定义类(init只负责初始化)
class 类名:
方法列表
# 定义汽车类
class Car:
def __init__(self, newWheelNum, newColor):
self.wheelNum = newWheelNum
self.color = newColor
def move(self):
print('车在跑,目标:夏威夷')
# 创建对象
BMW = Car(4, 'green')
print('车的颜色为:%s'%BMW.color)
print('车轮子数量为:%d'%BMW.wheelNum)
__init__()方法,在创建一个对象时默认被调用,不需要手动调用__init__(self)中,默认有1个参数名字为self,如果在创建对象时传递了2个实参,那么__init__(self)中出了self作为第一个形参外还需要2个形参,例如__init__(self,x,y)__init__(self)中的self参数,不需要开发者传递,python解释器会自动把当前的对象引用传递进去
class Car:
def __init__(self, newWheelNum, newColor):
self.wheelNum = newWheelNum
self.color = newColor
// 这里的 __str__就是OC里面的discription函数,用来打印类的信息,默认是打印地址的
def __str__(self):
msg = "嘿。。。我的颜色是" + self.color + "我有" + int(self.wheelNum) + "个轮胎..."
return msg
def move(self):
print('车在跑,目标:夏威夷')
BMW = Car(4, "白色")
print(BMW)
保护对象的属性(getter setter)
如果有一个对象,当需要对其进行修改属性时,有2种方法
- 对象名.属性名 = 数据 ---->直接修改
- 对象名.方法名() ---->间接修改
为了更好的保存属性安全,即不能随意修改,一般的处理方式为
- 将属性定义为私有属性
- 添加一个可以调用的方法,供调用
class People(object):
def __init__(self, name):
self.__name = name
def getName(self):
return self.__name
def setName(self, newName):
if len(newName) >= 5:
self.__name = newName
else:
print("error:名字长度需要大于或者等于5")
xiaoming = People("dongGe")
xiaoming.setName("wanger")
print(xiaoming.getName())
xiaoming.setName("lisi")
print(xiaoming.getName())
- Python中没有像C++中public和private这些关键字来区别公有属性和私有属性
- 它是以属性命名方式来区分,如果在属性名前面加了2个下划线'__',则表明该属性是私有属性,否则为公有属性(方法也是一样,方法名前面加了2个下划线的话表示该方法是私有的,否则为公有的)。
__del__() 方法
创建对象后,python解释器默认调用__init__()方法;
当删除一个对象时,python解释器也会默认调用一个方法,这个方法为__del__()方法
OC 里面的dealloc方法
import time
class Animal(object):
# 初始化方法
# 创建完对象后会自动被调用
def __init__(self, name):
print('__init__方法被调用')
self.__name = name
# 析构方法
# 当对象被删除时,会自动被调用
def __del__(self):
print("__del__方法被调用")
print("%s对象马上被干掉了..."%self.__name)
# 创建对象
dog = Animal("哈皮狗")
# 删除对象
del dog
cat = Animal("波斯猫")
cat2 = cat
cat3 = cat
print("---马上 删除cat对象")
del cat
print("---马上 删除cat2对象")
del cat2
print("---马上 删除cat3对象")
del cat3
print("程序2秒钟后结束")
time.sleep(2)
就是OC的引用计数问题,一样的
单继承
class Animal(object):
def __init__(self, name='动物', color='白色'):
self.__name = name
self.color = color
def __test(self):
print(self.__name)
print(self.color)
def test(self):
print(self.__name)
print(self.color)
class Dog(Animal):
def dogTest1(self):
#print(self.__name) #不能访问到父类的私有属性
print(self.color)
def dogTest2(self):
#self.__test() #不能访问父类中的私有方法
self.test()
A = Animal()
#print(A.__name) #程序出现异常,不能访问私有属性
print(A.color)
#A.__test() #程序出现异常,不能访问私有方法
A.test()
print("------分割线-----")
D = Dog(name = "小花狗", color = "黄色")
D.dogTest1()
D.dogTest2()
- 私有的属性,不能通过对象直接访问,但是可以通过方法访问
- 私有的方法,不能通过对象直接访问
- 私有的属性、方法,不会被子类继承,也不能被访问
- 一般情况下,私有的属性、方法都是不对外公布的,往往用来做内部的事情,起到安全的作用
多继承
#coding=utf-8
class base(object):
def test(self):
print('----base test----')
class A(base):
def test(self):
print('----A test----')
# 定义一个父类
class B(base):
def test(self):
print('----B test----')
# 定义一个子类,继承自A、B
class C(A,B):
pass
obj_C = C()
obj_C.test()
print(C.__mro__) #可以查看C类的对象搜索方法时的先后顺序
