详解 Kaggle 房价预测竞赛优胜方案:用 Python 进行全面数据探索
方法框架:
理解问题:查看每个变量并且根据他们的意义和对问题的重要性进行哲学分析。
单因素研究:只关注因变量( SalePrice),并且进行更深入的了解。
多因素研究:分析因变量和自变量之间的关系。
基础清洗:清洗数据集并且对缺失数据,异常值和分类数据进行一些处理。
检验假设:检查数据是否和多元分析方法的假设达到一致。
介绍:箱线图
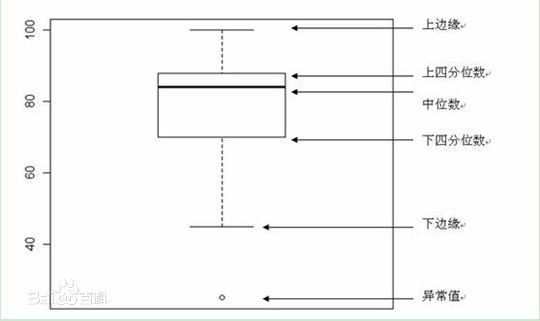
数据异常值
偏态和尾重
数据的形状
ErrorBar(误差棒图)
是统计学中常用的图形。ErrorBar图涉及到数据的“平均值”和“标准差”。
下面举例子理解误差棒图中涉及到的“平均值”和“标准差”。

某地降雨量的误差棒图[1]如图1所示,从横纵1月份的刻度值往正上查找时,可发现1月份的降雨量对应于一个“工”字型的图案。该“工”字型的图案的中间的点对应的纵轴的刻度值(大约12),表示该地1月份的降雨量的“平均值”,大约12cm。而“工”字型图案的上横线或下横线所对应的纵轴的刻度值到中间点(即均值)的差值大约为0.5,表示该地1月份的降雨量的“标准差”大约为0.5cm。

最重要的事情——分析“房价”描述性数据总结:df_train['SalePrice'].describe()
直方图
sns.distplot(df_train['SalePrice']);
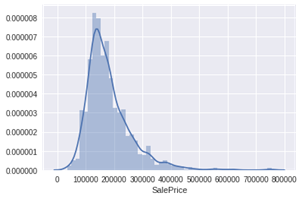
从直方图中可以看出:
·偏离正态分布
·数据正偏
·有峰值
相关变量分析:
1.散点图:数字型变量间的关系
1.‘Grlivarea’ 与 ‘SalePrice’ 散点图
var = 'GrLivArea' data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1) data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
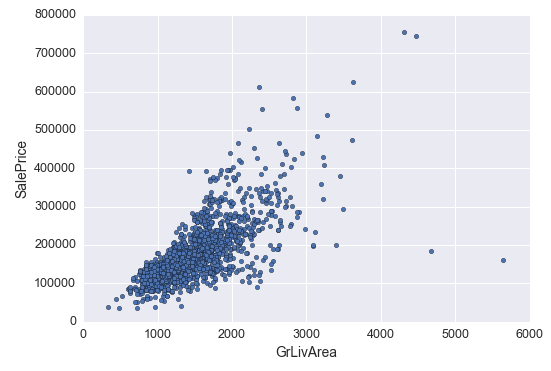
可以看出’’SalePrice’和’'GrLivArea' 关系很密切,并且基本呈线性关系。
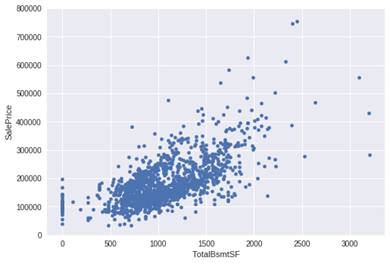
2.‘TotalBsmtSF’ 与 ‘SalePrice’散点图
var = 'TotalBsmtSF' data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1) data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
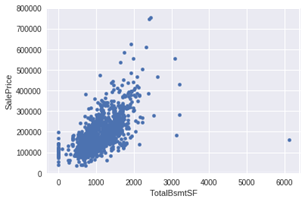
TotalBsmtSF' 和 'SalePrice'关系也很密切,从图中可以看出基本呈指数分布,但从最左侧的点可以看出特定情况下’TotalBsmtSF' 对'SalePrice' 没有产生影响。
2.箱型图:与类别型变量的关系
1.‘OverallQual’与‘SalePrice’箱型图
var = 'OverallQual' data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1) f, ax = plt.subplots(figsize=(8, 6)) fig = sns.boxplot(x=var, y="SalePrice", data=data) fig.axis(ymin=0, ymax=800000);
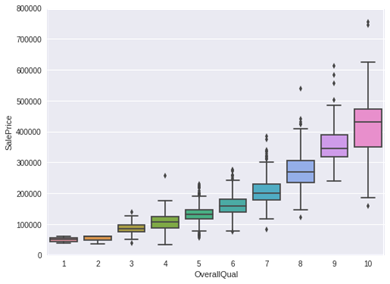
可以看出’SalePrice' 与 'OverallQual'分布趋势相同。
2.‘YearBuilt’与‘SalePrice’箱型图
