Mysql的各个查询语句(联合查询、连接查询、子查询等)
一、联合查询
关键字:union
语法形式
select语句1
union[union选项]
select 语句2
union[union选项]
select 语句3
union[union选项]
……
作用:
所谓的联合查询,就是将多个查询结果进行纵向上的拼接,也就是select语句2的查询结果放在select语句1查询结果的后面。依次类推!
既然是纵向上的拼接,所以联合查询有一个最最基本的语法,就是各个select语句查询出来的结果,其中字段的个数必须相同,比如,不能一个是4列,一个是3列!并且从显示的结果上看,无论“拼接”了多少个select语句,字段名只显示第一条select语句的字段名!
其中,这里的union选项跟前面学习的select选择的值是一样的,只是默认值不一样:
all:也是缺省值,保留所有的查询结果!
distinct:去重(默认值),去掉重复的查询结果!
union的应用
union的主要应用有以下的两种情形:
第一, 获得数据的条件,在同一个select语句中存在逻辑冲突,或者很难在同一个select语句中实现,这个时候,我们需要把这个业务逻辑进行拆分,也就是使用多个select语句单独的分别实现,然后再用union将各个select语句查询结果“拼接”到一起!
案例:
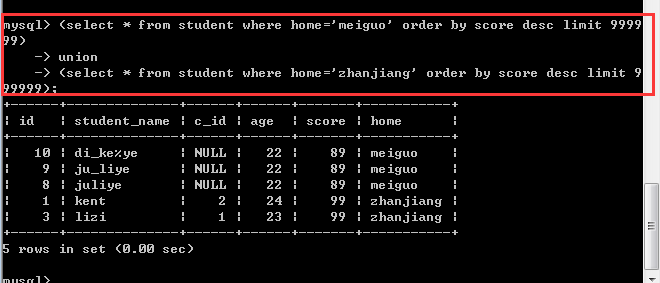
现在想查询上面student表中 meiguo 中成绩score最高的,以及zhangjiang中成绩最低的,如何实现?


这里需要有几个主意的地方:
1, 联合查询中如果要使用order by,那么就必须对这个select语句加上一对括号!
2, 联合查询中的order by必须搭配上limit关键字才能生效!因为系统默认的联合查询的结果往往比较多,所以要加以限制,当然,如果想显示全部的数据,可以在limit子句后面加上一个很大的数,比如:999999
第二, 如果一个项目的某张数据表的数据量特别大,往往会导致数据查询效率很低下,此时,我们需要对数据表进行优化处理,往往就是对该数据表进行“水平分割”,此时,这些拆分后的数据表,表结构都是一样的,只是存放的数据不一样!
比如:一个市区的手机号码机主信息,可以按不同网段放在不同的数据表中,现在,移动公司想查询平均每月消费在500元以上的客户,应该怎么查询?
回答:一个表一个表的查询,然后再通过union进行联合查询!
二、连接查询简介
概念
表与表之间是有联系的!
所谓的连接查询,就是指将两张或多张表按照某个指定的条件,进行横向上的连接并显示!
所以,从查询结果上看,字段数增加了!
比如:A表有3个字段,B表有4个字段,A表和B表进行连接查询可能有7个字段!
连接查询的操作有很多,根据连接查询的方式或性质不同,又可以将连接查询分成:
交叉连接、内连接、外连接和自然连接!
1、交叉连接
关键字:cross join
含义
就是从一张表的一条记录去连接另一张表中的所有记录,并且保存所有的记录,其中包括两个表的所有的字段!
从结果上看,就是对两张表做笛卡尔积!
笛卡尔积也就是两个表中所有可能的连接结果!如果第一张表有n1条记录,第二张表有n2条记录,那么笛卡尔积的结果有n1*n2条记录!

交叉连接一般没有太大的意义,因为有大量的无效数据!