# ----A test----
# (<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.base'>, <class 'object'>)这里如果继承的方法都是一样的,可以子类优先,类.__mro__会打印出对象搜索的方法
#coding=utf-8
class Cat(object):
def __init__(self,name):
self.name = name
self.color = 'yellow'
class Bosi(Cat):
def __init__(self,name):
# 调用父类的__init__方法1(python2)
#Cat.__init__(self,name)
# 调用父类的__init__方法2
#super(Bosi,self).__init__(name)
# 调用父类的__init__方法3
super().__init__(name)
def getName(self):
return self.name
bosi = Bosi('xiaohua')
print(bosi.name)
print(bosi.color)
类属性和实例属性
class People(object):
name = 'Tom' #公有的类属性
__age = 12 #私有的类属性
p = People()
print(p.name) #正确
print(People.name) #正确
print(p.__age) #错误,不能在类外通过实例对象访问私有的类属性
print(People.__age) #错误,不能在类外通过类对象访问私有的类属性
class People(object):
address = '山东' #类属性
def __init__(self):
self.name = 'xiaowang' #实例属性
self.age = 20 #实例属性
p = People()
p.age =12 #实例属性
print(p.address) #正确
print(p.name) #正确
print(p.age) #正确
print(People.address) #正确
print(People.name) #错误
print(People.age) #错误
class People(object):
country = 'china' #类属性
print(People.country)
p = People()
print(p.country)
p.country = 'japan'
print(p.country) #实例属性会屏蔽掉同名的类属性
print(People.country)
del p.country #删除实例属性
print(p.country)
- 如果需要在类外修改
类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
类方法
是类对象所拥有的方法,需要用修饰器@classmethod
来标识其为类方法,对于类方法,第一个参数必须是类对象,一般以
cls
作为第一个参数(当然可以用其他名称的变量作为其第一个参数,但是大部分人都习惯以'cls'作为第一个参数的名字,就最好用'cls'了),能够通过实例对象和类对象去访问。
class People(object):
country = 'china'
#类方法,用classmethod来进行修饰
@classmethod
def getCountry(cls):
return cls.country
p = People()
print p.getCountry() #可以用过实例对象引用
print People.getCountry() #可以通过类对象引用
静态方法
class People(object):
country = 'china'
@staticmethod
#静态方法
def getCountry():
return People.country
print People.getCountry()
从类方法和实例方法以及静态方法的定义形式就可以看出来,类方法的第一个参数是类对象cls,那么通过cls引用的必定是类对象的属性和方法;而实例方法的第一个参数是实例对象self,那么通过self引用的可能是类属性、也有可能是实例属性(这个需要具体分析),不过在存在相同名称的类属性和实例属性的情况下,实例属性优先级更高。静态方法中不需要额外定义参数,因此在静态方法中引用类属性的话,必须通过类对象来引用
工厂模式
在父类留下接口,在子类进行实现,因此各个子类表现出来的形式就不同
# 定义一个基本的4S店类
class CarStore(object):
#仅仅是定义了有这个方法,并没有实现,具体功能,这个需要在子类中实现
def createCar(self, typeName):
pass
def order(self, typeName):
# 让工厂根据类型,生产一辆汽车
self.car = self.createCar(typeName)
self.car.move()
self.car.stop()
# 定义一个北京现代4S店类
class XiandaiCarStore(CarStore):
def createCar(self, typeName):
self.carFactory = CarFactory()
return self.carFactory.createCar(typeName)
# 定义伊兰特车类
class YilanteCar(object):
# 定义车的方法
def move(self):
print("---车在移动---")
def stop(self):
print("---停车---")
# 定义索纳塔车类
class SuonataCar(object):
# 定义车的方法
def move(self):
print("---车在移动---")
def stop(self):
print("---停车---")
# 定义一个生产汽车的工厂,让其根据具体得订单生产车
class CarFactory(object):
def createCar(self,typeName):
self.typeName = typeName
if self.typeName == "伊兰特":
self.car = YilanteCar()
elif self.typeName == "索纳塔":
self.car = SuonataCar()
return self.car
suonata = XiandaiCarStore()
suonata.order("索纳塔")
__new__方法(只负责创建)
class A(object):
def __init__(self):
print("这是 init 方法")
def __new__(cls):
print("这是 new 方法")
return object.__new__(cls)
A()
