
了解如何可视化 MySQL 连接的内存使用情况。
作者:Benjamin Dicken
本文和封面来源:https://planetscale.com/blog/,爱可生开源社区翻译。
本文约 3000 字,预计阅读需要 10 分钟。
引言
在考虑任何软件的性能时,时间和空间之间都存在一个典型的权衡。 在评估 MySQL 查询性能的过程中,我们经常关注执行时间(或查询延迟)并将其作为查询性能的主要指标。 这是一个很好使用的指标,因为最终我们希望尽快获得查询结果。
我最近发布了一篇关于《如何识别和分析有问题的 MySQL 查询》 的博客文章,其中讨论的重点是衡量执行时间和行读取方面的不良性能。 然而,在这次讨论中,内存消耗很大程度上被忽略了。
尽管可能并不经常需要,但 MySQL 还具有内置机制,可以深入了解查询使用了多少内存以及该内存的用途。 让我们深入研究一下这个功能,看看如何实时监控 MySQL 连接的内存使用情况。
内存统计
在 MySQL 中,系统中有许多组件可以单独检测。 该 performance_schema.setup_instruments 表列出了每个组件,数量相当多:
SELECT count(*) FROM performance_schema.setup_instruments;
+----------+
| count(*) |
+----------+
| 1255 |
+----------+
此表中包含许多可用于内存分析的工具。 要查看可用的内容,请尝试从表中进行选择并按 进行过滤 memory/。
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%';
您应该会看到数百个结果。 其中每一个都代表不同类别的内存,可以在 MySQL 中单独检测。 其中一些类别包含一小段 documentation 描述该内存类别代表或用途的内容。 如果您只想查看具有非空值的内存类型 documentation,您可以运行:
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory/%'
AND documentation IS NOT NULL;
这些内存类别中的每一个都可以以几种不同的粒度进行采样。 不同级别的粒度存储在多个表中:

SELECT table_name
FROM information_schema.tables
WHERE table_name LIKE '%memory_summary%'
AND table_schema = 'performance_schema';
+-----------------------------------------+
| TABLE_NAME |
+-----------------------------------------+
| memory_summary_by_account_by_event_name |
| memory_summary_by_host_by_event_name |
| memory_summary_by_thread_by_event_name |
| memory_summary_by_user_by_event_name |
| memory_summary_global_by_event_name |
+-----------------------------------------+
- memory_summary_by_account_by_event_name:根据帐户汇总内存事件(帐户是用户和主机的组合)
- memory_summary_by_host_by_event_name:以主机粒度汇总内存事件
- memory_summary_by_thread_by_event_name:以 MySQL 线程粒度汇总内存事件
- memory_summary_by_user_by_event_name:以用户粒度汇总内存事件
- memory_summary_global_by_event_name:内存统计的全局汇总
请注意,没有针对每个查询级别的内存使用情况进行特定跟踪。 但是,这并不意味着我们无法分析查询的内存使用情况! 为了实现这一点,我们可以监视正在执行感兴趣的查询的任何连接上的内存使用情况。 因此,我们将重点使用表 memory_summary_by_thread_by_event_name,因为 MySQL 连接和线程之间有一个方便的映射。
查找连接的用途
此时,您应该在命令行上设置两个与 MySQL 服务器的单独连接。 第一个是执行您想要监视内存使用情况的查询的查询。 第二个将用于监控目的。
在第一个连接上,运行这些查询以获取连接 ID 和线程 ID。
SET @cid = (SELECT CONNECTION_ID());
SET @tid = (SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=@cid);
然后获取这些值。 当然,您的看起来可能与您在这里看到的不同。
SELECT @cid, @tid;
+------+------+
| @cid | @tid |
+------+------+
| 49 | 89 |
+------+------+
接下来,执行一些您想要分析内存使用情况的长时间运行的查询。 对于此示例,我将从包含 1 亿行的表中执行一个大型操作,这应该需要一段时间,因为在 alias 列上 SELECT 没有索引:
SELECT alias FROM chat.message ORDER BY alias DESC LIMIT 100000;
现在,在执行过程中,切换到另一个控制台连接并运行以下命令,将线程 ID 替换为您的连接中的线程 ID:
SELECT
event_name,
current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = YOUR_THREAD_ID
ORDER BY current_number_of_bytes_used DESC
您应该看到与此类似的结果,尽管详细信息很大程度上取决于您的查询和数据:
+---------------------------------------+------------------------------+
| event_name | current_number_of_bytes_used |
+---------------------------------------+------------------------------+
| memory/sql/Filesort_buffer::sort_keys | 203488 |
| memory/innodb/memory | 169800 |
| memory/sql/THD::main_mem_root | 46176 |
| memory/innodb/ha_innodb | 35936 |
...
