容错性,这三个特性在任何分布式系统中不能同时满足,最多同时满足两个);ZooKeeper是个CP的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。但是别忘了,ZooKeeper是分布式协调服务,它的职责是保证数据(注:配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致;所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了,如果是AP的,那么将会带来恐怖的后果(注:ZooKeeper就像交叉路口的信号灯一样,你能想象在交通要道突然信号灯失灵的情况吗?)。而且,作为ZooKeeper的核心实现算法Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。
1、对于Service发现服务来说就算是返回了包含不实的信息的结果也比什么都不返回要好;再者,对于Service发现服务而言,宁可返回某服务5分钟之前在哪几个服务器上可用的信息,也不能因为暂时的网络故障而找不到可用的服务器,而不返回任何结果。所以说,用ZooKeeper来做Service发现服务是肯定错误的,如果你这么用就惨了!
如果被用作Service发现服务,ZooKeeper本身并没有正确的处理网络分割的问题;而在云端,网络分割问题跟其他类型的故障一样的确会发生;所以最好提前对这个问题做好100%的准备。就像Jepsen在ZooKeeper网站上发布的博客中所说:在ZooKeeper中,如果在同一个网络分区(partition)的节点数(nodes)数达不到ZooKeeper选取Leader节点的“法定人数”时,它们就会从ZooKeeper中断开,当然同时也就不能提供Service发现服务了。
2、ZooKeeper下所有节点不可能保证任何时候都能缓存所有的服务注册信息。如果ZooKeeper下所有节点都断开了,或者集群中出现了网络分割的故障(注:由于交换机故障导致交换机底下的子网间不能互访);那么ZooKeeper会将它们都从自己管理范围中剔除出去,外界就不能访问到这些节点了,即便这些节点本身是“健康”的,可以正常提供服务的;所以导致到达这些节点的服务请求被丢失了。(注:这也是为什么ZooKeeper不满足CAP中A的原因)
ZAB(ZooKeeper Atomic Broadcast ) 全称为:原子消息广播协议
----
----https://blog.csdn.net/coorz/article/details/70921252
Eureka是基于AP原则构建的,而ZooKeeper是基于CP原则构建的。这些可以从他们的特性中得到体现。
Eureka因为没有选举过程来选举Leader,因此写的信息可以独立进行。因此有可能出现数据信息不一致的情况。但是当网络出现问题的时候,每台服务器也可以完成独立的服务。当然了,一些客户端的负载平衡和Fail Over机制需要来辅助完成额外的功能。相较之下,ZK因为基于CP原则,能保证很好的数据一致性,但是可用性支持力度不高。而在一个内部系统中,主要是服务的注册与发现,而不是配置(文件)共享,因此Eureka更适用于内部服务的建设。
---
https://blog.csdn.net/xlgen157387/article/details/77773908
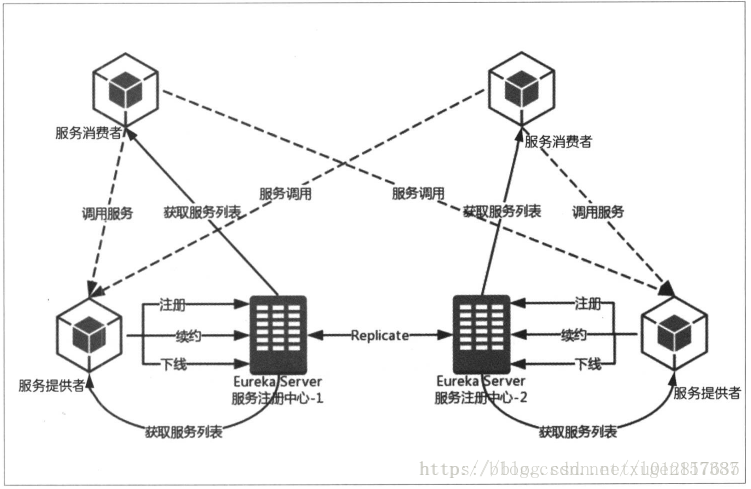
上图中描述了(图片来源于网络):
1、两台Eureka服务注册中心构成的服务注册中心的主从复制集群;
2、然后服务提供者向注册中心进行注册、续约、下线服务等;
3、服务消费者向Eureka注册中心拉去服务列表并维护在本地(这也是客户端发现模式的机制体现!);
4、然后服务消费者根据从Eureka服务注册中心获取的服务列表选取一个服务提供者进行消费服务。
(2)Spring Cloud Ribbon
在上Spring Cloud Eureka描述了服务如何进行注册,注册到哪里,服务消费者如何获取服务生产者的服务信息,但是Eureka只是维护了服务生产者、注册中心、服务消费者三者之间的关系,真正的服务消费者调用服务生产者提供的数据是通过Spring Cloud Ribbon来实现的。
在(1)中提到了服务消费者是将服务从注册中心获取服务生产者的服务列表并维护在本地的,这种客户端发现模式的方式是服务消费者选择合适的节点进行访问服务生产者提供的数据,这种选择合适节点的过程就是Spring Cloud Ribbon完成的。
