摘要: 最近在研究如何使用tensorflow c++ API调用tensorflow python环境下训练得到的网络模型文件。参考了很多博客,文档,一路上踩了很多坑,现将自己的方法步骤记录下来,希望能够帮到有需要的人!(本文默认读者对python环境下tensorflow的使用已经比较熟悉了)
方法简要梳理如下:
- 安装bazel,然后使用bazel编译tensorflow源码,产生我们需要的库文件。
- 在python环境下,使用tensorflow训练一个深度神经网络,本文以mnist为例。将训练好的模型和参数冻结在一个pb文件中。
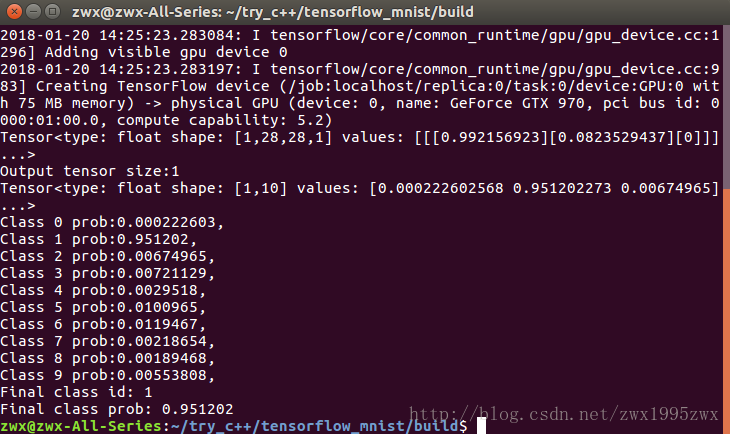
- 在C++环境下,调用pb文件,对图片进行预测。最终结果如下图所示,程序成功识别到图片中的数字为1,且概率为0.95。
具体程序参考项目:
https://github.com/zhangcliff/tensorflow-c-mnist.git
1.安装bazel
echo "deb [arch=amd64] http://storage.googleapis.com/bazel-apt stable jdk1.8" | sudo tee /etc/apt/sources.list.d/bazel.listcurl https://bazel.build/bazel-release.pub.gpg | sudo apt-key add -sudo apt-get updatesudo apt-get install bazel2.tensorflow的下载。
本博文使用的tensorflow版本为1.4,其他版本的c++编译可能会有一些不一样。
git clone https://github.com/tensorflow/tensorflow.git
3.tensorflow的c++编译。
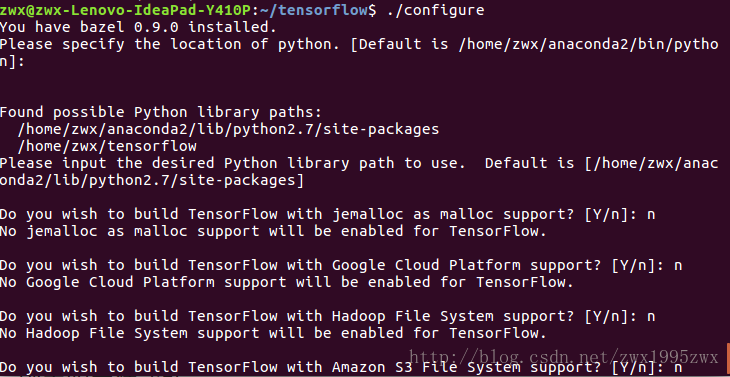
3.1 进入tensorflow文件夹中,首先进行项目配置。
./configure
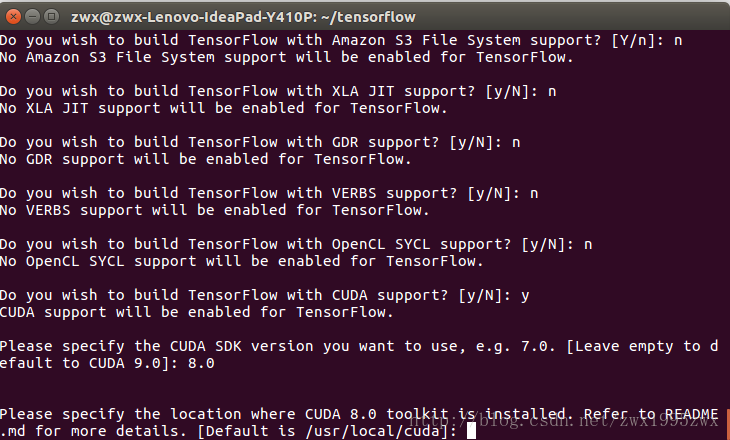
下面我贴出在我的机器上各选项的选择:值得注意的是,如果我们要使用cuda和cudnn的话,一定要搞清楚自己机器上使用的cuda和cudnn的版本(尤其是cudnn),例如我使用的是cuda8.0和cudnn6.0.21。