__new__至少要有一个参数cls,代表要实例化的类,此参数在实例化时由Python解释器自动提供__new__必须要有返回值,返回实例化出来的实例,这点在自己实现__new__时要特别注意,可以return父类__new__出来的实例,或者直接是object的__new__出来的实例__init__有一个参数self,就是这个__new__返回的实例,__init__在__new__的基础上可以完成一些其它初始化的动作,__init__不需要返回值我们可以将类比作制造商,
__new__方法就是前期的原材料购买环节,__init__方法就是在有原材料的基础上,加工,初始化商品环节
单例模式和只初始化一次
class Dog(object):
"""docstring for Dog"""
# def __init__(self, arg):
# super(Dog, self).__init__()
# self.arg = arg
#
instance = None
firstInit = False
def __new__(cls,name,age):
if not cls.instance:
cls.instance = object.__new__(cls)
return cls.instance
else:
return cls.instance
def __init__(self,name,age):
if Dog.firstInit == False:
self.name = name
self.age = age
Dog.firstInit = True
dog1 = Dog("Tom",12)
print("%s + %s"%(id(dog1),dog1.name))
dog2 = Dog("Jerry",20)
print("%s + %s"%(id(dog2),dog2.name))
4328148104 + Tom
4328148104 + Tom
***Repl Closed***
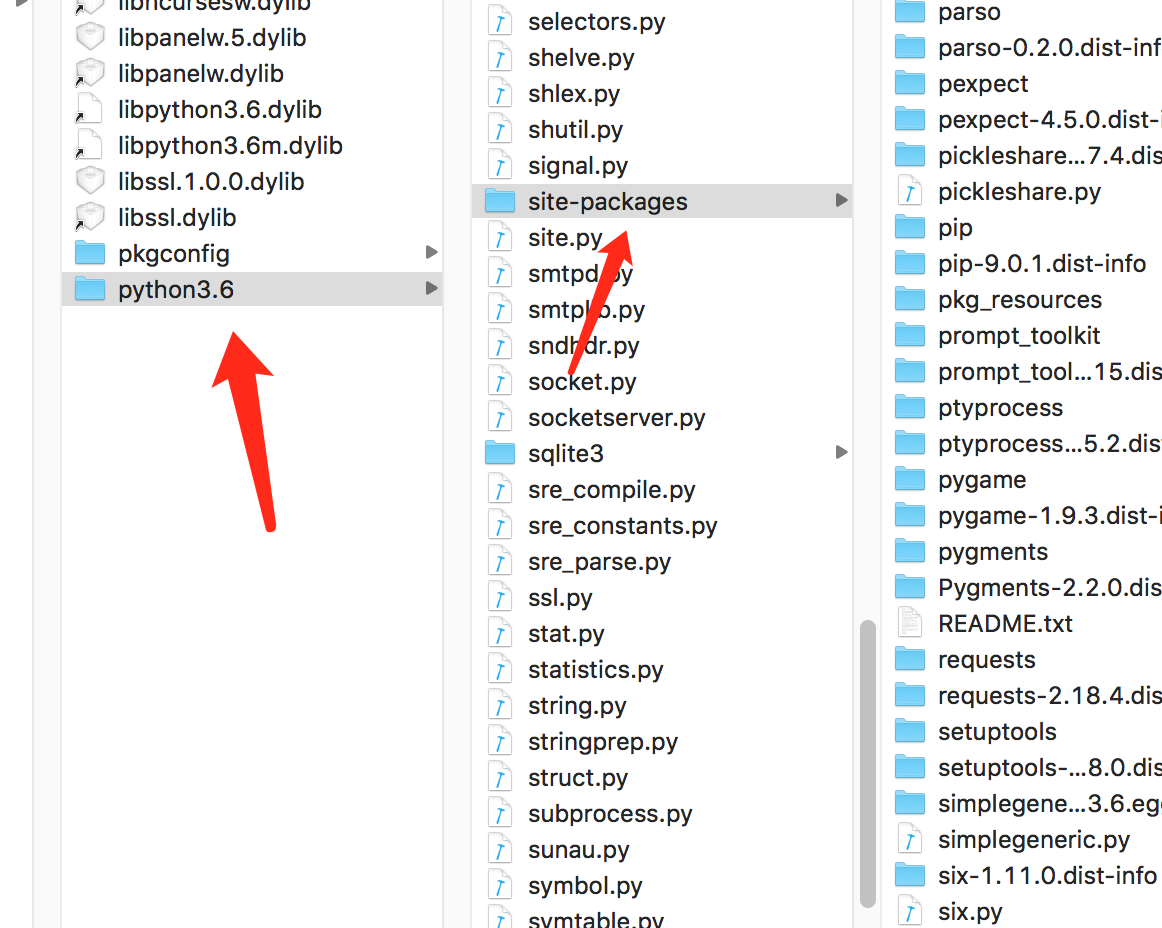
系统第三方模块
如果装的是3.6,系统自带的是2.7
In [1]: import sys In [2]: import os In [3]: os.__file__ Out[3]: '/Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/os.py'
cd到路径下面就是系统默认自带的模块
安装第三方模块
sudo pip3 install pygame 在版本3路径下安装
sudo pip install pygame 在版本2路径下安装
两种检验方式是否安装成功
1.ipython3环境下
import 安装的模块,如果不报错,即可
2.在模块目录下查找
自建模块
import math
#这样会报错
print sqrt(2)
#这样才能正确输出结果
print math.sqrt(2)
from 模块名 import 函数名1,函数名2....通过这种方式引入的时候,调用函数时只能给出函数名,不能给出模块名,但是当两个模块中含有相同名称函数的时候,后面一次引入会覆盖前一次引入。也就是说假如模块A中有函数function( ),在模块B中也有函数function( ),如果引入A中的function在先、B中的function在后,那么当调用function函数的时候,是去执行模块B中的function函数。
如果想一次性引入math中所有的东西,还可以通过from math import *来实现
Python的from语句让你从模块中导入一个指定的部分到当前命名空间中
语法如下:
from modname import name1[, name2[, ... nameN]]
例如,要导入模块fib的fibonacci函数,使用如下语句:
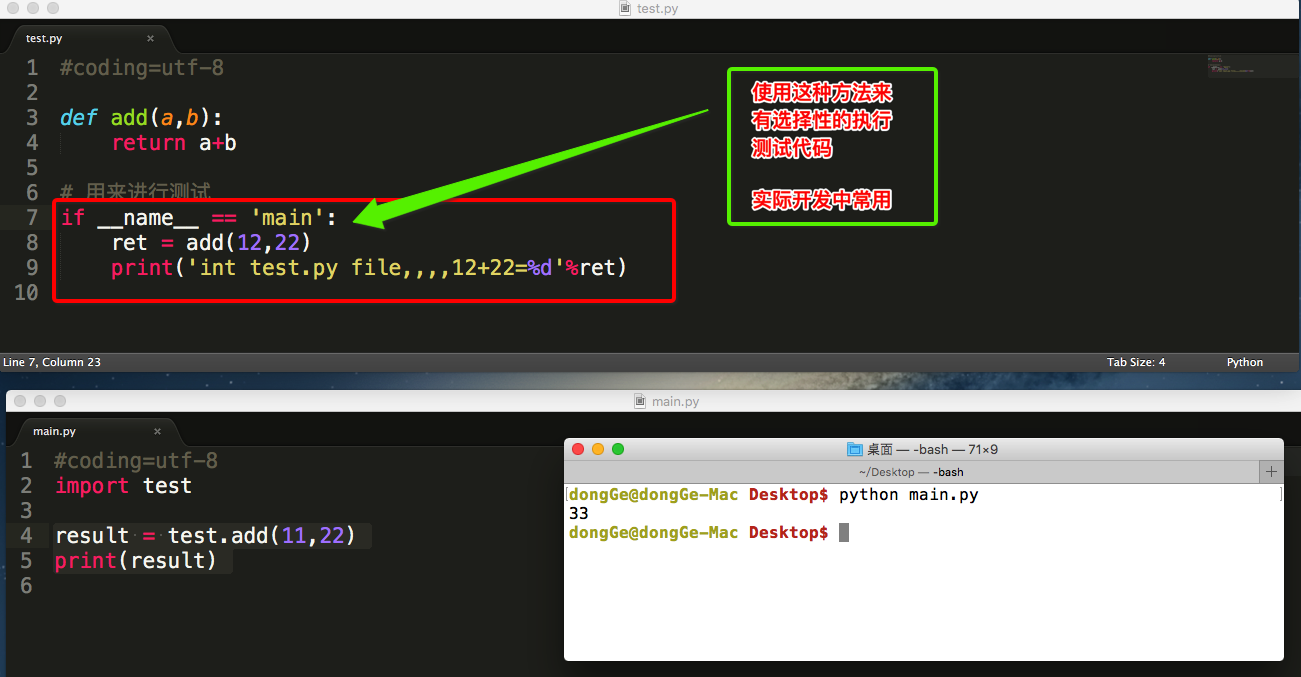
from fib import fibonacci自建py模块的时候在其他文件import的时候,是会把模块的文件都执行一遍,例如你里面有print这些函数,也会在import的时候直接导入,因此在自建模块的里面,要用__name__来控制,自己运行__name__ = __main__ 如果是import运行,__name__就是test,因此可以根据这个字段判断是否在自测模块的时候打印,别人import的时候不执行打印
from xxx import *该方法导入的模块,如果模块里面有__all__参数,只能导入__all__ = ["函数1","类1"]列出的功能函数或者方法类
给程序传参
import sys print(sys.argv)
在模块里面导入sys,然后终端执行
python3 xxx.py 参数一 参数二
模块里面就会接收到参数打印数组出来
列表生成式
Range在Python2中你要多少数组大小是直接给你的,因此你这样拿的话内存会可能爆炸
在Python3中就是动态给你的,而不是你Range多少都直接返回数组给你,你用到的时候才会给你数据分配空间
In [2]: a = [i for i in range(1,20)] In [3]: a Out[3]: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
In [4]: a = [i for i in range(1,20) if i%2==0] In [5]: a Out[5]: [2, 4, 6, 8, 10, 12, 14, 16, 18]
In [6]: a = [(i,j) for i in range(1,3) for j in range(1,5)] In [7]: a Out[7]: [(1, 1), (1, 2), (1, 3), (1, 4), (2, 1), (2, 2), (2, 3), (2, 4)]
深Copy和浅Copy
deepcopy(递归深copy)
In [71]: a = [1,2,3] In [72]: b = [4,5,6] In [73]: c = [a,b] In [74]: c Out[74]: [[1, 2, 3], [4, 5, 6]] In [75]: id(a) Out[75]: 4406509384 In [76]: id(b) Out[76]: 4404327368 In [77]: id(c[0]) Out[77]: 4406509384 In [78]: import copy In [79]: d = copy.deepcopy(c) In [80]: id(c) Out[80]: 4404619720 In [81]: id(d) Out[81]: 4407108424 In [82]: id(d[0]) Out[82]: 4404570248 In [83]: a.append(1000) In [84]: a Out[84]: [1, 2, 3, 1000] In [85]: c[0] Out[85]: [1, 2, 3, 1000] In [86]: d[0] Out[86]: [1, 2, 3] In [87]: d Out[87]: [[1, 2, 3], [4, 5, 6]]