Spring Cloud Ribbon客户端负载均衡器由此而来。
(3)Spring Cloud Feign
上述(1)、(2)中我们已经使用最简单的方式实现了服务的注册发现和服务的调用操作,如果具体的使用Ribbon调用服务的话,你就可以感受到使用Ribbon的方式还是有一些复杂,因此Spring Cloud Feign应运而生。
Spring Cloud Feign 是一个声明web服务客户端,这使得编写Web服务客户端更容易,使用Feign 创建一个接口并对它进行注解,它具有可插拔的注解支持包括Feign注解与JAX-RS注解,Feign还支持可插拔的编码器与解码器,Spring Cloud 增加了对 Spring MVC的注解,Spring Web 默认使用了HttpMessageConverters, Spring Cloud 集成 Ribbon 和 Eureka 提供的负载均衡的HTTP客户端 Feign。
简单的可以理解为:Spring Cloud Feign 的出现使得Eureka和Ribbon的使用更为简单。
(4)Spring Cloud Hystrix
我们在(1)、(2)、(3)中知道了使用Eureka进行服务的注册和发现,使用Ribbon实现服务的负载均衡调用,还知道了使用Feign可以简化我们的编码。但是,这些还不足以实现一个高可用的微服务架构。
例如:当有一个服务出现了故障,而服务的调用方不知道服务出现故障,若此时调用放的请求不断的增加,最后就会等待出现故障的依赖方 相应形成任务的积压,最终导致自身服务的瘫痪。
Spring Cloud Hystrix正是为了解决这种情况的,防止对某一故障服务持续进行访问。Hystrix的含义是:断路器,断路器本身是一种开关装置,用于我们家庭的电路保护,防止电流的过载,当线路中有电器发生短路的时候,断路器能够及时切换故障的电器,防止发生过载、发热甚至起火等严重后果。
(5)Spring Cloud Config
对于微服务还不是很多的时候,各种服务的配置管理起来还相对简单,但是当成百上千的微服务节点起来的时候,服务配置的管理变得会复杂起来。
分布式系统中,由于服务数量巨多,为了方便服务配置文件统一管理,实时更新,所以需要分布式配置中心组件。在Spring Cloud中,有分布式配置中心组件Spring Cloud Config ,它支持配置服务放在配置服务的内存中(即本地),也支持放在远程Git仓库中。在Cpring Cloud Config 组件中,分两个角色,一是Config Server,二是Config Client。
Config Server用于配置属性的存储,存储的位置可以为Git仓库、SVN仓库、本地文件等,Config Client用于服务属性的读取。
-----------凌总
Redis的高可用
分布式事物
分布式锁
集群和cluster的区别(集群和分布式的区别)
Redis+Twemproxy
Redis的数据结构
缓存的问题,缓存击穿、缓存雪崩怎么解决
--
服务治理 服务容错
服务高可用
服务降级
监控中心
k8s
---
跳跃表
---
redis 高可用
https://segmentfault.com/a/1190000008931971
什么是Redis的原子性?
什么叫做原子操作?
在 Redis 中什么样的操作算是原子操作?
Redis的原子性有两点:
单个操作是原子性的
多个操作也支持事务,即原子性,通过
MULTI和EXEC指令包起来
原子操作的意思就是要么成功执行要么失败完全不执行。用现实中的转账比喻最形象,你转账要么成功,要么失败钱不动,不存在你钱转出去了,但收款方没收到这种成功一半失败一半的情况
在事务运行期间,虽然Redis命令可能会执行失败,但是Redis仍然会执行事务中余下的其他命令,而不会执行回滚操作
-----------
最终一致性
https://www.zhihu.com/question/36413559
--
分布式事务
https://blog.csdn.net/congyihao/article/details/70195154
1、两阶段提交(2PC)
2、TCC基于补偿型事务的AP系统的一种实现, 具有最终一致性
3、异步确保型
通过将一系列同步的事务操作变为基于消息执行的异步操作, 避免了分布式事务中的同步阻塞操作的影响.
