当用户登录到SQL Server后,就被指定一个缺省数据库,该缺省数据库就是Master数据库。
此时我们新建一个数据库,用来存放我们自己的数据。
单击右键,选择新建数据库
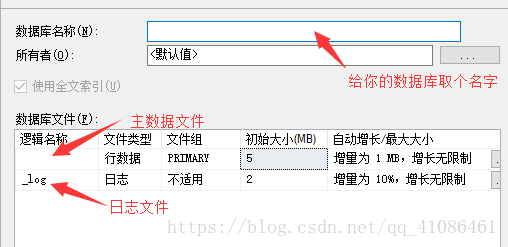
再点击右下角的确定,一个你自己的数据库就创建完成啦。当然你也可以选择初始大小和自动增长的值,我这里设置为默认。
我们需要调用自己的数据库来存放自己的数据,有两种方法:
-->可视化操作
选择你需要用的数据库就可以了
-->用use切换到需要使用的数据库
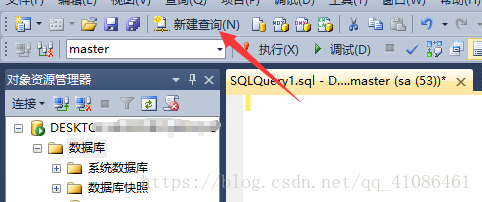
输入语句(此时还未执行该语句,显示的是master数据库)
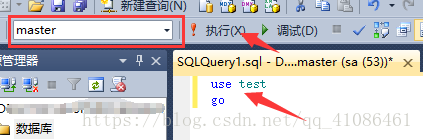
点击执行之后
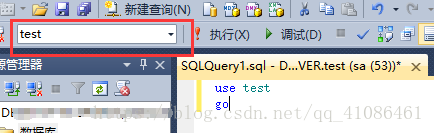
成功切换到我的test数据库。
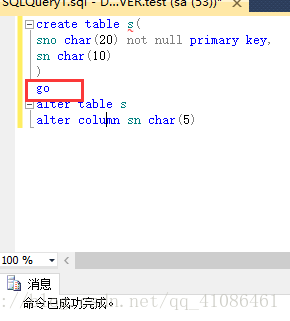
*****************************************************************************************************************************go语句:作为一个批处理执行,有一些语句不能在同一个批处理中执行,例如create和alter,当create一个表之后,用go结束当前批处理,才能继续用alter
****************************************************************************************************************************
查询
又称为检索,就是从数据库表或者视图当中快速搜索并提取我们需要的数据。
查询是对数据库其它操作(如统计、插入、删除、修改等)的基础。查询得到的数据称为查询结果数据集,简称查询数据集。
查询得到的数据集,其中的数据可以进一步进行计算、统计、汇总以及分析,最终可以按照用户的需求输出。
以下是查询命令运行的原理。
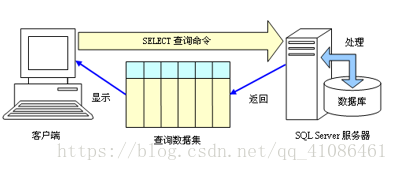
客户端请求查询,服务器处理,从数据库中查询并提取数据,再通过服务器返回到一个查询数据集,再显示给客户端,最终给用户呈现。