案例:
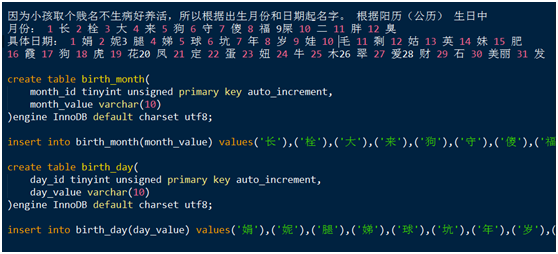
中国民间小名的取法
因为小孩取个贱名不生病好养活,所以根据出生月份和日期起名字。根据阳历(公历)生日中
月份:1 长 2 栓 3 大 4 来 5 狗 6 守 7 傻 8 福 9 屎 10 二 11 胖 12 臭
日期:1 娟 2 妮 3 腿 4 娣 5 球 6 坑 7 年 8 岁 9 娃 10 毛 11 剩 12 姑 13 英 14 妹 15 肥
16 霞 17 狗 18 虎 19 花 20 凤 21 定 22 蛋 23 妞 24 牛 25 木 26 翠 27 爱 28 财 29 石 30 美丽 31 发
2.内连接
关键字:inner join
含义
内连接需要区分左表和右表,出现在join关键字左边的就是左表,反之就是右表!
数据在左表中存在,同时在右表中又有对应的匹配的结果才会被保存!如果没有匹配上,我们就认为数据没有意义,也就不会保存!
所谓的配合,就是存在某种条件使得两个或多个表之间能够识别彼此!通常就是两张表中存在相同的某个字段!
语法规则
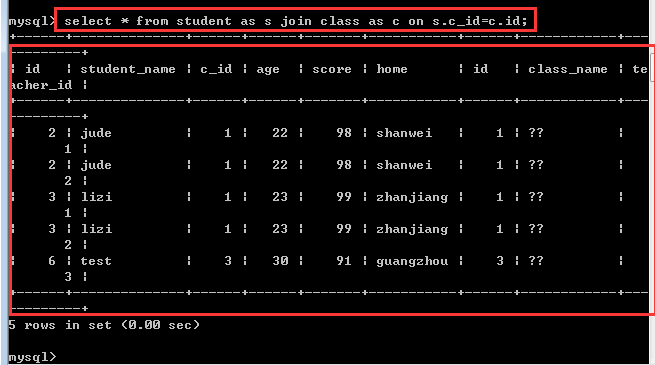
select *|字段列表 from 左表 inner join 右表 on 左表.字段 = 右表.字段;
注意:
内连接的本质还是在做交叉连接,只不过是在交叉连接的基础之上加上一定的连接条件!符合连接条件的才会被显示,不符合的就不显示!
所以,如果内连接的时候没有连接条件,此时内连接就相当于是交叉连接!
需要注意的几点:
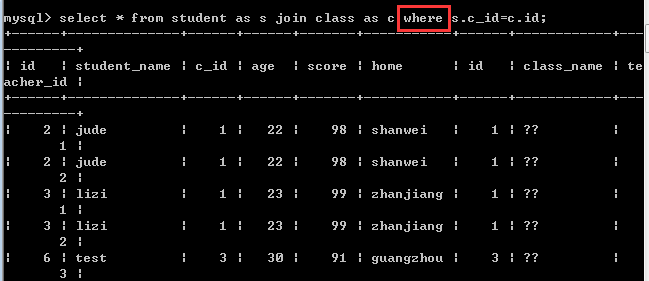
1.内连接中的inner join可以写成join,inner可以省略,默认的就是内连接!

2. 当左表和右表进行匹配的字段名相同的时候,字段名的前面必须加上表名!

如果这两个匹配的字段名不一样,表名则可以省略!
3,表名一般都很长,可以用别名来代替!

4,这里的 on是指定条件的关键字,所以也可以使用where代替,但是使用on的效率更高!
