背景:
我们对数据库操作时常常有这种需求:如果不存在该记录则新增,存在则更新!
传统的思路:先select判断是否存在,再选择insert或者update,这样的话步骤较多。
为了解决这种需求,mysql提供了两种常用的关键字方法:replace into 与 insert into … on duplicate key update,现在我们测试下这两种方法吧!
一、replace into 测试分析
介绍:
replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。
准备测试表:
CREATE TABLE `customer` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`phone` varchar(20) DEFAULT NULL,
`data` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8注:id字段为自增主键
插入基础数据:
INSERT INTO customer(NAME,phone,DATA) VALUES("小一","17610111111","1")
INSERT INTO customer(NAME,phone,DATA) VALUES("小二","17610111112","2")
测试1: replace into 一条数据(不含主键)
REPLACE INTO customer(NAME,phone,DATA) VALUES("小三","17610111113","3")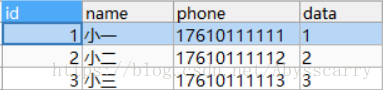
结论:由于插入数据不包含主键或唯一索引,则判断该条数据不存在,此时效果等同于insert into
测试2: replace into 一条数据(含主键)
REPLACE INTO customer(id,NAME,phone,DATA) VALUES(2,"小四","17610111114","4")
注:共2行收到影响,即先删除再新增!
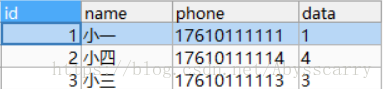
结论: 插入数据中存在已存在主键:id=2,则判断该条数据已存在,故先删除再新增(即更新)
测试3: replace into 的数据中减少一个字段:data
REPLACE INTO customer(id,NAME,phone) VALUES(2,"小五","17610111115")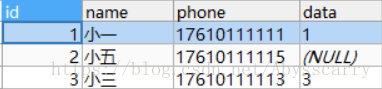
结论: replace into 的数据中如果比原数据少字段,则该字段更新时恢复为默认值(此处默认为NULL)。故可以确定replace into 删除已存在记录时,很彻底,没有做备份,之后直接新增replace into 后面确定的数据,没有值的字段设为默认值。
注:这点就和 insert into … on duplicate key update 不同了!
测试4: insert into 2条数据,看主键id是否有变化
INSERT INTO customer(NAME,phone,DATA) VALUES("小六","17610111116","6")
INSERT INTO customer(NAME,phone,DATA) VALUES("小七","17610111117","7")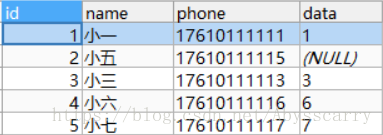
结论: 虽然第二条记录做了2次 replace into 操作,但后面新增数据时主键id 并没有+1,那问题来了,网上说的主键+1是什么时候发生的呢?
测试5: 我们将name字段设置 unique索引,再replace into
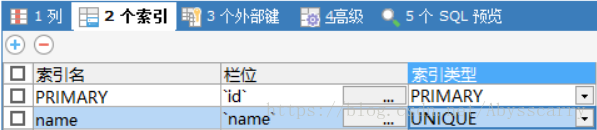
这次语句中没有涉及主键id,为了判断记录存在性,所以我们为name设置了unique索引(此时根据name判断记录是否存在)
REPLACE INTO customer(NAME,phone,DATA) VALUES("小七","17610111118","8")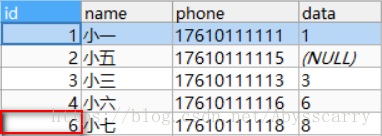
结论: 上一个测试主键没有变化的原因是我们在replace into 的数据中设置了确切的主键(相当于固定住了),而现在我们没有设置主键,故主键自增+1,此处需要注意!
测试6: 为name + phone字段设置 unique联合索引(后面测试都这样设置)
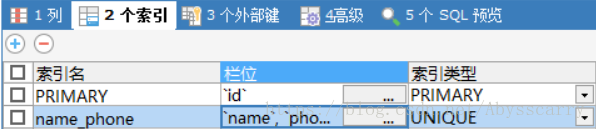
此时是根据 name + phone判断记录存在性!