这个方案真正实现了两个服务的解耦, 解耦的关键就是异步消息和补偿性事务.
执行步骤如下:
- MQ发送方发送远程事务消息到MQ Server;
- MQ Server给予响应, 表明事务消息已成功到达MQ Server.
- MQ发送方Commit本地事务.
- 若本地事务Commit成功, 则通知MQ Server允许对应事务消息被消费; 若本地事务失败, 则通知MQ Server对应事务消息应被丢弃.
- 若MQ发送方超时未对MQ Server作出本地事务执行状态的反馈, 那么需要MQ Servfer向MQ发送方主动回查事务状态, 以决定事务消息是否能被消费.
- 当得知本地事务执行成功时, MQ Server允许MQ订阅方消费本条事务消息.
---
数据库隔离级别
https://blog.csdn.net/gaopu12345/article/details/50868501
---
CAP理论和BASE理论
https://blog.csdn.net/miyatang/article/details/54342104
---
volatile:volatile的本意是“易变的”。volatile关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等。遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。当要求使用volatile 声明的变量的值的时候,系统总是重新从它所在的内存读取数据,即使它前面的指令刚刚从该处读取过数据。而且读取的数据立刻被保存。volatile 指出 i是随时可能发生变化的,每次使用它的时候必须从i的地址中读取。对于volatile类型的变量,系统每次用到他的时候都是直接从对应的内存当中提取,而不会利用cache当中的原有数值,以适应它的未知何时会发生的变化。
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。
为什么String, Interger这样的wrapper类适合作为键? String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不可变性还有其他的优点如线程安全。如果你可以仅仅通过将某个field声明成final就能保证hashCode是不变的,那么请这么做吧。因为获取对象的时候要用到equals()和hashCode()方法,那么键对象正确的重写这两个方法是非常重要的。如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这样就能提高HashMap的性能。
----
https://blog.csdn.net/login_sonata/article/details/76598675
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图
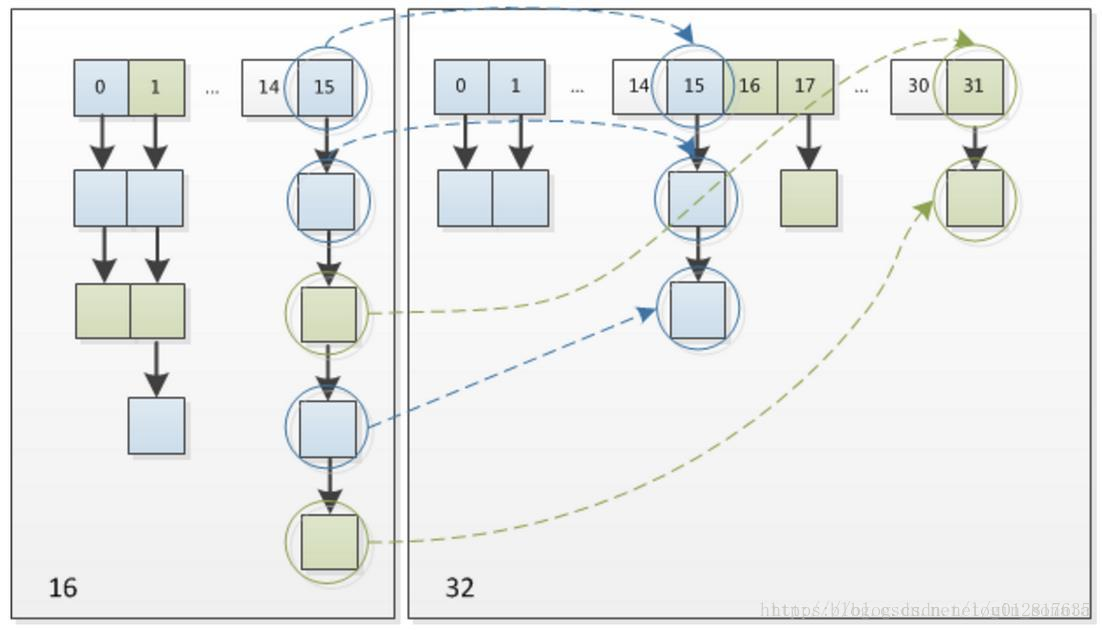
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。有兴趣的同学可以研究下JDK1.8的resize源码,写的很赞,在本文最后可以找到。
-------------
深度遍历和广度遍历树
treeMap LinkedHashMap
https://blog.csdn.net/chenssy/article/details/26668941
https://blog.csdn.net/l_kanglin/article/details/55827154
https://blog.csdn.net/justloveyou_/article/details/71713781
https://blog.csdn.net/alanjager/article/details/53426681
目前我了解的是这样的,TreeMap支持传入Comparator根据key的自定义排序,而LinkedHashMap支持的是根据插入顺序进行排序,两者都有序,但还是有区别的
---
- ConcurrentHashMap是HashMap的线程安全版本,ConcurrentSkipListMap是TreeMap的线程安全版本
- ConcurrentHashMap设计首要目的:维护并发可读性(get、迭代相关);次要目的:使空间消耗比HashMap相同或更好,且支持多线程高效率的初始插入(empty table)。
HashTable线程安全,但采用synchronized,多线程下效率低下。线程1put时,线程2无法put或get。 - https://note.youdao.com/share/?id=dde7a10b98aee57676408bc475ab0680&type=note#/
- https://blog.csdn.net/zhang15238156629/article/details/70196340
---
锁
不可重入锁,也叫自旋锁。
