python和C++一样,支持多继承。概念虽然容易,但是困难的工作是如果子类调用一个自身没有定义的属性,它是按照何种顺序去到父类寻找呢,尤其是众多父类中有多个都包含该同名属性。
- class P1 #(object):
- def foo(self):
- print 'p1-foo'
- class P2 #(object):
- def foo(self):
- print 'p2-foo'
- def bar(self):
- print 'p2-bar'
- class C1 (P1,P2):
- pass
- class C2 (P1,P2):
- def bar(self):
- print 'C2-bar'
- class D(C1,C2):
- pass
对经典类和新式类来说,属性的查找顺序是不同的。现在我们分别看一下经典类和新式类两种不同的表现
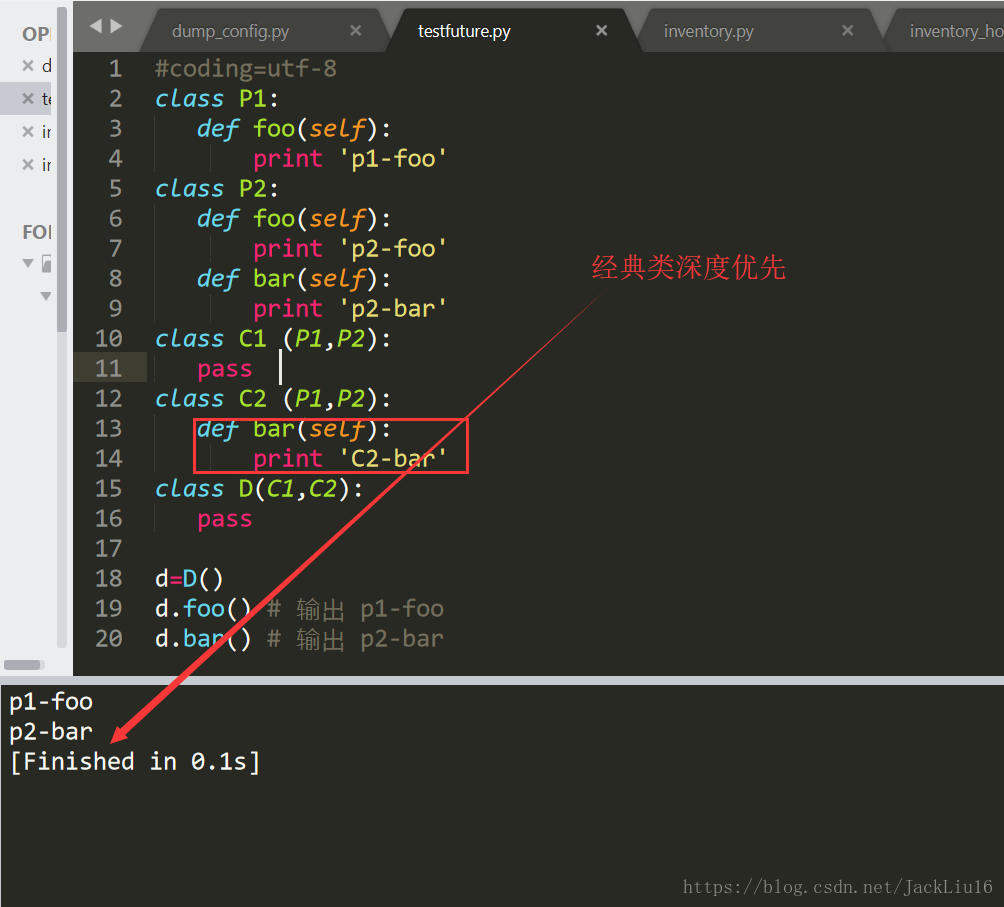
1、经典类
- d=D()
- d.foo() # 输出 p1-foo
- d.bar() # 输出 p2-bar
实例d调用foo()时,搜索顺序是 D => C1 => P1
实例d调用bar()时,搜索顺序是 D => C1 => P1 => P2
换句话说,经典类的搜索方式是按照“从左至右,深度优先”的方式去查找属性。d先查找自身是否有foo方法,没有则查找最近的父类C1里是否有该方法,如果没有则继续向上查找,直到在P1中找到该方法,查找结束。
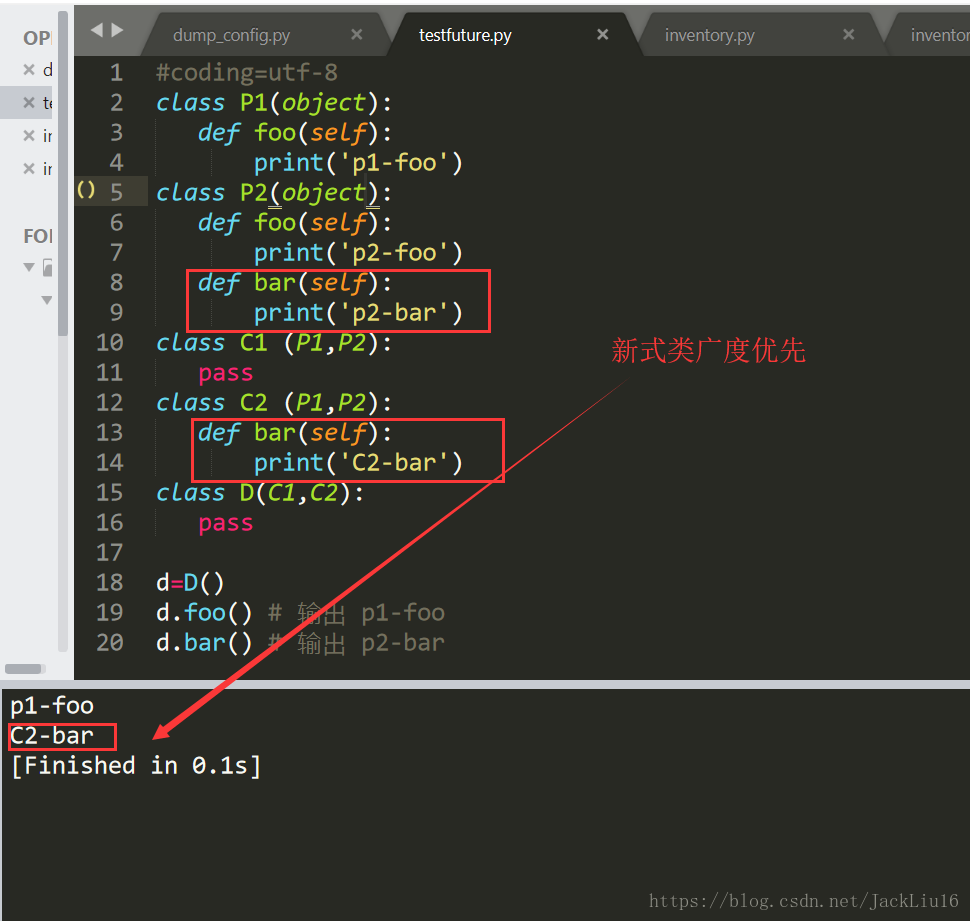
2、新式类
使用新式类要去掉第一段代码中的注释
- d=D()
- d.foo() # 输出 p1-foo
- d.bar() # 输出 c2-bar
实例d调用foo()时,搜索顺序是 D => C1 => C2 => P1
实例d调用bar()时,搜索顺序是 D => C1 => C2
可以看出,新式类的搜索方式是采用“广度优先”的方式去查找属性。
在python3中类已经添加(object)
出处:https://www.cnblogs.com/linyawen/archive/2012/04/25/2469538.html
补充:
从Python2.2开始,Python 引入了 new style class(新式类)
新式类跟经典类的差别主要是以下几点:
新式类对象可以直接通过__class__属性获取自身类型:type
- # -*- coding:utf-8 -*-
- class E:
- #经典类
- pass
- class E1(object):
- #新式类
- pass
- e = E()
- print "经典类"
- print e
- print type(e)
