原文链接:http://blog.cloudera.com/blog/2015/06/inside-apache-hbases-new-support-for-mobs/
HBase MOBs特性的设计背景
Apache HBase is a distributed, scalable, performant, consistent key value database that can store a variety of binary data types. It excels at storing many relatively small values (<10K), and providing low-latency reads and writes.
However, there is a growing demand for storing documents, images, and other moderate objects (MOBs) in HBase while maintaining low latency for reads and writes. One such use case is a bank that stores signed and scanned customer documents. As another example, transport agencies may want to store snapshots of traffic and moving cars. These MOBs are generally write-once.
Apache HBase是一个分布式、可扩展,高性能,一致的键值数据库,可以存储多种多样的二进制数据。存储小文件(小于10K)十分出色,读写延迟低。
随之而来,对文档、图片和其他中等大小文件的存储需求日益增长,并且要保持读写低延迟。一个典型的场景就是银行存储客户的签字或扫描的文档。另一个典型的场景,交通部门保存路况或过车快照。中等大小文件通常写入一次。
Unfortunately, performance can degrade in situations where many moderately sized values (100K to 10MB) are stored due to the ever-increasing I/O pressure created by compactions. Consider the case where 1TB of photos from traffic cameras, each 1MB in size, are stored into HBase daily. Parts of the stored files are compacted multiple times via minor compactions and eventually, data is rewritten by major compactions. Along with accumulation of these MOBs, I/O created by compactions will slow down the compactions, further block memstore flushing, and eventually block updates. A big MOB store will trigger frequent region splits, reducing the availability of the affected regions.
In order to address these drawbacks, Cloudera and Intel engineers have implemented MOB support in an HBase branch (hbase-11339: HBase MOB). This branch will be merged to the master in HBase 1.1 or 1.2, and is already present and supported in CDH 5.4.x, as well.
不幸的是,存储文件大小在100k到10M之间时,由于压缩导致的持续增长的读写压力,会导致性能下降。想象一下这样的场景,交通摄像头每天产生1TB的照片存到Hbase里,每个文件1MB。一部分文件被多次压缩以达到最小化。数据因为压缩被重复写入。随着中等大小文件数量的积累,压缩产生的读写会使压缩变慢,进一步阻塞memstore刷新,最终阻止更新。大量的MOB存储会触发频繁的region分割,相应region的可用性下降。
为了解决这个问题,Cloudera和Intel的工程师在Hbase的分支实现了对MOB的支持。 (hbase-11339: HBase MOB)。(译者注:这个特性并没有出现在1.1和1.2版本,而是被合入的2.0.0版本)。你可以在CDH 5.4.x中获取。
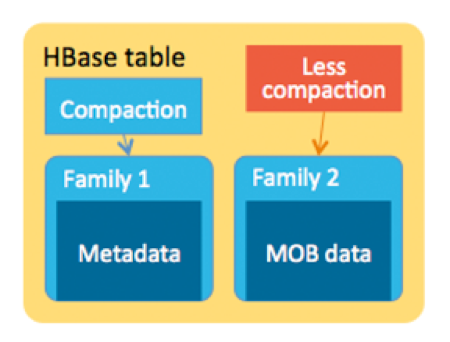
Operations on MOBs are usually write-intensive, with rare updates or deletes and relatively infrequent reads. MOBs are usually stored together with their metadata. Metadata relating to MOBs may include, for instance, car number, speed, and color. Metadata are very small relative to the MOBs. Metadata are usually accessed for analysis, while MOBs are usually randomly accessed only when they are explicitly requested with row keys.
Users want to read and write the MOBs in HBase with low latency in the same APIs, and want strong consistency, security, snapshot and HBase replication between clusters, and so on. To meet these goals, MOBs were moved out of the main I/O path of HBase and into a new I/O path.
In this post, you will learn about this design approach, and why it was selected.
对MOB的操作通常集中在写入,很少更新或删除,读取不频繁。MOB通常跟元数据一起被存储。元数据相对MOB很小,通常用来统计分析,而MOB一般通过明确的row key来获取。
用户希望在Hbase中用相同的API来读写MOB文件,并且集群之间保持低延迟,强一致、安全、快照和Hbase副本等特性。要达到这一目标,必须将MOB从 HBase主要的读写目录移到新的读写目录。
可行方案分析
There were a few possible approaches to this problem. The first approach we considered was to store MOBs in HBase with a tuned split and compaction policies—a bigger desired MaxFileSize decreases the frequency of region split, and fewer or no compactions can avoid the write amplification penalty. That approach would improve write latency and throughput considerably. However, along with the increasing number of stored files, there would be too many opened readers in a single store, even more than what is allowed by the OS. As a result, a lot of memory would be consumed and read performance would degrade.
解决这个问题有潜在的方法。第一种,优化分割(split)和压缩策略——一个更大的MaxFileSize来降低region分割频率,减少或者不压缩来避免写入恶化。这样会改善写入延迟,吞吐量好得多。但是,随着文件数量的增长,一次存储会打开非常多的reader,甚至超过操作系统的限制。结果就是内存被耗光,性能下降。
Another approach was to use an HBase + HDFS model to store the metadata and MOBs separately. In this model, a single file is linked by an entry in HBase. This is a client solution, and the transaction is controlled by the client—no HBase-side memories are consumed by MOBs. This approach would work for objects larger than 50MB, but for MOBs, many small files lead to inefficient HDFS usage since the default block size in HDFS is 128MB.
