连接查询
连接查询: 将多张表(>=2)进行记录的连接(按照某个指定的条件进行数据拼接)。
连接查询的意义: 在用户查看数据的时候,需要显示的数据来自多张表.
连接查询: join, 使用方式: 左表 join 右表;左表: 在join关键字左边的表;右表: 在join关键字右边的表
连接查询分类:SQL中将连接查询分成四类: 内连接,外连接,自然连接和交叉连接
交叉连接:交叉连接: cross join, 从一张表中循环取出每一条记录, 每条记录都去另外一张表进行匹配: 匹配一定保留(没有条件匹配), 而连接本身字段就会增加(保留),最终形成的结果叫做: 笛卡尔积。但是基本不会用到(反正我是从没有用过)
基本语法: 左表 cross join 右表 或 from 左表,右表;
内连接: [inner] join, 从左表中取出每一条记录,去右表中与所有的记录进行匹配: 匹配必须是某个条件在左表中与右表中相同最终才会保留结果,否则不保留.
基本语法:左表 [inner] join 右表 on 左表.字段 = 右表.字段; on表示连接条件: 条件字段就是代表相同的业务含义(如my_student.c_id和my_class.id)
字段别名以及表别名的使用: 在查询数据的时候,不同表有同名字段,这个时候需要加上表名才能区分, 而表名太长, 通常可以使用别名.
内连接可以没有连接条件: 没有on之后的内容,这个时候系统会保留所有结果(笛卡尔积)
内连接还可以使用where代替on关键字,但效率差很多。
外连接: 以某张表为主,取出里面的所有记录, 然后每条与另外一张表进行连接: 不管能不能匹配上条件,最终都会保留: 能匹配,正确保留; 不能匹配,其他表的字段都置空NULL.
外连接分为两种: 是以某张表为主: 有主表
left join: 左外连接(左连接), 以左表为主表
right join: 右外连接(右连接), 以右表为主表
基本语法: 左表 left/right join 右表 on 左表.字段 = 右表.字段;
自然连接:略(基本不用自然连接)
联合查询
联合查询:将多次查询(多条select语句), 在记录上进行拼接(字段不会增加)
基本语法:多条select语句构成: 每一条select语句获取的字段数必须严格一致(但是字段类型无关)
Select 语句1
Union [union选项]
Select语句2...
Union选项: 与select选项一样有两个
All: 保留所有(不管重复)
Distinct: 去重(整个重复): 默认的
联合查询只要求字段一样, 跟数据类型无关
联合查询的意义:
1. 查询同一张表,但是需求不同: 如查询学生信息, 男生身高升序, 女生身高降序.
2. 多表查询: 多张表的结构是完全一样的,保存的数据(结构)也是一样的.
Order by使用
在联合查询中: order by不能直接使用,需要对查询语句使用括号才行;另外,要orderby生效: 必须搭配limit: limit使用限定的最大数即可.
子查询
子查询: 查询是在某个查询结果之上进行的.(一条select语句内部包含了另外一条select语句).
子查询分类
子查询有两种分类方式: 按位置分类;和按结果分类
按位置分类: 子查询(select语句)在外部查询(select语句)中出现的位置
From子查询: 子查询跟在from之后
Where子查询: 子查询出现where条件中
Exists子查询: 子查询出现在exists里面
按结果分类: 根据子查询得到的数据进行分类(理论上讲任何一个查询得到的结果都可以理解为二维表)
标量子查询: 子查询得到的结果是一行一列
列子查询: 子查询得到的结果是一列多行
行子查询: 子查询得到的结果是多列一行(多行多列) (1,2,3出现的位置都是在where之后)
表子查询: 子查询得到的结果是多行多列(出现的位置是在from之后)
标量子查询
需求: 找到分类为科技的所有文章标题
列子查询
这个时候我就想起以前面试的情形,当时有一道题,给我一个表,让我找出语文和数学都及格人的名字。表是这样的:
行子查询
行子查询: 返回的结果可以是多行多列(一行多列)
需求:找出年龄最大且身高最高的人
方案一:
方案二:
表子查询
表子查询: 子查询返回的结果是多行多列的二维表: 子查询返回的结果是当做二维表来使用
需求:找出每个人最好的成绩
Exists子查询
Exists: 是否存在的意思, exists子查询就是用来判断某些条件是否满足(跨表), exists是接在where之后: exists返回的结果只有0和1.
需求:如果存在的话身高大于2米的人,列出表中所有数据
一对一关系
一对一的表关系:
例如:qq和qq的详尽信息
建立外键的时候 如果明确主从关系?