- print e.__class__
- print "新式类"
- e1 = E1()
- print e1
- print e1.__class__
- print type(e1)
- 经典类
- <__main__.E instance at 0x0000000002250B08>
- <type 'instance'>
- __main__.E
- 新式类
- <__main__.E1 object at 0x0000000002248710>
- <class '__main__.E1'>
- <class '__main__.E1'>
我使用的是python 2.7。
E1是定义的新式类。那么输输出e1的时候,不论是type(e1),还是e1.__class__都是输出的<class '__main__.E1'>。
2. 继承搜索的顺序发生了改变,经典类多继承属性搜索顺序: 先深入继承树左侧,再返回,开始找右侧;新式类多继承属性搜索顺序: 先水平搜索,然后再向上移动
- # -*- coding:utf-8 -*-
- class A(object):
- """
- 新式类
- 作为所有类的基类
- """
- def foo(self):
- print "class A"
- class A1():
- """
- 经典类
- 作为所有类的基类
- """
- def foo(self):
- print "class A1"
- class C(A):
- pass
- class C1(A1):
- pass
- class D(A):
- def foo(self):
- print "class D"
- class D1(A1):
- def foo(self):
- print "class D1"
- class E(C, D):
- pass
- class E1(C1, D1):
- pass
- e = E()
- e.foo()
- e1 = E1()
- e1.foo()
输出
- class D
- class A1
因为A新式类,对于继承A类都是新式类,首先要查找类E中是否有foo(),如果没有则按顺序查找C->D->A。它是一种广度优先查找方式。

因为A1经典类,对于继承A1类都是经典类,首先要查找类E1中是否有foo(),如果没有则按顺序查找C1->A1->D1。它是一种深度优先查找方式。

3. 新式类增加了__slots__内置属性, 可以把实例属性的种类锁定到__slots__规定的范围之中。
比如只允许对A实例添加name和age属性:
- # -*- coding:utf-8 -*-
- class A(object):
- __slots__ = ('name', 'age')
- class A1():
