你想要多大的成功, 你愿意为这份成功付出什么?
https://blog.csdn.net/sinat_26342009/article/details/46420269 另一种资源
DQL数据库查询
* 查询会产生一张新表, 因而不会改变原来的表;
* 关键词 select
* 注意: 从数据库查询信息, 不会改变数据库中标的数据;
*
*
*
* 1. select*from 表名;(*代表所有字段)
* 1. 只查询表中sname字段
* select name from stu
*
* 2.查询表中 sname 和 sid字段;
* select sname,sid from stu
* 注意;从数据库出巡信息, 不会改变数据库中的数据;
* 查询会产生一张新的表, 从原来的那个表中查出来;
*
* 2. 关键词查询,where之后; = !=, <> (不等于), <,<=,>,>=;
* 2.0 in();
* 2.1 between A and B; 在什么范围之内,并且包括这个范围;
* 2.2 is null; ( 判断为空) ; is not null(判断不为空)
* not null
* 逻辑运算符;
* 2.3 and; 与
* 2.4 or;或
* 2.5 not; 非
* 2.6 in(); 在什么范围中查询;
* 2.7 not in(); 不在什么范围中;
*
* 2 : 格式: select * from stu where 条件;
*
2.2 查询性别为女,并且年龄50的记录
2.3 查询学号为S_1001,或者姓名为liSi的记录
select*from stu where sname='liSi' or sid='S_1001'
2.4 查询学号为S_1001,S_1002,S_1003的记录(可以用or或者in)
select*from stu where sid='s_1001' or sid='s_1002' or sid='s_1003';
select *from stu where sid in('s_1001','s_1002','s_1003');
2.5 查询学号不是S_1001,S_1002,S_1003的记录
select *from stu where sid not in('s_1001','s_1002','s_1003');
2.6 查询年龄为null的记录
select*from stu where age is null; ( 查null必须用is null);
2.7 查询年龄在20到40之间的学生记录(包括20和40)
select * from stu where age between 25 and 65;
2.8 查询性别非男的学生记录(注意: is not 查询的是空值, 不要和not(非)搞混了)
select *from stu where gender!='male';
select*from stu where not gender='male';
2.9 查询姓名不为null的学生记录
select *from stu where age is not null;
select *from stu where not age is null;
3 : 字段控制查询;
1. 去重重复记录;
*/
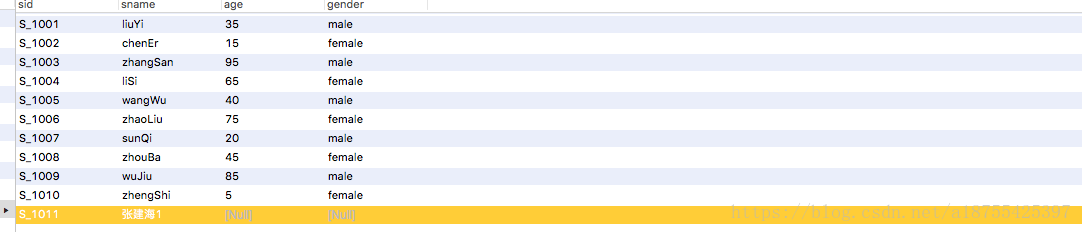
创建两张表 , 表名分别是 emp 和 stu;
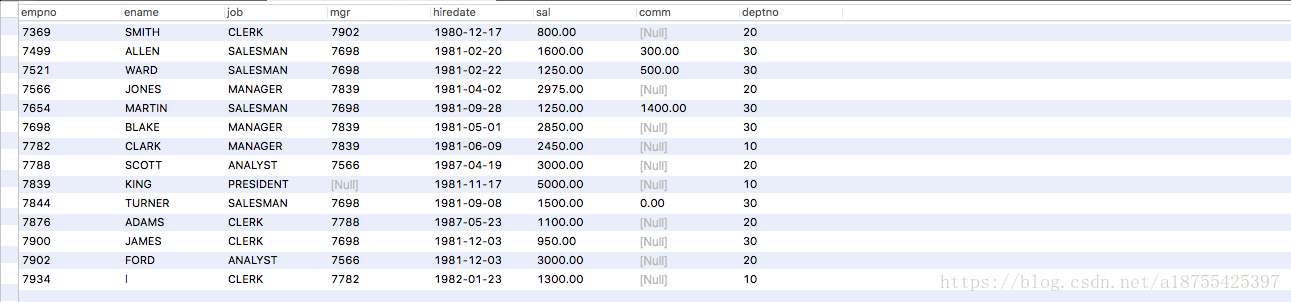
1. 去除重复数据: distinct
select distinct sal from emp ;
2. 查看两列总和, 例如 sal 和 comm 列 ;---相当于创建一个新的字段,在后面再加一列( sal + comm); 值+null = null;
select empno , sal+ Ifnull( comm,0) from emp ;
3. 使用 as 关键词, 给字段进行起小名,
select empno , sal+ Ifnull( comm,0) as total from emp ;
4.排序 : order by: asc 是升序, desc 是降序, 注意: sql语句 的关键词不能和表名重复; 按照学生年龄降序;
select * from stu order by age desc;
查询所有 ,按月薪降序, 月薪相同时, 按照编号: select * from order by sal desc, empno desc ;
5.模糊查询: 查询名字中 带 l 的所有信息; %代表位置, l% 以l 开头; %l l 结尾; %代表多个字母, _ 下划线只代表一个;
select * from emp where ename like '%l';
2 聚合函数; sum , avg max min ,count , 都可自动过滤null值;
1 .count 记录数;
1. count 查询一共有多少条记录, 获取总记录数;
select count (* ) from emp;
2. 查询 工资sal 的总和总的列数:( 查询时候字段的 记录数要相同);
select count ( sal ) from emp;
3. 查询 emp 表中 有奖金的人的个数;
select count ( comm) from emp;
4, 查询emp表中 月薪大于 2500人的个数, 自动过滤掉空值;
select count( sal) from where sal>2500;