上面的是递归深copy的操作,因此复制出来的是完全开辟另一个空间的全部内容复制,源对象的修改不会影响后面
copy(深copy)-->可变类型数组
In [89]: a = [1,2,3] In [90]: b = [4,5,6] In [91]: c = [a,b] In [92]: c Out[92]: [[1, 2, 3], [4, 5, 6]] In [93]: d = copy.copy(c) In [94]: a Out[94]: [1, 2, 3] In [95]: id(a) Out[95]: 4407079304 In [96]: id(b) Out[96]: 4407079816 In [97]: id(c) Out[97]: 4404548808 In [98]: id(d) Out[98]: 4407106120 In [99]: id(d[0]) Out[99]: 4407079304 In [100]: a.append(1000) In [101]: a Out[101]: [1, 2, 3, 1000] In [102]: b Out[102]: [4, 5, 6] In [103]: c Out[103]: [[1, 2, 3, 1000], [4, 5, 6]] In [104]: d Out[104]: [[1, 2, 3, 1000], [4, 5, 6]]上面的内容可以看出,针对copy的操作,不会进行递归,只是对容器的copy,容器由于是可变类型数组,那么容器的地址c和d是不同的,但是容器内部的指针是不会进行深copy的,沿用之前的对象,源对象改变,能改变后面所有值
copy(深copy)-->不可变元祖
In [111]: a = [1,2,3] In [112]: b = [4,5,6] In [113]: c = (a,b) In [114]: d = copy.copy(c) In [115]: id(c) Out[115]: 4406812232 In [116]: id(d) Out[116]: 4406812232 In [117]: a.append(1000) In [118]: a Out[118]: [1, 2, 3, 1000] In [119]: c Out[119]: ([1, 2, 3, 1000], [4, 5, 6]) In [120]: d Out[120]: ([1, 2, 3, 1000], [4, 5, 6])针对不可变类型的copy就是浅copy,指针copy,其他和上面一样
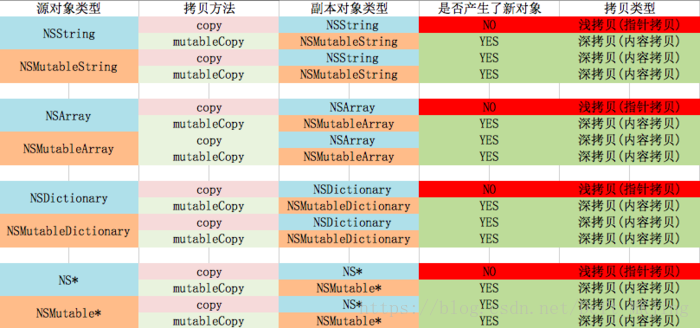
OC里面的mutableCopy就是python里面的copy
NSMutableArray *a = [[NSMutableArray alloc] initWithArray:@[@"1",@"2",@"3"]];
NSMutableArray *b = [[NSMutableArray alloc] initWithArray:@[@"222",@"333",@"444"]];
NSArray *c = @[a,b];
NSLog(@"%@ %p",c,c);
NSLog(@"a的地址%p",a);
NSLog(@"b的地址%p",b);
NSArray *d = c.mutableCopy;
NSLog(@"%@ %p",d,d);
NSLog(@"a的地址%p",d[0]);
NSLog(@"b的地址%p",d[1]);
NSArray *e = c.copy;
NSLog(@"%@ %p",e,e);
NSLog(@"a的地址%p",e[0]);
NSLog(@"b的地址%p",e[1]);
[a addObject:@"10000"];
NSLog(@"%@",c);
NSLog(@"%@",d);
NSLog(@"%@",e);
2018-06-19 10:24:28.929903+0800 Mutable[3954:70431] (
(
1,
2,
3
),
(
222,
333,
444
)
) 0x600000026a40
2018-06-19 10:24:28.930026+0800 Mutable[3954:70431] a的地址0x6000000489d0
2018-06-19 10:24:28.930111+0800 Mutable[3954:70431] b的地址0x600000048340
2018-06-19 10:24:28.930215+0800 Mutable[3954:70431] (
(
1,
2,
3
),
(
222,
333,
444
)
) 0x604000057af0
2018-06-19 10:24:28.930301+0800 Mutable[3954:70431] a的地址0x6000000489d0
2018-06-19 10:24:28.930390+0800 Mutable[3954:70431] b的地址0x600000048340
2018-06-19 10:24:28.930493+0800 Mutable[3954:70431] (
(
1,
2,
3
),
(
222,
333,
444
)
) 0x600000026a40
2018-06-19 10:24:28.930573+0800 Mutable[3954:70431] a的地址0x6000000489d0
2018-06-19 10:24:28.930670+0800 Mutable[3954:70431] b的地址0x600000048340
2018-06-19 10:24:28.930770+0800 Mutable[3954:70431] (
(
1,
2,
3,
10000
),
(
222,
333,
444
)
)
2018-06-19 10:24:28.930876+0800 Mutable[3954:70431] (
(
1,
2,
3,
10000
),
(
222,
333,
444
)
)
2018-06-19 10:24:28.930994+0800 Mutable[3954:70431] (
(
1,
2,
3,
10000
),
(
222,
333,
444
)
)
下面的图是OC对象的copy操作,基本上操作和python一致
property
方案一
class Person(object): """docstring for Person""" def __init__(self): super(Person, self).__init__() self.__age = 100 def getAge(self): return self.__age def setAge(self,newAge): self.__age = newAge age = property(getAge,setAge) person = Person() print(person.age) person.age = 200 print(person.age)