这指示执行此查询时每个类别正在使用的内存量。 如果在执行另一个 SELECT alias... 查询时多次运行此查询,您可能会看到结果有所不同,因为查询的内存使用量在其整个执行过程中不一定是恒定的。 该查询的每次执行都代表某个时刻的一个样本。 因此,如果我们想了解使用情况如何随时间变化,我们需要采集许多样本。
memory/sql/Filesort_buffer::sort_keys 表中的 documentation 缺少 performance_schema.setup_instruments 。
SELECT name, documentation
FROM performance_schema.setup_instruments
WHERE name LIKE 'memory%sort_keys';
+---------------------------------------+---------------+
| name | documentation |
+---------------------------------------+---------------+
| memory/sql/Filesort_buffer::sort_keys | <null> |
+---------------------------------------+---------------+
然而,该名称表明它是用于对文件中的数据进行排序的内存。 这是有道理的,因为此查询的大部分费用将用于对数据进行排序,以便可以按降序显示。
随着时间的推移收集使用情况
下一步,我们需要能够对一段时间内的内存使用情况进行采样。 对于短查询,这不会那么有用,因为我们只能执行此查询一次,或者在执行分析查询时执行少量次。 这对于运行时间较长的查询(需要数秒或数分钟的查询)更有用。 无论如何,这些都是我们想要分析的查询类型,因为这些查询可能会使用大部分内存。
这可以完全用 SQL 实现并通过存储过程调用。 然而,在这种情况下,我们使用 Python 中的单独脚本来提供监控。
#!/usr/bin/env python3
import time
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY current_number_of_bytes_used DESC LIMIT 4
'''
parser = argparse.ArgumentParser()
parser.add_argument('--thread-id', type=int, required=True)
args = parser.parse_args()
dbc = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
c = dbc.cursor()
ms = 0
while(True):
c.execute(MEM_QUERY, (args.thread_id,))
results = c.fetchall()
print(f'\n## Memory usage at time {ms} ##')
for r in results:
print(f'{r[0][7:]} -> {round(r[1]/1024,2)}Kb')
ms+=250
time.sleep(0.25)
这是对此类监控脚本的简单首次尝试。 总之,此代码执行以下操作:
- 通过命令行获取要监控的提供的线程 ID
- 设置与 MySQL 数据库的连接
- 每 250 毫秒执行一次查询以获取使用最多的 4 个内存类别并打印读数
这可以根据您的分析需求以多种方式进行调整。 例如,调整对服务器的 ping 频率或更改每次迭代列出的内存类别数量。 在执行查询时运行此命令会提供如下结果:
...
## Memory usage at time 4250 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4500 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 4750 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
## Memory usage at time 5000 ##
innodb/row0sel -> 25.22Kb
sql/String::value -> 16.07Kb
sql/user_var_entry -> 0.41Kb
innodb/memory -> 0.23Kb
...