For example, let’s say a NameNode has 48GB of memory and each file is 100KB with three replicas. Each file takes more than 300 bytes in memory, so a NameNode with 48GB memory can hold about 160 million files, which would limit us to only storing 16TB MOB files in total.
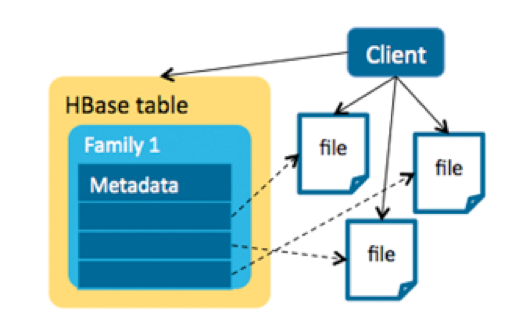
另外一种方式可以采用HBase+HDFS的方式来分开存储元数据和MOB文件。一个文件对应一个Hbase入口。这是客户端的解决方案,事务在客户端控制。MOB不会消耗Hbase的内存。存储的对象可以超过50MB。但是,大量的小文件使HDFS利用率不高,因为默认的块大小是128M。
举个例子,NameNode有48G内存,每个文件100KB,3个副本。每个文件在内存中占用300字节,48G内存可以存大约1.6亿文件,限制了存储的总文件大小仅仅16T。
As an improvement, we could have assembled the small MOB files into bigger ones—that is, a file could have multiple MOB entries–and store the offset and length in the HBase table for fast reading. However, maintaining data consistency and managing deleted MOBs and small MOB files in compactions are difficult. Furthermore, if we were to use this approach, we’d have to consider new security policies, lose atomicity properties of writes, and potentially lose the backup and disaster recovery provided by replication and snapshots.
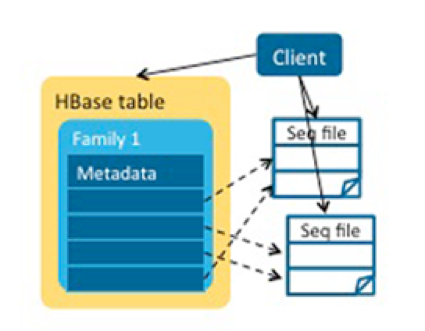
我们可以许多小的MOB合成一个大文件,一个文件有多个MOB入口,通过存储偏移量(offset)和长度来加快读取。不过维护数据一致性,管理删除的文件和压缩后的小文件十分困难。而且,我们还需要考虑安全策略,失去写数据的原子性,可能会丢失由复制和快照提供的备份和灾难恢复。
HBase MOB 架构设计
In the end, because most of the concerns around storing MOBs in HBase involve the I/O created by compactions, the key was to move MOBs out of management by normal regions to avoid region splits and compactions there.
The HBase MOB design is similar to the HBase + HDFS approach because we store the metadata and MOBs separately. However, the difference lies in a server-side design: memstore caches the MOBs before they are flushed to disk, the MOBs are written into a HFile called “MOB file” in each flush, and each MOB file has multiple entries instead of single file in HDFS for each MOB. This MOB file is stored in a special region. All the read and write can be used by the current HBase APIs.
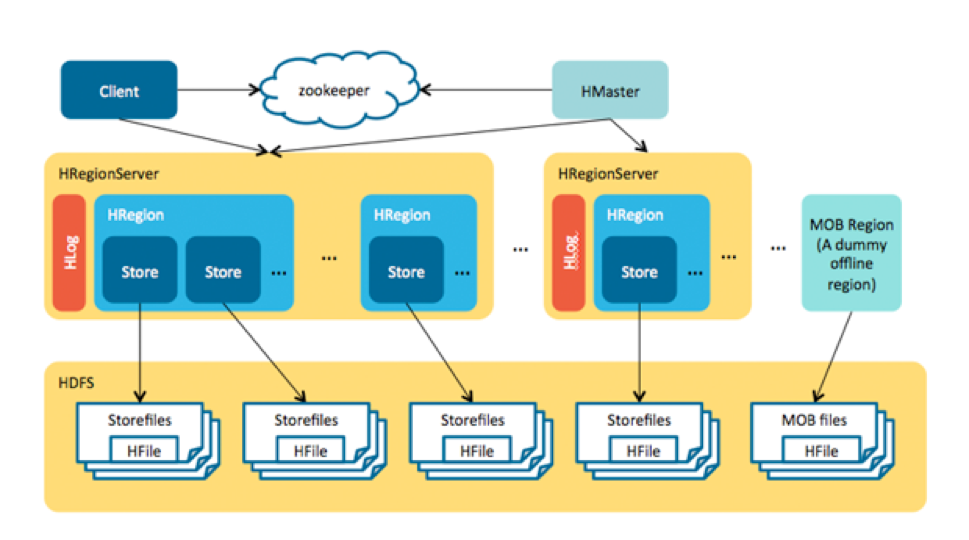
最后,由于大部分担心来自于压缩带来的IO,最关键的是将MOB移出正常region的管理来避免region分割和压缩。
HBase MOB设计类似于Hbase+HDFS的方式,将元数据和MOB分开存。不同的是服务端的设计。中等大小文件在被刷到磁盘前缓存在memstore里,每次刷新,中等大小文件被写入特殊的HFile文件—“MOB File”。每个中等文件有多个MOB入口,而不像HDFS只有一个入口。MOB file被放在特殊的region。读写都通过现有的Hbase API。