var = 'YearBuilt' data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1) f, ax = plt.subplots(figsize=(16, 8)) fig = sns.boxplot(x=var, y="SalePrice", data=data) fig.axis(ymin=0, ymax=800000);plt.xticks(rotation=90);
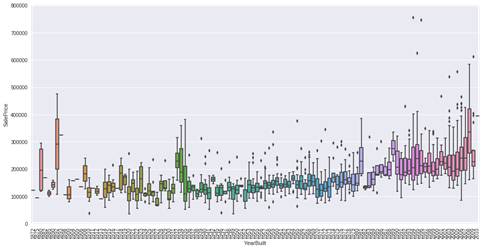
两个变量之间的关系没有很强的趋势性,但是可以看出建筑时间较短的房屋价格更高。
总结:
'GrLivArea' 和 'TotalBsmtSF' 与 'SalePrice'似乎线性相关,并且都是正相关。 对于 'TotalBsmtSF',线性关系的斜率十分的高。
·'OverallQual' 和 'YearBuilt' 与 'SalePrice'也有关系。'OverallQual'的相关性更强, 箱型图显示了随着整体质量的增长,房价的增长趋势。
3.相关系数矩阵
1.“客观分析”
观察哪些变量会和预测目标关系比较大,哪些变量之间会有较强的关联
corrmat = df_train.corr() f, ax = plt.subplots(figsize=(12, 9)) sns.heatmap(corrmat, vmax=.8, square=True);

首先两个红色的方块吸引到了我,第一个是'TotalBsmtSF' 和'1stFlrSF' 变量的相关系数,第二个是 'GarageX' 变量群。这两个示例都显示了这些变量之间很强的相关性。实际上,相关性的程度达到了一种多重共线性的情况。我们可以总结出这些变量几乎包含相同的信息,所以确实出现了多重共线性。
另一个引起注意的地方是 'SalePrice' 的相关性。我们可以看到我们之前分析的 'GrLivArea','TotalBsmtSF',和 'OverallQual'的相关性很强,除此之外也有很多其他的变量应该进行考虑,这也是我们下一步的内容。
2.'SalePrice' 相关系数矩阵 特征选择
k = 10 #number ofvariables for heatmap cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index cm = np.corrcoef(df_train[cols].values.T) sns.set(font_scale=1.25) hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values) plt.show()
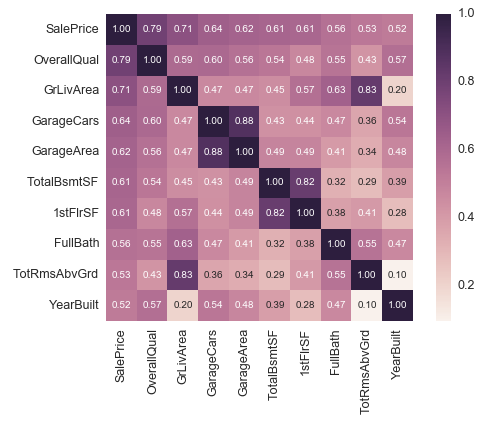
从图中可以看出:
·'OverallQual', 'GrLivArea' 以及 'TotalBsmtSF' 与 'SalePrice'有很强的相关性。
·'GarageCars' 和 'GarageArea' 也是相关性比较强的变量. 车库中存储的车的数量是由车库的面积决定的,它们就像双胞胎,所以不需要专门区分'GarageCars' 和 'GarageArea' ,所以我们只需要其中的一个变量。这里我们选择了'GarageCars'因为它与'SalePrice' 的相关性更高一些
·'TotalBsmtSF' 和 '1stFloor' 与上述情况相同,我们选择 'TotalBsmtSF' 。
·'FullBath'几乎不需要考虑。
·'TotRmsAbvGrd' 和 'GrLivArea'也是变量中的双胞胎。
·'YearBuilt' 和 'SalePrice'相关性似乎不强。
4 “缺失数据”
关于缺失数据需要思考的重要问题
·这一缺失数据的普遍性如何?
·缺失数据是随机的还是有律可循?