5. 统计月薪和奖金之和大于2500的人数; 1个数+null 还是null
select count(*) from emp where sal +ifnull( comm, 0 )>2500;
6. 查询有佣金的,和有领导的人的个数;
select count(comm),count( mgr ) from emp;
2: 求和 用sum; 用来求1列的和;
1. 分别查询薪资和奖金的和;
select sum( sal), sum( comm) from emp;
2. 查询所有的月薪+佣金的和;
select sum ( sal+ifnull(comm , 0 ) from emp;
3: 求平均数; avg
1. 查询所有员工的月薪平均值;
select avg(sal) from emp;
4.查询 最高和最低; max min ;
1. 找出员工月薪最高工资和最低工资;
select max(sal),min (sal) from emp;
5 分组查询 group by
1. 查询每个部门编号和每个部门的工资和; 先分组再进行查询;
分组查询, group by 后面的字段 ,是要进行分组的字段, by 后面填啥,*就换成啥;
select deptno sum(sal) from emp group by deptno;
2. 查询每个部门的部门编号, 以及每个部门的人数;
select deptno , count(*) from emp group by deptno;
3. 查询每个部门的部门编号, 以及没给部门人数 大于1500 的人数;
先筛选, 再分组;
select count(*) , deptno from emp where sal >1500 group by deptno;
4. 查询工资总和大于9000的部门; 先分组 在加条件;
select deptno , sum(sal) from group by deptno having sum( sal)>9000;
6. 分页查询. limit 关键词; limit( 参数1, 参数2) 参数1. 数据开始的位置, 参数2 一共查询了几条;
条件: 经典应用 ( limit( 当前页-1 )*每页总数 ,每页总数) ; 例如查询三条数据;
select * from emp limit ( 3, 3);
7. 数据的完整性
1. 实体完整性: 一条记录, 就是一个实体;
主键约束 primary key : 1. 该字段值唯一, 2. 不为空;
每张表都添加一个主键, 主键删除精准;
一 : 创建方式1: 创建一张表一Id为主键;
1. create table stu1( sid int primary key, sname varchar(100) );
2. create table stu2 ( sid int, sname varchar(10) , primary key( sid ));
二 : 创建方式2: 当两个字段都是作为 主键时候,只有两个都重复才算是重复的;
1, create table stu3 ( sid int, sname varchar(10) , primary key ( sid, sname) );
三 : 创建方式三, 先把表创建出来, 在进行主键约束
1. create table stu4( sid int , sname varchar(10);
alter table stu4 add constraint primary key (sid);
2. 删除主键约束
alter table stu4 drop primary key;
唯一约束 : unique 值唯一,但是可以为null; unique 解释: 独一无二的;
create table stu5( sid int primary key , sname varchar(10) unique ) ;
自动增长: 特点 自动加1 , 比较常用 auto_ increment;
create table stu6( int sid primary key auto_increment, sname varchar(10) unique);
特点: 1. 插入唯一的值
insert into stu6 (sname ) value ('haha');
2. 域完整性: 限制单元格错误; 字段里面填的值,不能为null;
create table stu7 (sid int primary key auto_increment, sname varchar(20) not null);
3: 可以增加默认值:
create table stu8 ( sid int primary key auto_increment ,sname varchar(20) not null,
gender varchar(10) default '男'
);
3. 引用约束: (参照物约束)
1. 主表和从表有依赖关系2. 从表依赖主表 3. 这时可以给从表添加一个约束, 叫外键约束;
---主表
create table student ( sid int primary key , sname varchar(10) );
---从表
create table score1 ( sid int , score int ,
constraint fk_stu_score_sid foreign key (sid) references student(sid );
constraint : 约束的意思; foreign :不相关的, 外国的, references 附 ...以参考; 依靠;