REPLACE INTO customer(NAME,phone,DATA) VALUES("小七","17610111119","9")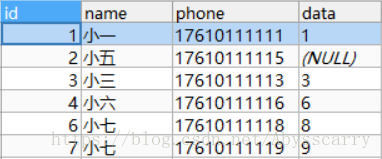
REPLACE INTO customer(NAME,phone,DATA) VALUES("小七","17610111119","10")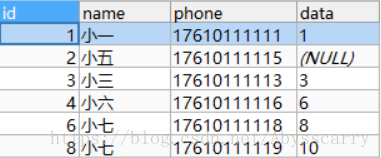
结论: 此时存在,故更新data(9 -> 10),同时主键id也+1
测试7: 在name+phone为联合索引情况下去除phone字段再replace into
REPLACE INTO customer(NAME,DATA) VALUES("小七","11")
REPLACE INTO customer(NAME,DATA) VALUES("小七","11")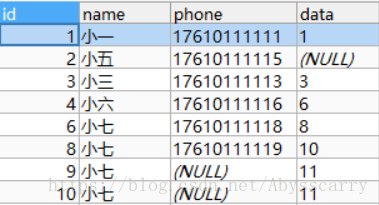
结论: 由于没加phone字段,数据库无法判断存在性,故默认不存在,即新增2条记录,phone默认为NULL。
此处特别说明:在MYSQL中UNIQUE索引将会对null字段失效,故这两条记录能同时存在不报错!
二、insert into … on duplicate key update 测试分析
注:接着上面的测试继续
测试8:
INSERT INTO customer(NAME,phone,DATA) VALUES("小八","17610111118","8") ON DUPLICATE KEY UPDATE DATA = "88"
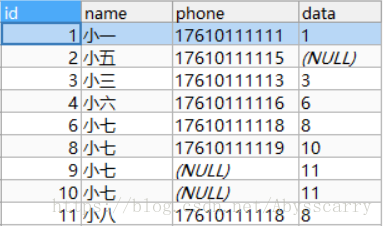
结论:此时根据 name + phone 判断出数据库不存在该记录,故新增,等同于直接 insert into,ON DUPLICATE KEY UPDATE DATA = "88" 无效!
测试9:
INSERT INTO customer(NAME,phone,DATA) VALUES("小八","17610111118","9") ON DUPLICATE KEY UPDATE DATA = "99"
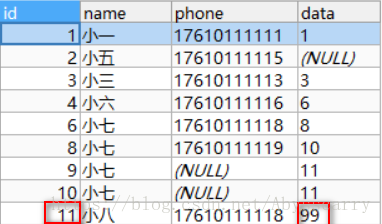
结论: 此时判断存在,更新data数据为99,这个没啥问题。但和replace into 不同的是,主键id竟然没有+1,依旧是11…
测试10: 简单insert into,接着上面测试主键+1问题
INSERT INTO customer(NAME,phone,DATA) VALUES("小九","17610111119","9")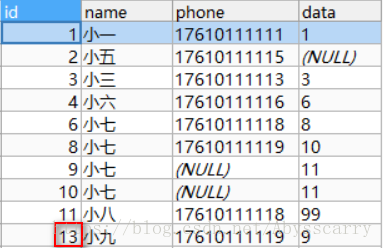
结论: 发现这里新增时,主键id才额外+1,这一点确实和replace into 不一样,可以和之前的测试对比看下!
测试11: 继续测试主键+1问题
INSERT INTO customer(id,NAME,phone,DATA) VALUES("13","小九","17610111119","10") ON DUPLICATE KEY UPDATE DATA = "100"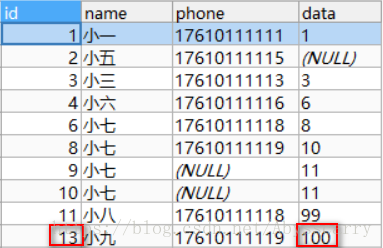
INSERT INTO customer(NAME,phone,DATA) VALUES("小十","17610111110","10")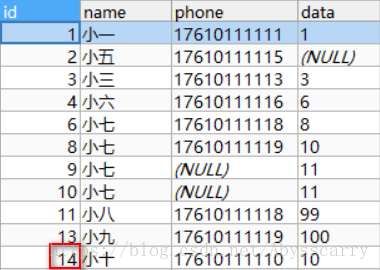
结论: 如果新增数据中设置了确切的主键,则再insert into 时主键并没有额外+1
三、结论
区别 1:(主要)
insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace into没有保留旧值,直接删除再insert新值。
从底层执行效率上来讲,replace into要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
区别 2:
两个主键自增的场景有稍许不同,详情见以上测试