这些问题的答案是很重要的,因为缺失数据意味着样本大小的缩减,这会阻止我们的分析进程。除此之外,以实质性的角度来说,我们需要保证对缺失数据的处理不会出现偏离或隐藏任何难以忽视的真相。
total= df_train.isnull().sum().sort_values(ascending=False) percent = (df_train.isnull().sum()/df_train.isnull().count()).sort_values(ascending=False) missing_data = pd.concat([total, percent], axis=1, keys=['Total','Percent']) missing_data.head(20)
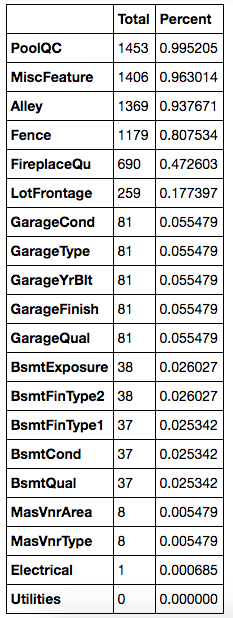
当超过15%的数据都缺失的时候,我们应该删掉相关变量且假设该变量并不存在。
根据这一条,一系列变量都应该删掉,例如'PoolQC', 'MiscFeature', 'Alley'等等,这些变量都不是很重要,因为他们基本都不是我们买房子时会考虑的因素。
'GarageX' 变量群的缺失数据量都相同,由于关于车库的最重要的信息都可以由'GarageCars' 表达,并且这些数据只占缺失数据的5%,我们也会删除上述的'GarageX' 变量群。同样的逻辑也适用于 'BsmtX' 变量群。
对于 'MasVnrArea' 和 'MasVnrType',我们可以认为这些因素并不重要。除此之外,他们和'YearBuilt' 以及 'OverallQual'都有很强的关联性,而这两个变量我们已经考虑过了。所以删除 'MasVnrArea'和 'MasVnrType'并不会丢失信息。
最后,由于'Electrical'中只有一个缺失的观察值,所以我们删除这个观察值,但是保留这一变量。
此外,我们还可以通过补充缺失值,通过实际变量的含义进行补充,例如类别型变量,就可以补充成 No,数值型变量可以补充成 0,或者用平均值来填充。
5.离群点
单因素分析
这里的关键在于如何建立阈值,定义一个观察值为异常值。我们对数据进行正态化,意味着把数据值转换成均值为0,方差为1的数据。
saleprice_scaled= StandardScaler().fit_transform(df_train['SalePrice'][:,np.newaxis]); low_range = saleprice_scaled[saleprice_scaled[:,0].argsort()][:10] high_range= saleprice_scaled[saleprice_scaled[:,0].argsort()][-10:] print('outer range (low) of the distribution:') print(low_range) print('nouter range (high) of thedistribution:') print(high_range)

进行正态化后,可以看出:
·低范围的值都比较相似并且在0附近分布。
·高范围的值离0很远,并且七点几的值远在正常范围之外。
双因素分析
1. 'GrLivArea'和'SalePrice'双因素分析
var = 'GrLivArea'
data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
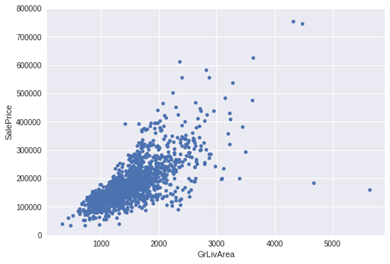
从图中可以看出:
·有两个离群的'GrLivArea' 值很高的数据,我们可以推测出现这种情况的原因。或许他们代表了农业地区,也就解释了低价。 这两个点很明显不能代表典型样例,所以我们将它们定义为异常值并删除。
·图中顶部的两个点是七点几的观测值,他们虽然看起来像特殊情况,但是他们依然符合整体趋势,所以我们将其保留下来。
删除点
df_train.sort_values(by = 'GrLivArea',ascending = False)[:2]
df_train = df_train.drop(df_train[df_train['Id'] == 1299].index)
df_train = df_train.drop(df_train[df_train['Id'] == 524].index)
2. 'TotalBsmtSF'和'SalePrice'双因素分析
var = 'TotalBsmtSF'
data = pd.concat([df_train['SalePrice'],df_train[var]], axis=1)
data.plot.scatter(x=var, y='SalePrice',ylim=(0,800000));
核心部分
“房价” 到底是谁?
这个问题的答案,需要我们验证根据数据基础进行多元分析的假设。
我们已经进行了数据清洗,并且发现了 SalePrice 的很多信息,现在我们要更进一步理解 SalePrice 如何遵循统计假设,可以让我们应用多元技术。
应该测量 4 个假设量:
-
正态性
-
同方差性
-
线性
-
相关错误缺失
正态性:
应主要关注以下两点:
-
直方图 – 峰度和偏度。
-
正态概率图 – 数据分布应紧密跟随代表正态分布的对角线。
之后内容请看顶部链接