- __slots__ = ('name', 'age')
- a1 = A1()
- a = A()
- a1.name1 = "a1"
- a.name1 = "a"
A是新式类添加了__slots__ 属性,所以只允许添加 name age
A1经典类__slots__ 属性没用,
- Traceback (most recent call last):
- File "t.py", line 13, in <module>
- a.name1 = "a"
- AttributeError: 'A' object has no attribute 'name1'
所以a.name是会出错的
通常每一个实例都会有一个__dict__属性,用来记录实例中所有的属性和方法,也是通过这个字典,可以让实例绑定任意的属性
而__slots__属性作用就是,当类C有比较少的变量,而且拥有__slots__属性时,
类C的实例 就没有__dict__属性,而是把变量的值存在一个固定的地方。如果试图访问一个__slots__中没有
的属性,实例就会报错。这样操作有什么好处呢?__slots__属性虽然令实例失去了绑定任意属性的便利,
但是因为每一个实例没有__dict__属性,却能有效节省每一个实例的内存消耗,有利于生成小而精
干的实例。
4. 新式类增加了__getattribute__方法
- class A(object):
- def __getattribute__(self, *args, **kwargs):
- print "A.__getattribute__"
- class A1():
- def __getattribute__(self, *args, **kwargs):
- print "A1.__getattribute__"
- a1 = A1()
- a = A()
- a.test
- print "========="
- a1.test
- A.__getattribute__
- =========
- Traceback (most recent call last):
- File "t.py", line 18, in <module>
- a1.test
- AttributeError: A1 instance has no attribute 'test'
可以看出A是新式类,每次通过实例访问属性,都会经过__getattribute__函数,
A1不会调用__getattribute__所以出错了
Python 2.x中默认都是经典类,只有显式继承了object才是新式类
Python 3.x中默认都是新式类,不必显式的继承object
出处:https://blog.csdn.net/u010066807/article/details/46896835