方案二
class Money(object): """docstring for Money""" def __init__(self): super(Money, self).__init__() self.__num = 100000 @property def num(self): return self.__num @num.setter def num(self,newNum): self.__num = newNum money = Money() print(money.num) money.num = 100000000 print(money.num)
迭代器
迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
以直接作用于 for 循环的数据类型有以下几种:
一类是集合数据类型,如 list 、 tuple 、 dict 、 set 、 str 等;
一类是 generator ,包括生成器和带 yield 的generator function。
这些可以直接作用于 for 循环的对象统称为可迭代对象: Iterable 。
是否可迭代
In [1]: from collections import Iterable
In [2]: isinstance(100,Iterable)
Out[2]: False
In [3]: isinstance("dsds",Iterable)
Out[3]: True
In [4]: isinstance({},Iterable)
Out[4]: True
In [5]: isinstance([1,2,3],Iterable)
Out[5]: True
In [6]: isinstance((x for x in range(10)),Iterable)
Out[6]: True
是否迭代器
In [1]: from collections import Iterator
In [2]: a = [1,2,3]
In [3]: isinstance(a,Iterator)
Out[3]: False
In [4]: isinstance({},Iterator)
Out[4]: False
In [5]: isinstance(x for x in range(10),Iterator)
File "<ipython-input-5-0792a32e488c>", line 1
isinstance(x for x in range(10),Iterator)
^
SyntaxError: Generator expression must be parenthesized if not sole argument
In [6]: isinstance((x for x in range(10)),Iterator)
Out[6]: True
字符串,list,字典都是可迭代
可迭代的东西不一定是可迭代对象,但是生成器必定是 (x for x in range(10))
可以用iter()来把 数组字典这些可迭代的换成可迭代的对象
这么做有个好处,数组字典一开始都已经开辟了控件,如果你需要用的时候再开辟,就可以转成迭代器来提高性能
- 凡是可作用于 for 循环的对象都是 Iterable 类型;
- 凡是可作用于 next() 函数的对象都是 Iterator 类型
- 集合数据类型如 list 、 dict 、 str 等是 Iterable 但不是 Iterator ,不过可以通过 iter() 函数获得一个 Iterator 对象。
闭包
内部函数对外部函数作用域里变量的引用(非全局变量),则称内部函数为闭包。def test1(number1): def test2(number2): print(number1 + number2) return test2 a = test1(100) a(200) a(1000) a(1) 300 1100 101 ***Repl Closed***
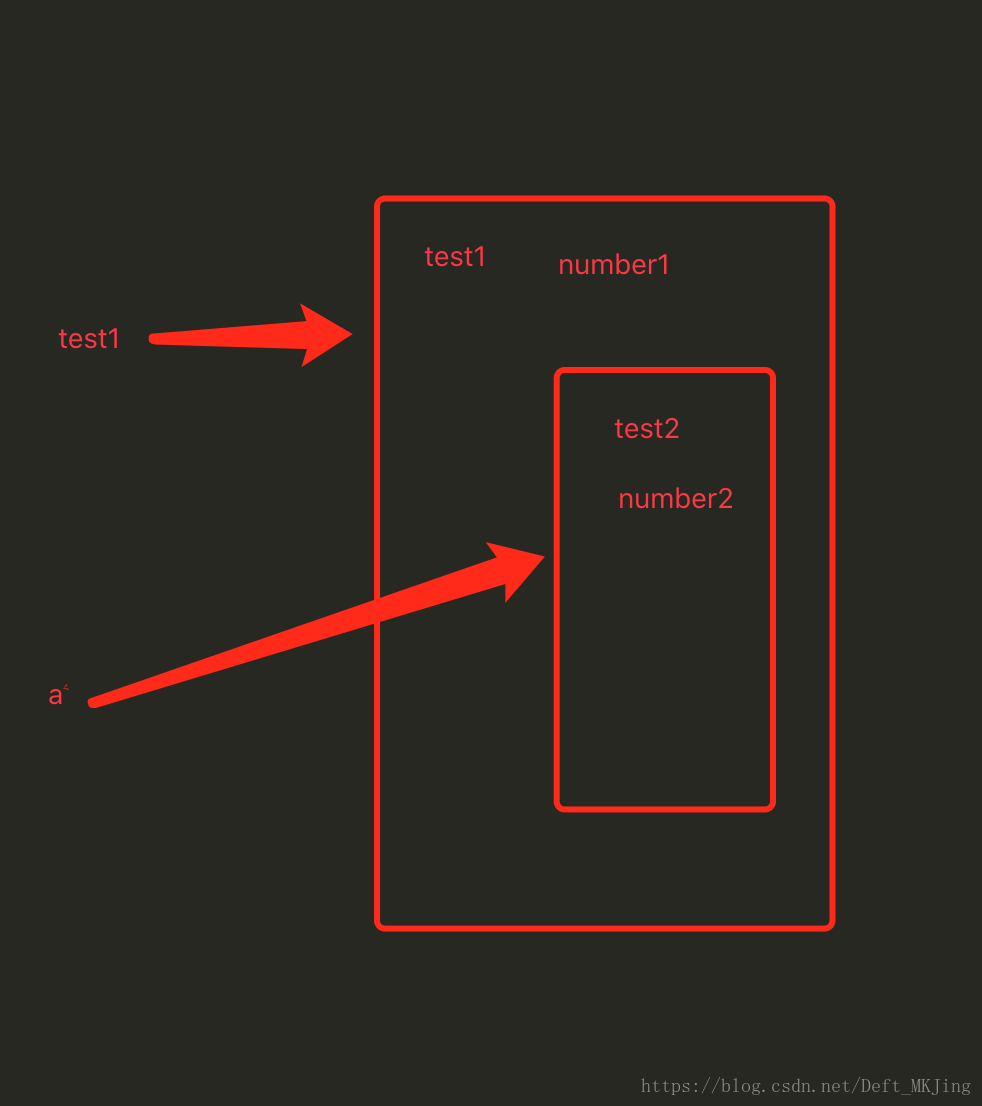
按照iOS的的思路去理解,其实关于对象的内存问题,基本都是一样的,有变量强引用的情况下就不会被回收,那么就很好理解闭包了
在函数内部再定义一个函数,并且这个函数用到了外部函数的变量,那么将这个函数和用到一些变量称之为闭包。
可以看到定一个一个test1函数,开辟了内存,有个变量number1,然后函数内部又定义了一个test2函数,由test1函数返回给外部变量a绑定指着,那么外部每次调用a,也就是调用了test1函数内部的test2函数,每次调用都会去拿最早之前传进去的numer1的值,为什么调用完函数之后,test1没有被回收,因为其内部还有个函数,被外部的变量a强引用着,因此只要a不会销毁,test1就会一直存在,number1也就一直存在,好处是调用的时候直接拿,坏处是一直占用着内存
1.闭包似优化了变量,原来需要类对象完成的工作,闭包也可以完成
2.由于闭包引用了外部函数的局部变量,则外部函数的局部变量没有及时释放,消耗内存装饰器
# 语法糖
def updateTaskWithAuth(func):
def authorlizations():
print("验证权限")
func()
return authorlizations
@updateTaskWithAuth
def func2():
print("业务二")
@updateTaskWithAuth
def func1():
print("业务一")
# 原始调用 一
# func1()
# func2()
# 新增鉴权 二
# func1 = updateTaskWithAuth(func1)
# func1()
# func2 = updateTaskWithAuth(func2)
# func2()
# 依旧原始调用
# 在闭包中,如果不改变原始调用,新增功能,可以另外写一个方法,然后通过传入原先的业务功能例如func1,最终改变func1默认函数指针的指向
# 改为指向闭包内部返回的函数即可,如果用语法糖就需要在业务函数外部加上@闭包函数名,然后原样调用,就是直接赋值的效果
func1()
func2()
- 引入日志
- 函数执行时间统计
- 执行函数前预备处理
- 执行函数后清理功能
- 权限校验等场景
- 缓存
其实可以看到,无非就是在调用原函数的时候,在外部不变的情况下,类似iOS的中的RuntimeHook函数,只是实现稍微有点不同而已,Python是通过@语法糖里面的闭包来实现,iOS是Runtime底层交换方法来实现,再不改原先逻辑的情况下,在方法之前嵌入自己的逻辑,例如日志,统计,预处理,清理,校验等场景