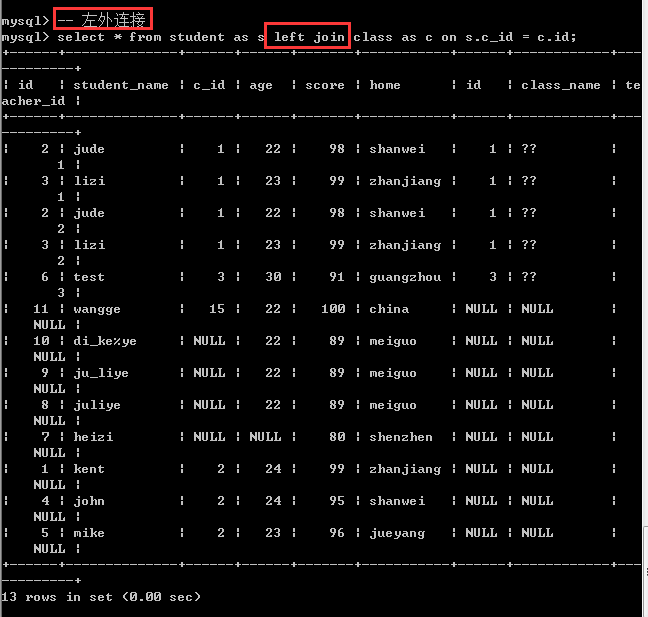
3.外连接
外连接又可以分成左外连接和右外连接!
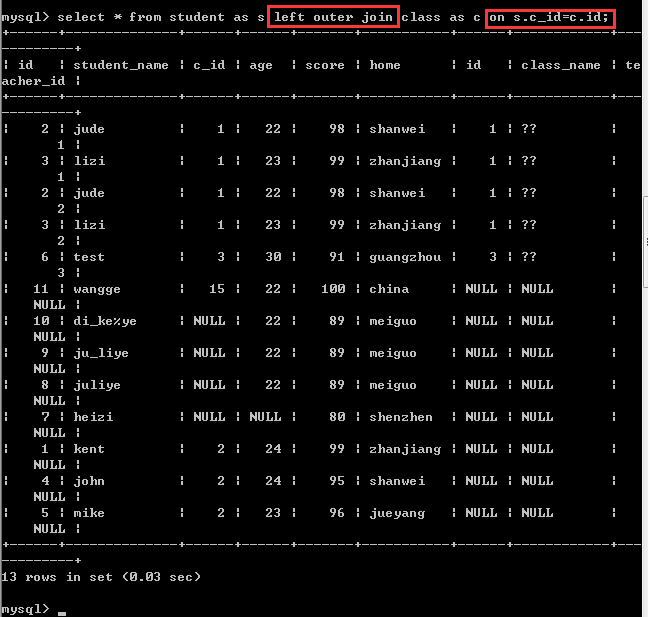
左外连接
关键字:left outer join
语法:select * from 表1 left outer join 表2 on 左表字段=右表字段
跟内连接一样,也是拿左表的每一条记录按照on后面的条件去匹配右表,如果匹配成功,那么就保留两张表的所有的记录,如果匹配失败(也就是左表的一条记录无法匹配右表的所有的记录),此时,只保留左表的记录,右表的记录全部用null代替,此时左表也叫作主表!
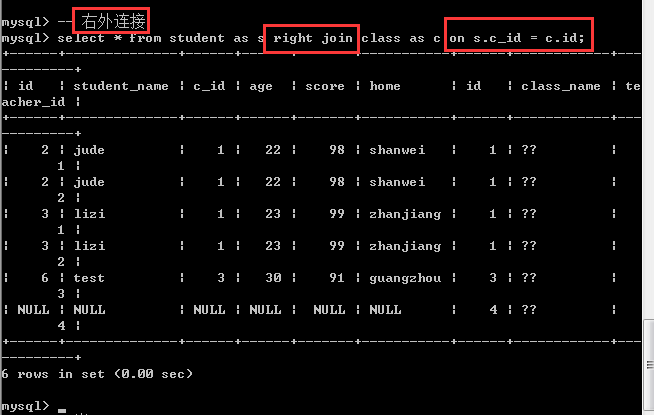
右外连接
关键字:right outer join
语法:select * from 左表 right outer join 右表 左表字段=右表字段
跟内连接一样,也是拿左表的每一条记录按照on后面的条件去匹配右表,如果匹配成功,那么就保留两张表的所有的记录,如果匹配失败(也就是右表的一条记录无法匹配左表的所有的记录),此时,只保留右表的记录,左表的记录全部用null代替,此时右表也叫作主表!

几点需要注意的地方:
1, left outer join和right outer join中的outer是可以省略的!所以左外连接也叫作左连接,右外连接也叫作右连接!
2, 这里的关键字on就不能用where来代替了!