可重入锁的意义在于防止死锁
synchronized会导致争用不到锁的线程进入阻塞状态,所以说它是java语言中一个重量级的同步操纵,被称为重量级锁
Synchronized是非公平锁
对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。说的有点抽象,下面会有一个代码的示例。
对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁,其名字是Re entrant Lock重新进入锁。
对于Synchronized而言,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁。
独享锁/共享锁
独享锁是指该锁一次只能被一个线程所持有。
共享锁是指该锁可被多个线程所持有。
对于Java ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。
读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
对于Synchronized而言,当然是独享锁。
互斥锁/读写锁
上面讲的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。
互斥锁在Java中的具体实现就是ReentrantLock
读写锁在Java中的具体实现就是ReadWriteLock
乐观锁/悲观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。
悲观锁认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改。因此对于同一个数据的并发操作,悲观锁采取加锁的形式。悲观的认为,不加锁的并发操作一定会出问题。
乐观锁则认为对于同一个数据的并发操作,是不会发生修改的。在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。乐观的认为,不加锁的并发操作是没有事情的。
从上面的描述我们可以看出,悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,不加锁会带来大量的性能提升。
悲观锁在Java中的使用,就是利用各种锁。
乐观锁在Java中的使用,是无锁编程,常常采用的是CAS算法,典型的例子就是原子类,通过CAS自旋实现原子操作的更新。
http://www.cnblogs.com/dolphin0520/p/3923167.html
https://www.cnblogs.com/qifengshi/p/6831055.html
---
http://www.importnew.com/20386.html
在HashMap中,哈希桶数组table的长度length大小必须为2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把桶的大小设计为素数。相对来说素数导致冲突的概率要小于合数,具体证明可以参考http://blog.csdn.net/liuqiyao_01/article/details/14475159,Hashtable初始化桶大小为11,就是桶大小设计为素数的应用(Hashtable扩容后不能保证还是素数)。HashMap采用这种非常规设计,主要是为了在取模和扩容时做优化,同时为了减少冲突,HashMap定位哈希桶索引位置时,也加入了高位参与运算的过程。
----
https://blog.csdn.net/u012403290
----
InnoDB 和 MyISAM的区别
https://blog.csdn.net/zhangliangzi/article/details/51379274
https://blog.csdn.net/lc0817/article/details/52757194
https://www.cnblogs.com/zlcxbb/p/5757245.html
mysql优化
https://blog.csdn.net/pengyufight/article/details/77523404
http://hedengcheng.com/?p=771
---
springMVC执行流程
https://www.cnblogs.com/xiaoxi/p/6164383.html
---- 深入理解AQS和锁好文
https://www.cnblogs.com/daydaynobug/p/6752837.html
-- B-Tree B+Tree
https://www.cnblogs.com/vianzhang/p/7922426.html
https://www.jianshu.com/p/486a514b0ded
https://security.yirendai.com/news/share/60
https://blog.csdn.net/endlu/article/details/51720299