RDBMS

RDBMS,Relational Database Management System,关系型数据库管理系统。
什么是关系型数据库,行和列组成表,表的集合就是关系型数据库,关系数据库是以数据(单元格)、关系(一对多...)、数据的约束(外键)组成的数据模型,这已经有将近50年的历史了。
关系型数据库的管理系统,其实就是管理软件,MySQL、Oracle这类的,数据是存放在操作系统的文件系统中的。
基本的sql流程是,解释 -> 优化 -> 执行
数据库主要面向的是,事务。
当复杂sql遇上当大数据量的时候,那就是Cpu和磁盘IO的挑战了。
比较深刻的是索引,可以用二叉搜索树(或者B+树)来实现,而搜索行的时候,可以使用hash桶。
但是创建太多的索引,有时反而会加重数据库的负担,因为索引是有序的,每次增删改都会导致一次排序,而最好的排序算法,只是O(Log(N)*N)。
HDFS
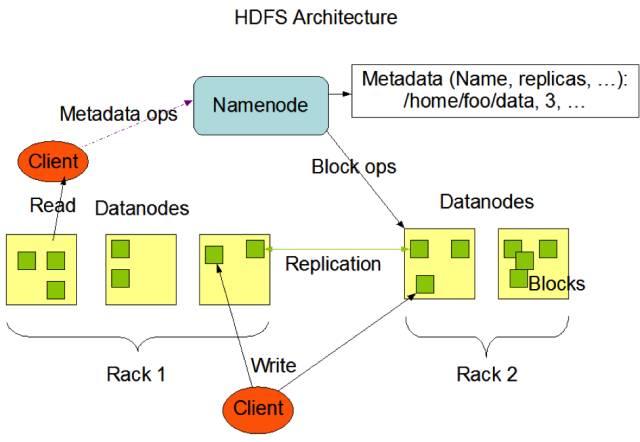
HDFS,Hadoop Distributed File System,Hadoop分布式文件系统。
这个东西就比较复杂了,它是用Java写的分布式文件系统,与Map-Reduce是Hadoop框架的一部分,是大数据处理的基础架构。
Hive

Hadoop使用Map-Reduce来计算数据,而Hive提供了类Sql的查询方式,虽然不能使用索引,导致每次查询都是暴力的全扫描,但是大数据量的并行查询,会表现的好。
它可以将metadata放在mysql,然后通过SQL引擎去HDFS中查询数据。
当然,还有Hbase,SparkSQL,后者具有更强大的一栈式处理数据能力。
数据仓库

有了以上的知识,非常清楚了一点,最需要的是一个数据仓库,因为系统运行时超过99%的数据是历史数据,不允许修改,只需要查询,而将这些数据和生产数据放在一起,势必会加大系统和数据库的负担。 火了几年的大数据,利用这些成熟的框架,可以搭建一个更强大,面向未来的架构。
理想的架构是
-
online web服务使用MySql,只保存活跃的记录和系统数据,如用户信息,当前订单
-
Data Warehouse 数据仓库,提供报表和数据分析服务,搭建好之后交给专业的数据分析师,存放不变的数据,如历史订单
因此,只需要一个Hadoop集群 + 一个Hive/SparkSQL应用。