单表查询(只涉及一个表)
-->选择列
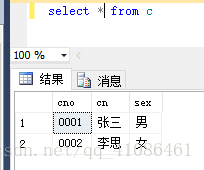
(1)全部列
输入语句,然后执行,会以表格的形式展示你所需要的数据,*是通配符,代表所有的。本例展示了c表中所有的数据
(2)指定列
由于有些重复,所以就和取别名放在一起了
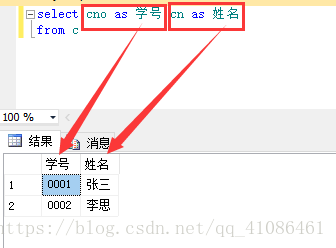
(3)取别名
如果只需要展示某一个列并且给该列取别名:
别名就是你要展现给用户看的名字,或者说取的标题,取别名并不修改数据库表中的列名,只是给用户看的时候会呈现这个名字
取别名的时候可以用as或者等于号,当你取的别名中有空格的时候,这个别名应该用单引号''括起来
(4)查询经过计算的值
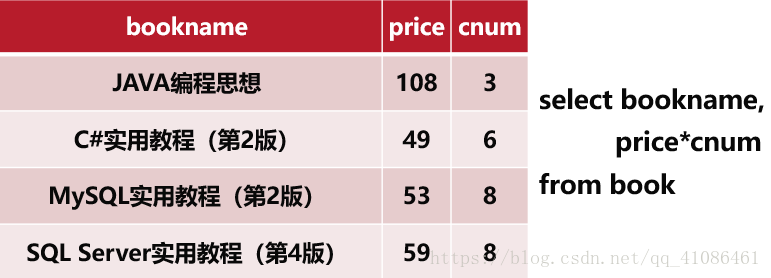
执行之后,效果如图所示
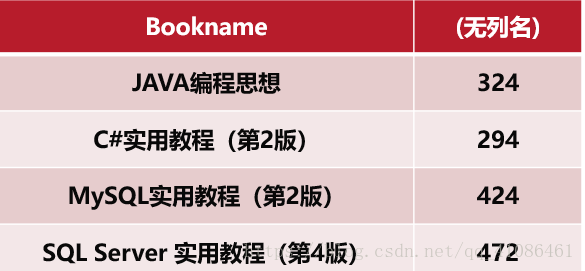
当我们给其取了一个别名之后,更加清晰明了,此时别名的作用更加体现出来了
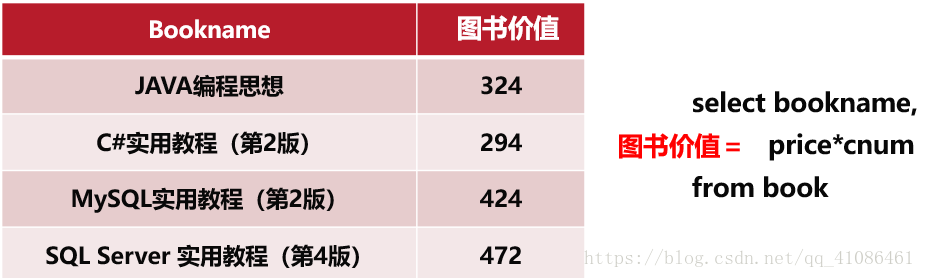
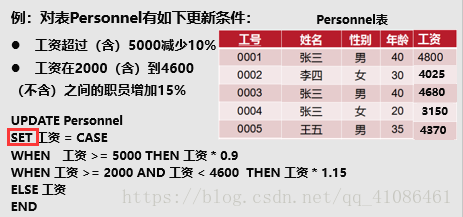
(5)替换查询结果中的数据
利用update…set…语句对查询结果进行替换,还用到了case…when…语句
update语法:update+表名set+字段(列名)+新的值
case…when…语法:(当case语句中不包含else语句的时候,如果所有的比较失败,就会返回null)

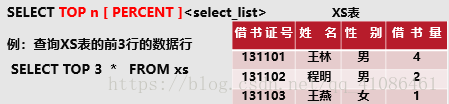
-->选择行
(6)限制结果集的返回行数
选择显示前三或者前几
(7)消除结果集中的重复行

表:
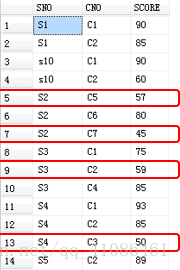
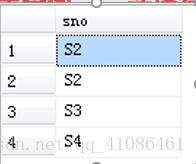
由于上表中有重复值,所以查询出来的结果有重复值
如果我们不需要显示重复值,可以列前加distinct
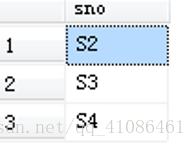
注意:当distinct缺省的时候默认为all
predicate为判定运算:可以是比较运算、指定范围、判断为空等,判定结果为true、false、unknown(null)

---1.比较运算---比较运算符有-、<、<=、>、>=、<>、!=、!<、!>
---2.指定范围---在某个范围between…and…、不在某个范围not between…and…。and之后接高值
---3.确定集合---使用in,当表达式和集合中的任意一个匹配的时候,就返回true否则返回false
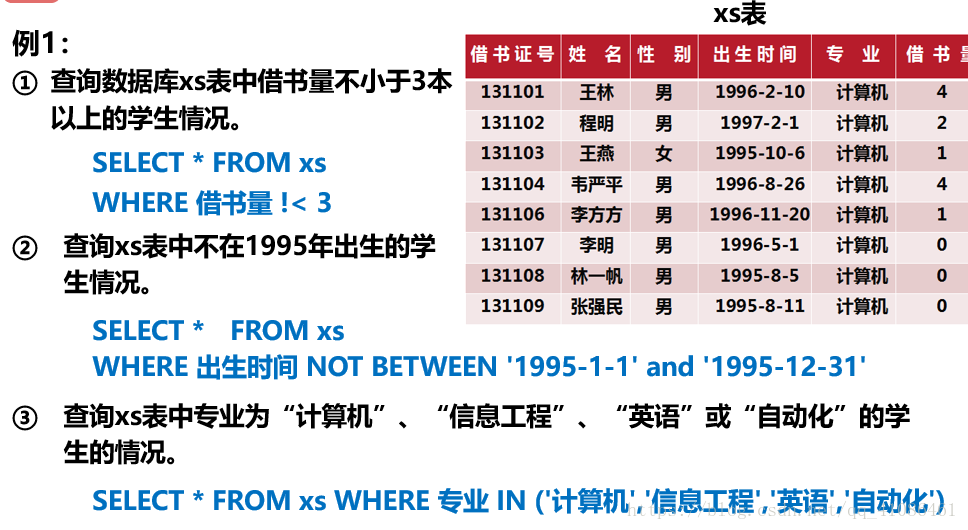
---4.模糊查询---使用like
---5.通配符---%表示任意长度的字符串,包括0,_表示任意一个字符,[]表示字符列中的任何单一字符。