这很棒,但有一些弱点。 很高兴看到超过前 4 个内存使用类别的内容,但增加该数字会增加这个已经很大的输出转储的大小。 如果有一种更简单的方法可以通过一些可视化来一目了然地了解内存使用情况,那就太好了。 这可以通过让脚本将结果转储到 CSV 或 JSON,然后在可视化工具中加载它们来完成。 更好的是,当数据流入时,我们可以绘制实时结果。 这提供了更新的视图,并允许我们实时观察正在发生的内存使用情况,所有这些都在一个工具中完成。
绘制内存使用情况
为了使该工具更加有用并提供可视化,将进行一些更改。
- 用户将在命令行上提供连接ID,脚本将负责查找底层线程。
- 脚本请求内存数据的频率也可以通过命令行进行配置。
- 该
matplotlib库将用于生成内存使用情况的可视化。 这将包含一个堆栈图,其中带有显示最高内存使用类别的图例,并将保留过去 50 个样本。
这是相当多的代码,但为了完整起见将其包含在此处。
#!/usr/bin/env python3
import matplotlib.pyplot as plt
import numpy as np
import MySQLdb
import argparse
MEM_QUERY='''
SELECT event_name, current_number_of_bytes_used
FROM performance_schema.memory_summary_by_thread_by_event_name
WHERE thread_id = %s
ORDER BY event_name DESC'''
TID_QUERY='''
SELECT thread_id
FROM performance_schema.threads
WHERE PROCESSLIST_ID=%s'''
class MemoryProfiler:
def __init__(self):
self.x = []
self.y = []
self.mem_labels = ['XXXXXXXXXXXXXXXXXXXXXXX']
self.ms = 0
self.color_sequence = ['#ffc59b', '#d4c9fe', '#a9dffe', '#a9ecb8',
'#fff1a8', '#fbbfc7', '#fd812d', '#a18bf5',
'#47b7f8', '#40d763', '#f2b600', '#ff7082']
plt.rcParams['axes.xmargin'] = 0
plt.rcParams['axes.ymargin'] = 0
plt.rcParams["font.family"] = "inter"
def update_xy_axis(self, results, frequency):
self.ms += frequency
self.x.append(self.ms)
if (len(self.y) == 0):
self.y = [[] for x in range(len(results))]
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
self.y[i].append(usage)
if (len(self.x) > 50):
self.x.pop(0)
for i in range(len(self.y)):
self.y[i].pop(0)
def update_labels(self, results):
total_mem = sum(map(lambda e: e[1], results))
self.mem_labels.clear()
for i in range(len(results)-1, -1, -1):
usage = float(results[i][1]) / 1024
mem_type = results[i][0]
# Remove 'memory/' from beginning of name for brevity
mem_type = mem_type[7:]
# Only show top memory users in legend
if (usage < total_mem / 1024 / 50):
mem_type = '_' + mem_type
self.mem_labels.insert(0, mem_type)
def draw_plot(self, plt):
plt.clf()
plt.stackplot(self.x, self.y, colors = self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.xlabel("milliseconds since monitor began")
plt.ylabel("Kilobytes of memory")
def configure_plot(self, plt):
plt.ion()
fig = plt.figure(figsize=(12,5))
plt.stackplot(self.x, self.y, colors=self.color_sequence)
plt.legend(labels=self.mem_labels, bbox_to_anchor=(1.04, 1), loc="upper left", borderaxespad=0)
plt.tight_layout(pad=4)
return fig
def start_visualization(self, database_connection, connection_id, frequency):
c = database_connection.cursor();
fig = self.configure_plot(plt)
while(True):
c.execute(MEM_QUERY, (connection_id,))
results = c.fetchall()
self.update_xy_axis(results, frequency)
self.update_labels(results)
self.draw_plot(plt)
fig.canvas.draw_idle()
fig.canvas.start_event_loop(frequency / 1000)
def get_command_line_args():
'''
Process arguments and return argparse object to caller.
'''
parser = argparse.ArgumentParser(description='Monitor MySQL query memory for a particular connection.')