3.2 使用bazel命令进行编译。编译的时间比较长,我在i3-4150cpu上编译了一个小时左右的时间。
bazel build --config=opt --config=cuda //tensorflow:libtensorflow_cc.so如果没有显卡则使用如下命令进行编译
bazel build --config=opt //tensorflow:libtensorflow_cc.so编译完成后,在bazel-bin/tensorflow中会生成两个我们需要的库文件:libtensorflow_cc.so 和 libtensorflow_framework.so。
在后面我们用C++调用tensorflow时需要链接这两个库文件。
4. 使用tensorflow C++ api调用图模型(.pb文件)。
tensorflow 编译好之后,我们使用tensorflow c++ api调用一个已经冻结的图模型(.pb文件)
具体程序参考项目:
https://github.com/zhangcliff/tensorflow-c-mnist.git
4.1 在python环境下生成一个图模型(.pb文件)
对于tensorflow,在Python环境下的使用是最方便的,tensorflow的python api也是最多最全面的。因此我们在python环境下,训练了一个深度神经网络模型,并将模型和参数都冻结在一个pb文件中。为后面使用C++ API调用这个pb文件做好准备。我们以经典的mnist为例。
数据处理与模型的训练,这里就不多说了(默认读者对python环境下tensorflow的使用已经比较熟悉)。这里要说的是pb文件的生成,使用一下代码:
-
from tensorflow.python.framework.graph_util import convert_variables_to_constants
-
graph = convert_variables_to_constants(sess, sess.graph_def, [ "softmax"])
-
tf.train.write_graph(graph, 'models', 'model.pb',as_text= False)
write_graph()函数生成.pb文件,第二个参数为生成pb文件的文件夹,第三个参数为pb文件的名字。
将上面三行代码加入到你的模型训练的python脚步中,最后便可以得到我们需要的pb文件。
4.2 c++环境下调用pb文件。
第一步,加载模型
-
Session* session;
-
Status status = NewSession(SessionOptions(), &session); //创建新会话Session
-
-
-
string model_path= "model.pb";
-
GraphDef graphdef; //Graph Definition for current model
-
-
-
Status status_load = ReadBinaryProto(Env::Default(), model_path, &graphdef); //从pb文件中读取图模型;
-
if (!status_load.ok()) {
-
std:: cout << "ERROR: Loading model failed..." << model_path << std:: endl;
-
std:: cout << status_load.ToString() << "\n";
-
return -1;
-
}
-
Status status_create = session->Create(graphdef); //将模型导入会话Session中;
-
if (!status_create.ok()) {
-
std:: cout << "ERROR: Creating graph in session failed..." << status_create.ToString() << std:: endl;
-
return -1;
-
}
-
cout << "Session successfully created."<< endl;
第二步,使用tensorflow API读取图片。
这里定义了两个函数用于从jpg文件中读取图片:
-
Status ReadTensorFromImageFile(const string& file_name, const int input_height,
-
const int input_width, const float input_mean,
-
const float input_std,
-
std:: vector<Tensor>* out_tensors)
-
static Status ReadEntireFile(tensorflow::Env* env, const string& filename,
-
Tensor* output)
在ReadTensorFromImageFile()函数,建立一个会话session,在会话中对读取到的tensor进行预处理,例如,对tensor进行解码( DecodeJpeg),resize,归一化等等。
第三步,运行模型
-
const Tensor& resized_tensor = resized_tensors[ 0];
-
vector<tensorflow::Tensor> outputs;
-
string output_node = "softmax";
-
Status status_run = session->Run({{ "inputs", resized_tensor}}, {output_node}, {}, &outputs);
模型预测时使用的函数为session->Run({{"inputs", resized_tensor}}, {output_node}, {}, &outputs)。
值得注意的是,"inputs"是图模型输入tensor的名字(name),变量output_node保存的是图模型输出tensor的名字(name)。这两个名字(name)一定要与保存的图模型(.pb)文件中的名字一致,否则会报错。最后得到的输出tensor保存在容器outputs中。
如果你有一个pb文件,可是不知道它的输入输出tensor的名字,我们可以在python环境中使用API加载这个模型,然后将模型中的所有operation打印出来,第一项便是输入tensor,最后一项便是输出tensor。
-
print(sess.graph.get_operations())
-
print(sess.graph.get_operations()[ 0])
-
print(sess.graph.get_operations()[ 1])
-
Tensor t = outputs[ 0]; // Fetch the first tensor
-
auto tmap = t.tensor< float, 2>(); // Tensor Shape: [batch_size, target_class_num]
-
int output_dim = t.shape().dim_size( 1); // Get the target_class_num from 1st dimension
-
-
// Argmax: Get Final Prediction Label and Probability
-
int output_class_id = -1;
-
double output_prob = 0.0;
-
for ( int j = 0; j < output_dim; j++)
-
{
-
std:: cout << "Class " << j << " prob:" << tmap( 0, j) << "," << std:: endl;
-
if (tmap( 0, j) >= output_prob) {
-
output_class_id = j;
-
output_prob = tmap( 0, j);
-
}
-
}
-
std:: cout << "Final class id: " << output_class_id << std:: endl;
-
std:: cout << "Final class prob: " << output_prob << std:: endl;
4.3 使用cmake进行编译
本例我们建立一个cmake工程,再通过make生成一个可执行文件。首先我们建立一个文件夹取名tensorflow_mnist,在该文件夹下创建子文件夹lib,将刚才编译tensorflow 时产生的两个库文件(libtensorflow_cc.so,libtensorflow_framework.so)放入其中。调用pb文件进行预测的C++文件,取名为tf.cpp,放在tensorflow_mnist目录下。文件结构如下图所示。
下面给出我的CMakeLists.txt的文件内容
cmake_minimum_required (VERSION 2.8.8)
project (tf_example)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -std=c++11 -W")
link_directories(./lib)
include_directories(
/home/zwx/tensorflow
/home/zwx/tensorflow/bazel-genfiles
/home/zwx/tensorflow/tensorflow/contrib/makefile/downloads/nsync/public
/usr/local/include/eigen3
/home/zwx/tensorflow/bazel-bin/tensorflow
/home/zwx/tensorflow/tensorflow/contrib/makefile/gen/protobuf/include
)
add_executable(tf_test tf.cpp)
target_link_libraries(tf_test tensorflow_cc tensorflow_framework)cd build
cmake ..
make不过,在make 这一步很大几率会报错,我将我碰到的几个问题和解决方法写在这里,仅供参考。
问题一: protobuf版本不对