这里明白@updateTaskWithAuth就已经会执行一段代码例如
func1 = updateTaskWithAuth(func1)改变了原先func1的指向罢了,但是这句代码是会执行的,当从上到下遇到@装饰时时会先执行的
多个装饰器
def w1(func):
print("装饰1")
def inner():
print("插入功能1")
func()
return inner
def w2(func):
print("装饰2")
def inner():
print("插入功能2")
func()
return inner
@w1
@w2
def func1():
print("业务1")
func1()
装饰2
装饰1
插入功能1
插入功能2
业务1
***Repl Closed***

根据图片分析下,首先编译器遇到@w1和@w2,这里是会有代码执行的,上面有介绍,就不展开了,但是前提是装饰器的下一句代码是方法函数,才会装饰,因此先跳过@w1,然后@w2就会对func函数进行装饰,因此先执行装饰2,然后返回的值就是inner函数,再执行装饰1,执行的时候就是先执行装饰1里面的inner函数,然后在执行装饰2里面的inner函数,好比一个东西,包装的时候由内到外,执行的时候由外到内,这就是多层装饰的逻辑
万能通用装饰器(iOS中的MethodSwizzle效果)
def func(funcTemp):
print("装饰函数----开始装饰")
def innderFunc(*args,**kwargs):
print("装饰函数----执行装饰实际代码例如插入,验证,统计等。。。。。。")
return funcTemp(*args,**kwargs)
return innderFunc
@func
def func1():
print("无参数,无返回值")
@func
def func2():
print("无参数,有返回值")
return "宓珂璟"
@func
def func3(a):
print("有一个参数 %d"%(a))
@func
def func4(a,b,c):
print("有多个参数 %d,%d,%d"%(a,b,c))
return a + b + c
print(func1())
print(func2())
print(func3(100))
print(func4(100,200,300))
装饰函数----开始装饰
装饰函数----开始装饰
装饰函数----开始装饰
装饰函数----开始装饰
装饰函数----执行装饰实际代码例如插入,验证,统计等。。。。。。
无参数,无返回值
None
装饰函数----执行装饰实际代码例如插入,验证,统计等。。。。。。
无参数,有返回值
宓珂璟
装饰函数----执行装饰实际代码例如插入,验证,统计等。。。。。。
有一个参数 100
None
装饰函数----执行装饰实际代码例如插入,验证,统计等。。。。。。
有多个参数 100,200,300
600
***Repl Closed***
这就是一个通用装饰器
如果装饰器要带参数,外面再包一层即可
from time import ctime, sleep
def timefun_arg(pre="hello"):
def timefun(func):
def wrappedfunc():
print("%s called at %s %s"%(func.__name__, ctime(), pre))
return func()
return wrappedfunc
return timefun
@timefun_arg("itcast")
def foo():
print("I am foo")
@timefun_arg("python")
def too():
print("I am too")
foo()
sleep(2)
foo()
too()
sleep(2)
too()
foo()==timefun_arg("itcast")(foo)()
作用域
globals() 打印出所有全局变量
locals() 打印出函数局部变量里面的所有局部变量
dir(__builtin__) 查看内建模块函数
Python 使用 LEGB 的顺序来查找一个符号对应的对象
locals -> enclosing function -> globals -> builtins
- locals,当前所在命名空间(如函数、模块),函数的参数也属于命名空间内的变量
- enclosing,外部嵌套函数的命名空间(闭包中常见)
- globals,全局变量,函数定义所在模块的命名空间
builtins,内建模块的命名空间。
生成器
在Python中,这种一边循环一边计算的机制,称为生成器:generator方法一 [] ---> ()
In [15]: L = [ x*2 for x in range(5)] In [16]: L Out[16]: [0, 2, 4, 6, 8] In [17]: G = ( x*2 for x in range(5)) In [18]: G Out[18]: <generator object <genexpr> at 0x7f626c132db0> In [19]:方法二(yield)
def fib(times): a,b = 0,1 n = 0 print("----1-----") while n<times: print("----2-----") yield b print("----3-----") a,b = b,a+b n += 1 return "宓珂璟" def hehe(gerner): for x in gerner: print(x) F = fib(5) hehe(F) ----1----- ----2----- 1 ----3----- ----2----- 1 ----3----- ----2----- 2 ----3----- ----2----- 3 ----3----- ----2----- 5 ----3----- ***Repl Closed***在循环过程中就会不断调用yield,并且不断中断,只有当我们调用next的时候才会继续执行,遇到yield继续中断,或者直接遍历生成器也能不断调用执行yield
send可以给yield赋值的变量传值
def test():
i = 0
while i<6:
temp = yield i
print(temp)
i+=1
t = test()
print(next(t))
print(next(t))
t.send("宓珂璟")
print(next(t))
print(next(t))
print(next(t))
# 0
# None
# 1
# 宓珂璟
# None
# 3
# None
# 4
# None
# 5
# ***Repl Closed***
生成器的特点:
- 节约内存
- 迭代到下一次的调用时,所使用的参数都是第一次所保留下的,即是说,在整个所有函数调用的参数都是第一次所调用时保留的,而不是新创建的