被引用的表是主表,外键在从表中建立 关联主表- 1
- 2
- 3
- 4
- 5
实现代码如下:
CREATE TABLE qq(
qqid int PRIMARY KEY,
password varchar(100)
);
CREATE TABLE qqDetail(
qqid int PRIMARY KEY,
qname varchar(50) NOT NULL,
qgender varchar(50) DEFAULT '男'
);
ALTER TABLE qqDetail ADD CONSTRAINT fk_qqDetail_qqid FOREIGN KEY(qqid) REFERENCES qq(qqid);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
多对多关系
建立多对多的关系的时候 实际上就是建立外键
明确
1.在哪张表建立外键(中间表)
2.哪个字段与哪个字段建立联系
例如:
score表的sid与student表的sid建立联系
score表的cid与course表的cid建立联系- 1
- 2
- 3
- 4
- 5
- 6
- 7
实现代码如下:
CREATE TABLE student(
sid int PRIMARY KEY,
sname varchar(50)
);
CREATE TABLE score(
sid int,
cid int,
score int,
CONSTRAINT fk_score_sid FOREIGN KEY(sid) REFERENCES student(sid),
CONSTRAINT fk_score_cid FOREIGN KEY(cid) REFERENCES course(cid)
);
CREATE TABLE course(
cid int PRIMARY KEY,
cname varchar(50)
);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
合并查询
合并查询返回的结果集字段的类型和数量一致
单独使用UNION会把两张表的数据合并 并且过滤掉相同的数据
- 1
- 2
- 3
create table A(
name varchar(10),
score int
);
create table B(
name varchar(10),
score int
);
// 插入数据
insert into A values('a',10),('b',20),('c',30);
insert into B values('a',10),('b',20),('d',40);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
SELECT name,score FROM A
UNION
SELECT * FROM B;- 1
- 2
- 3
结果: 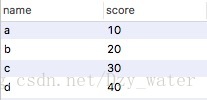
不想过滤就使用 UNION ALL
SELECT name,score FROM A
UNION ALL
SELECT * FROM B;- 1
- 2
- 3
结果:

多表查询
查询两张表(起别名)
SELECT
st.sid,
st.sname,
sc.score
FROM
student AS st,score AS sc
WHERE
st.sid = sc.sid;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
连接查询
内连接查询 相当于把两张表连接到一起查询
查询所有学生的成绩
使用INNER JOIN 关键字 条件使用 ON INNER可以省略
SELECT
*
FROM
student st
INNER JOIN
score sc
ON
st.sid = sc.sid;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
多张表(查询时 3张表2条件 n张表n-1条件)
查询所有学生的分数和考试科目
SELECT
st.sid,
sname,
score,
cname
FROM
student st
JOIN score sc ON st.sid = sc.sid
JOIN course c ON c.cid = sc.cid;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
外连接(左外连接、右外连接)
以左边的表为主 主表中的数据都会查询出来 有可能会产生无用的数据
左外连接:
SELECT
st.sid,st.sname,sc.score
FROM
student st
LEFT JOIN
score sc
ON
st.sid = sc.sid;
右外与左外连接相反
外键是约束数据的插入,与查询无关- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
自然连接
会自动帮你匹配到 表中相同字段
SELECT
*
FROM
student
NATURAL JOIN
score;
注意:没有外键也能自然查询- 1
- 2
- 3
- 4
- 5
- 6
- 7
子查询
出现多次select的查询语句
实例:
-- 雇员表:emp
CREATE TABLE emp(
empno INT,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm decimal(7,2),
deptno INT
);
INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);
INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);
INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);
INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);
INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);
INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);
INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);
INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);
INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);
-- 部门表:dept
CREATE TABLE dept(
deptno INT,
dname varchar(14),
loc varchar(13)
);
INSERT INTO dept values(10, 'ACCOUNTING', 'NEW YORK');
INSERT INTO dept values(20, 'RESEARCH', 'DALLAS');
INSERT INTO dept values(30, 'SALES', 'CHICAGO');
INSERT INTO dept values(40, 'OPERATIONS', 'BOSTON');- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
查询与scott同一个部门的员工
SELECT * FROM emp WHERE deptno=(
SELECT deptno FROM emp WHERE ename='SCOTT');- 1
- 2
工资高于30号部门所有人的员工信息
SELECT * FROM emp WHERE sal >(
SELECT MAX(sal) FROM emp WHERE deptno=30);- 1
- 2
查询工作和工资与MARTIN完全相同的员工信息
SELECT * FROM emp WHERE (job,sal) IN
(SELECT job,sal FROM emp WHERE ename='MARTIN');
注意:单个数据使用等号 多个数据一般使用IN- 1
- 2
- 3
有两个以上直接下属的员工信息
SELECT * FROM emp WHERE empno IN(
SELECT mgr FROM emp GROUP BY mgr HAVING COUNT(mgr)>=2);- 1
- 2
自连接查询
给自己这个表取个别名来使用
应用场景:当你想要的数据全在一张表里 但是一次不能查出来
7369员工编号 姓名 经理编号 经理姓名
SELECT
e1.empno,
e1.ename,
e2.mgr,
e2.ename
FROM
emp e1,
emp e2
WHERE
e1.mgr = e2.empno
AND e1.empno = 7369;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
查询返回的结果集当做一张新表去使用
各个部门薪水最高的员工所有信息
SELECT * FROM emp WHERE sal in(
SELECT MAX(sal) FROM emp GROUP BY deptno);- 1
- 2
结果: 
查询过程中出现问题 查询时没有把部门的条件带进去 只是按最高工资处理的
解决方法:
SELECT
*
FROM
emp e1,
(
SELECT
deptno,
MAX(sal) msal
FROM
emp
GROUP BY
deptno
) e2
WHERE
e1.sal = e2.msal
AND e1.deptno = e2.deptno;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
结果:

出处:https://blog.csdn.net/dzy_water/article/details/79646577