解决方法:安装正确版本的protobuf。在ubuntu16.04,tensorflow1.4下,应该安装protobuf-3.4.0。
问题二:nsync_cv.h文件缺失

正常情况下,该文件应该在路径tensorflow/tensorflow/contrib/makefile/downloads/nsync/public里。如果出现这个问题,很可能是tensorflow/tensorflow/contrib/makefile/下没有downloads文件夹,可能是编译的时候网络不好,没有下载这个文件夹。
解决方法: 进入 tensorflow/tensorflow/contrib/makefile/ 文件夹下,找到脚步。然后回到tensorflow文件夹下,执行该脚本。
./tensorflow/contrib/makefile/download_dependencies.sh下载完毕后,便会有downloads文件夹,缺失的文件便会包含在其中。
问题三:

解决方法:这个问题的造成原因和问题二是一样的,查看下载好的downloads文件夹,发现其中有一个文件夹为eigen,进入eigen文件夹执行以下命令。
mkdir build
cd build
cmake ..
make
sudo make install4.4 运行可执行程序
make成功后,在build目录下会出现一个可执行文件tf_test。将一张28*28的数字图片也放在build路径下,文件名为digit.jpg,最后执行tf_test文件。

./tf_test digit.jpg
从中我们可以看到该c++程序识别到digit.jpg图片为数字一,为1的概率为0.95。
总结:这篇博文主要介绍了如何从源码编译tensorflow c++ API,并且使用c++ API调用一个在python环境下已经训练好并冻结参数的模型文件(.pb文件),最终生成一个可执行文件tf_test。通过运行该文件,我们成功识别了手写体数字。
具体脚本参考项目:
https://github.com/zhangcliff/tensorflow-c-mnist.git