对比看下简单的迭代器和生成器,就是把原先数组需要开辟的空间,通过一边使用一边开辟,节约内存
In [2]: def test(): ...: n = 0 ...: while(n<6): ...: yield n ...: n += 1 ...: In [3]: a = test() In [4]: a Out[4]: <generator object test at 0x106894728> In [5]: b = [1,2,3] In [6]: b Out[6]: [1, 2, 3] In [7]: b = iter(b) In [8]: b Out[8]: <list_iterator at 0x1068ab9b0> In [9]: c = (x for x in range(10)) In [10]: c Out[10]: <generator object <genexpr> at 0x106894fc0>
元类
元类就是用来创建类的“东西”和OC一样,class也是一种对象,他的父类就是元类
>>> print type(1) #数值的类型
<type 'int'>
>>> print type("1") #字符串的类型
<type 'str'>
>>> print type(ObjectCreator()) #实例对象的类型
<class '__main__.ObjectCreator'>
>>> print type(ObjectCreator) #类的类型
<type 'type'>
类的type是 'type'
In [16]: class MK(object):
...: def __init__(self):
...: self.name = None
...:
In [17]: type(MK)
Out[17]: type
In [18]: a = MK()
In [19]: a
Out[19]: <__main__.MK at 0x1069d5eb8>
In [20]: type(a)
Out[20]: __main__.MK
In [21]: type(MK)
Out[21]: type
In [22]: clear
In [23]: myDogClass = type("MyDog",(),{})
In [24]: myDogClass
Out[24]: __main__.MyDog
In [25]: MK()
Out[25]: <__main__.MK at 0x106971518>
In [27]: print(MK) <class '__main__.MK'> In [28]: print(myDogClass) <class '__main__.MyDog'> In [29]: print(myDogClass()) <__main__.MyDog object at 0x106971860>
type(类名, 由父类名称组成的元组(针对继承的情况,可以为空),包含属性的字典(名称和值)以及静态或者类方法)
内建属性
In [2]: class Person(object): ...: pass ...: ...: In [3]: dir(Person) Out[3]: ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__']
| 常用专有属性 | 说明 | 触发方式 |
|---|---|---|
__init__ |
构造初始化函数 | 创建实例后,赋值时使用,在__new__后 |
__new__ |
生成实例所需属性 | 创建实例时 |
__class__ |
实例所在的类 | 实例.__class__ |
__str__ |
实例字符串表示,可读性 | print(类实例),如没实现,使用repr结果 |
__repr__ |
实例字符串表示,准确性 | 类实例 回车 或者 print(repr(类实例)) |
__del__ |
析构 | del删除实例 |
__dict__ |
实例自定义属性 | vars(实例.__dict__) |
__doc__ |
类文档,子类不继承 | help(类或实例) |
__getattribute__ |
属性访问拦截器 | 访问实例属性时 |
__bases__ |
类的所有父类构成元素 | 类名.__bases__ |
class Itcast(object):
def __init__(self,subject1):
self.subject1 = subject1
self.subject2 = 'cpp'
#属性访问时拦截器,打log
def __getattribute__(self,obj):
if obj == 'subject1':
print('log subject1')
return 'redirect python'
else: #测试时注释掉这2行,将找不到subject2
return object.__getattribute__(self,obj)
def show(self):
print('this is Itcast')
s = Itcast("python")
print(s.subject1)
print(s.subject2)
__getattribute__
例子中后面跟的参数self是自身,obj就是对应的属性字符串名字
log subject1
redirect python
cpp__getattribute__的坑
class Person(object):
def __getattribute__(self,obj):
print("---test---")
if obj.startswith("a"):
return "hahha"
else:
return self.test
def test(self):
print("heihei")
t.Person()
t.a #返回hahha
t.b #会让程序死掉
#原因是:当t.b执行时,会调用Person类中定义的__getattribute__方法,但是在这个方法的执行过程中
#if条件不满足,所以 程序执行else里面的代码,即return self.test 问题就在这,因为return 需要把
#self.test的值返回,那么首先要获取self.test的值,因为self此时就是t这个对象,所以self.test就是
#t.test 此时要获取t这个对象的test属性,那么就会跳转到__getattribute__方法去执行,即此时产
#生了递归调用,由于这个递归过程中 没有判断什么时候推出,所以这个程序会永无休止的运行下去,又因为
#每次调用函数,就需要保存一些数据,那么随着调用的次数越来越多,最终内存吃光,所以程序 崩溃
#
# 注意:以后不要在__getattribute__方法中调用self.xxxx内建函数
map函数
map函数会根据提供的函数对指定序列做映射
map(...)