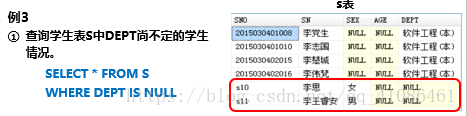
---6.---空值比较---判断一个表达式是否是空值,使用is null关键字
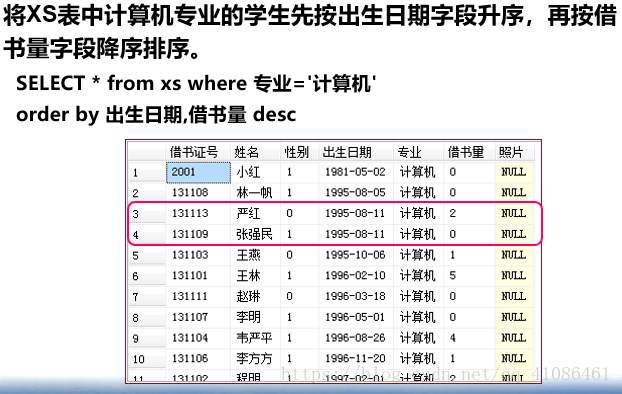
-->排序
---1.---order by子句,可以对查询结果按照一个或者多个字段进行升序或者降序的排列,如果没指明,默认为升序。
语法:
order_by_expression是排序表达式,expression可以是列名,表达式或者一个正整数,当其为正整数的时候,表示按照表中该位置上的列进行升序或者降序排序。
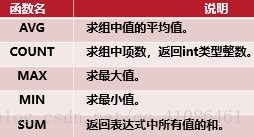
-->聚合函数

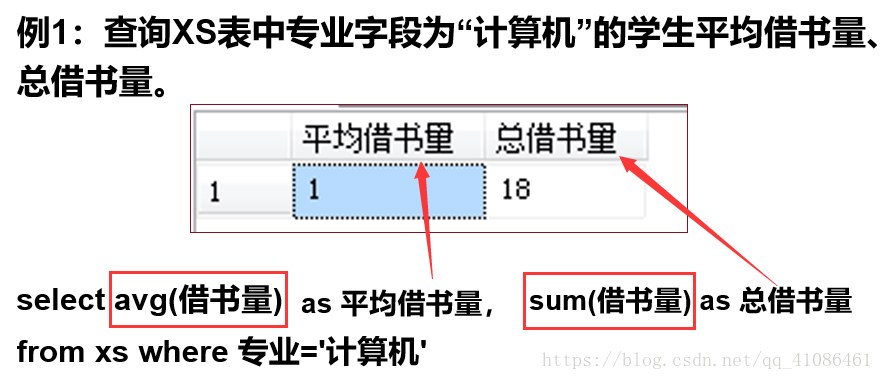
-->分组
如果要统计各个专业的平均借书量和总借书量,这就需要用到分组了。
先把数据进行分组,再通过where子句筛选得到有效的数据行,然后利用聚合函数计算统计
需要用到group by子句。
注意:select后面的字段要么是group by后面的字段,要么是通过聚合函数得到的虚拟列。

-->分组筛选
如果分组之后还需要按照一定的条件对这些数据进行筛选,就要使用having子句来指定筛选条件。

注意区别where和having:
---1.---where子句是用来指定“行”的条件,而having子句是用来指定“组”的条件
---2.---where子句中不可以使用聚合函数,而having子句可以

****************************************************************************************************************************group by,having,where,order by几个语句的执行顺序:
1.首先,where将最原始的记录中不满足条件的记录删除,可以减少分组的次数
2.然后通过group by来对其后的字段进行分组
3.接着根据having关键字筛选满足条件的记录
4.然后按照order by语句对视图进行排序,产生最终结果
(格式可以参考本文上述select语法格式)
****************************************************************************************************************************
查询数据集只是一个虚拟的表,只是以一个表的形式显示出来方便观看,实际中并不会被存储,也不会被放在缓冲区当中,所以,每次对数据库进行查询的时候都会重新从数据库表中提取数据。