4.自然连接
关键字:natural join
含义
所谓的自然连接,其实就是“自动连接”,指的是两个或多个表之间在进行连接查询的时候,系统会自动的去匹配连接条件,而不需要人为的指定,从形式上看,也是没有on关键字了!
自动匹配的规则如下:
只要两张表中具有相同的字段名,系统就认为是一个连接条件,就会主动的去匹配这两个相同的字段名的值是否相同,如果两个表的相同的字段名的值相同,就认为匹配成功;如果两张表中有多个字段名相同,则所有相同的字段名的值都要相同才算是匹配成功!
所以,自然连接的本质跟前面的内连接和外连接没有太大区别,只是这里的连接条件不是由用户来指定,而是由系统来指定罢了!
既然连接查询可以分成内连接和外连接,所以,自然连接也可以分成自然内连接和自然外连接!
自然内连接
语法:
左表 natural inner join右表
自然内连接其实就是内连接,只是这里的条件是由系统自动指定!
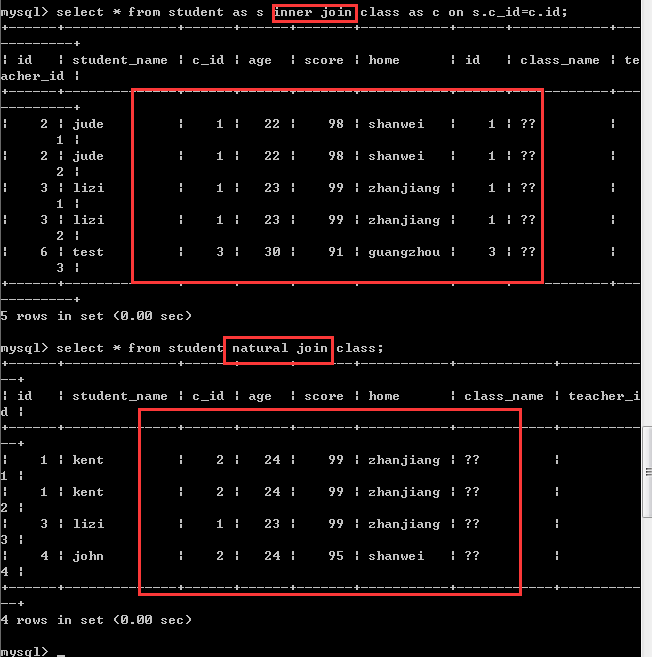
查询的记录其实是一样的,因为此时,内连接中用户指定的匹配条件跟自然内连接中由系统指定的条件刚好一样,只是自然内连接会主动的删除重复的那一列而且将重复的那一列放在最前面!
自然外连接
由于外连接分成左外连接和右外连接,所以自然外连接也可以分成自然左外连接和自然右外连接!
语法形式:
左表 natural left|right join 右表
自然外连接其实就是外连接,只是这里匹配条件也是由系统自动指定罢了!
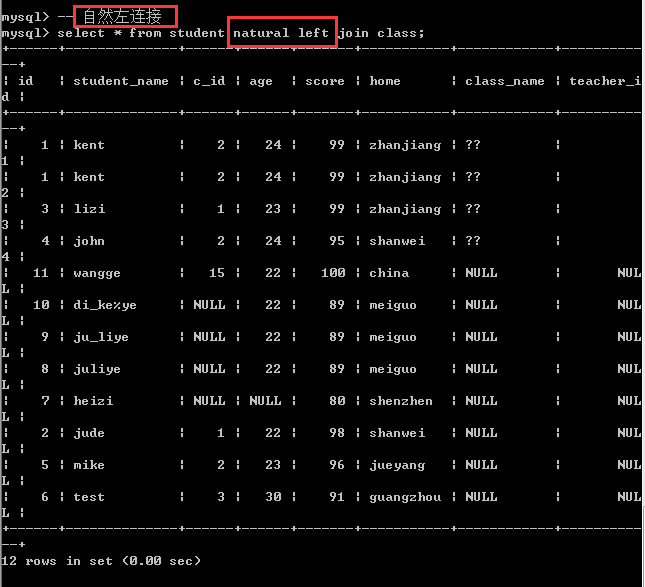
在真实的项目中,使用的最多的其实还是内连接和外连接!