map(function, sequence[, sequence, ...]) -> list
- function:是一个函数
- sequence:是一个或多个序列,取决于function需要几个参数
- 返回值是一个list
参数序列中的每一个元素分别调用function函数,返回包含每次function函数返回值的list。
#函数需要一个参数
map(lambda x: x*x, [1, 2, 3])
#结果为:[1, 4, 9]
#函数需要两个参数
map(lambda x, y: x+y, [1, 2, 3], [4, 5, 6])
#结果为:[5, 7, 9]
def f1( x, y ):
return (x,y)
l1 = [ 0, 1, 2, 3, 4, 5, 6 ]
l2 = [ 'Sun', 'M', 'T', 'W', 'T', 'F', 'S' ]
l3 = map( f1, l1, l2 )
print(list(l3))
#结果为:[(0, 'Sun'), (1, 'M'), (2, 'T'), (3, 'W'), (4, 'T'), (5, 'F'), (6, 'S')]filter函数
filter函数会对指定序列执行过滤操作
filter(...)
filter(function or None, sequence) -> list, tuple, or string
Return those items of sequence for which function(item) is true. If
function is None, return the items that are true. If sequence is a tuple
or string, return the same type, else return a list.
- function:接受一个参数,返回布尔值True或False
- sequence:序列可以是str,tuple,list
filter函数会对序列参数sequence中的每个元素调用function函数,最后返回的结果包含调用结果为True的元素。
返回值的类型和参数sequence的类型相同
filter(lambda x: x%2, [1, 2, 3, 4])
[1, 3]
filter(None, "she")
'she'reduce函数
In [10]: from functools import reduce In [11]: reduce(lambda x, y: x+y, ['aa', 'bb', 'cc'], 'dd') Out[11]: 'ddaabbcc' In [12]: reduce(lambda x, y: x+y, [1,2,3,4], 5) Out[12]: 15
sort函数
sorted(...)
sorted(iterable, cmp=None, key=None, reverse=False) --> new sorted listIn [13]: sorted([1,5,2,3,9]) Out[13]: [1, 2, 3, 5, 9] In [14]: sorted([1,5,2,4,8],reverse=1) Out[14]: [8, 5, 4, 2, 1]
functools
partial函数
把一个函数的某些参数设置默认值,返回一个新的函数,调用这个新函数会更简单
import functools
def showLogs(*args,**kwargs):
print(args)
print(kwargs)
func1 = functools.partial(showLogs,"a","b","c")
func1()
func1(3,4,5)
func1(key1='mikejing', key2='cjj')
func2 = functools.partial(showLogs,a="iii",b="ccc")
func2()
func2(3,6)
func2(a="444",d="666")
('a', 'b', 'c')
{}
('a', 'b', 'c', 3, 4, 5)
{}
('a', 'b', 'c')
{'key1': 'mikejing', 'key2': 'cjj'}
()
{'a': 'iii', 'b': 'ccc'}
(3, 6)
{'a': 'iii', 'b': 'ccc'}
()
{'a': '444', 'b': 'ccc', 'd': '666'}
wraps函数
import functools
def note(func):
"note function"
# 不加这句话下面的test打印的是wrapper的方法,不然打印的都是正常方法
@functools.wraps(func)
def wrapper():
"wrapper function"
print("note task insert")
return func()
return wrapper
@note
def test():
"test function"
print("task1")
test()
print(test.__doc__)
# 不加
# note task insert
# task1
# wrapper function
# ***Repl Closed***
# 加
note task insert
task1
test function
***Repl Closed***
常用系统模块
| 标准库 | 说明 |
|---|---|
| builtins | 内建函数默认加载 |
| os | 操作系统接口 |
| sys | Python自身的运行环境 |
| functools | 常用的工具 |
| json | 编码和解码 JSON 对象 |
| logging | 记录日志,调试 |
| multiprocessing | 多进程 |
| threading | 多线程 |
| copy | 拷贝 |
| time | 时间 |
| datetime | 日期和时间 |
| calendar | 日历 |
| hashlib | 加密算法 |
| random | 生成随机数 |
| re | 字符串正则匹配 |
| socket | 标准的 BSD Sockets API |
| shutil | 文件和目录管理 |
| glob | 基于文件通配符搜索 |
hashlib
import hashlib
m = hashlib.md5()
print(m)
m.update("task".encode("utf-8"))
print(m.hexdigest())
<md5 HASH object @ 0x101e2f4e0>
478f3a4c51824ad23cb50c1c60670c0f
***Repl Closed***
| 扩展库 | 说明 |
|---|---|
| requests | 使用的是 urllib3,继承了urllib2的所有特性 |
| urllib | 基于http的高层库 |
| scrapy | 爬虫 |
| beautifulsoup4 | HTML/XML的解析器 |
| celery | 分布式任务调度模块 |
| redis | 缓存 |
| Pillow(PIL) | 图像处理 |
| xlsxwriter | 仅写excle功能,支持xlsx |
| xlwt | 仅写excle功能,支持xls ,2013或更早版office |
| xlrd | 仅读excle功能 |
| elasticsearch | 全文搜索引擎 |
| pymysql | 数据库连接库 |
| mongoengine/pymongo | mongodbpython接口 |
| matplotlib | 画图 |
| numpy/scipy | 科学计算 |
| django/tornado/flask | web框架 |
| xmltodict | xml 转 dict |
| SimpleHTTPServer | 简单地HTTP Server,不使用Web框架 |
| gevent | 基于协程的Python网络库 |
| fabric | 系统管理 |
| pandas | 数据处理库 |
| scikit-learn | 机器学习库 |
Python3面向对象(3)