parser.add_argument('--connection-id', type=int, required=True,
help='The MySQL connection to monitor memory usage of')
parser.add_argument('--frequency', type=float, default=500,
help='The frequency at which to ping for memory usage update in milliseconds')
return parser.parse_args()
def get_thread_for_connection_id(database_connection, cid):
'''
Get a thread ID corresponding to the connection ID
PARAMS
database_connection - Database connection object
cid - The connection ID to find the thread for
'''
c = database_connection.cursor()
c.execute(TID_QUERY, (cid,))
result = c.fetchone()
return int(result[0])
def main():
args = get_command_line_args()
database_connection = MySQLdb.connect(host='127.0.0.1', user='root', password='password')
connection_id = get_thread_for_connection_id(database_connection, args.connection_id)
m = MemoryProfiler()
m.start_visualization(database_connection, connection_id, args.frequency)
connection.close()
if __name__ == "__main__":
main()
有了这个,我们可以对MySQL查询的执行进行详细的监控。 要使用它,首先获取要分析的连接的连接 ID:
SELECT CONNECTION_ID();
然后,执行以下命令将开始监视会话:
./monitor.py --connection-id YOUR_CONNECTION_ID --frequency 250
当对数据库执行查询时,我们可以观察内存使用量的增加,并查看哪些类别的内存贡献最大。
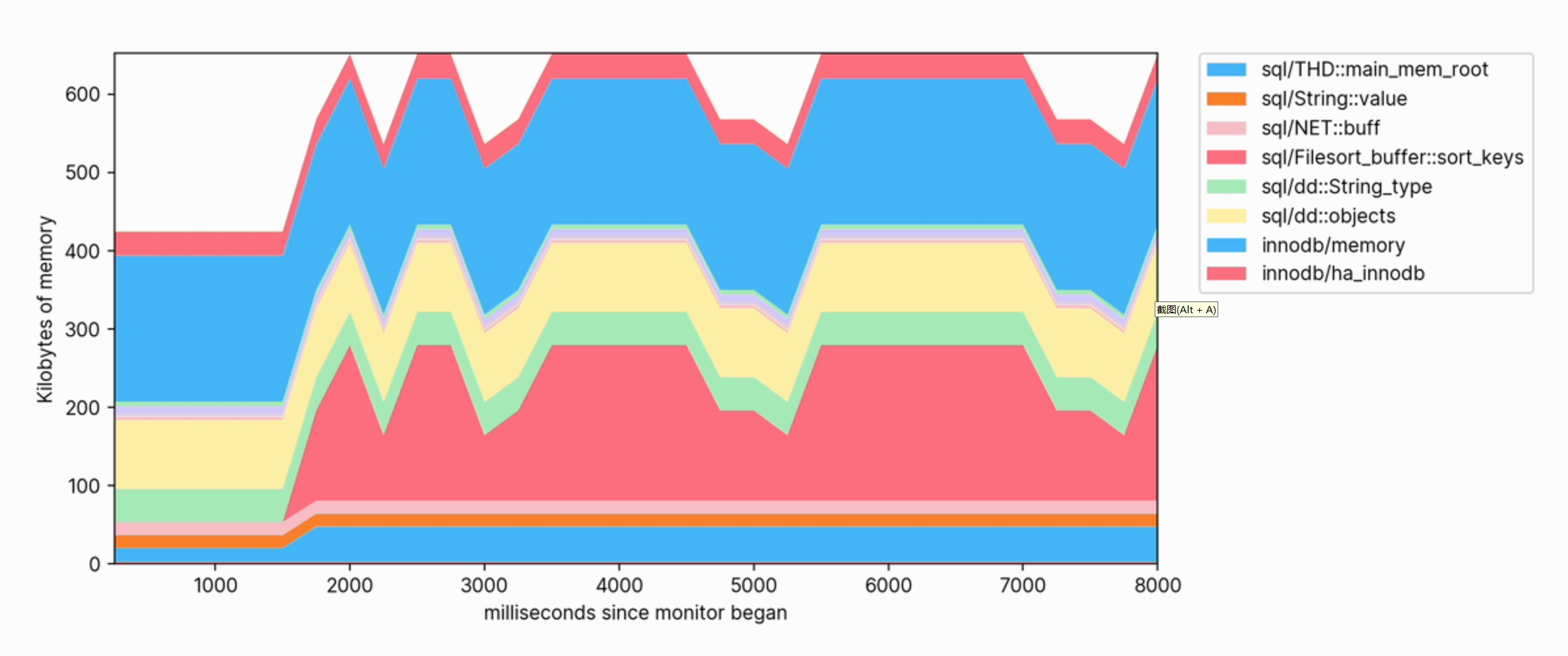
这种可视化还可以帮助我们清楚地看到哪些操作是占用内存的。 例如,以下是用于 FULLTEXT 在大型表上创建索引的内存配置文件的片段:
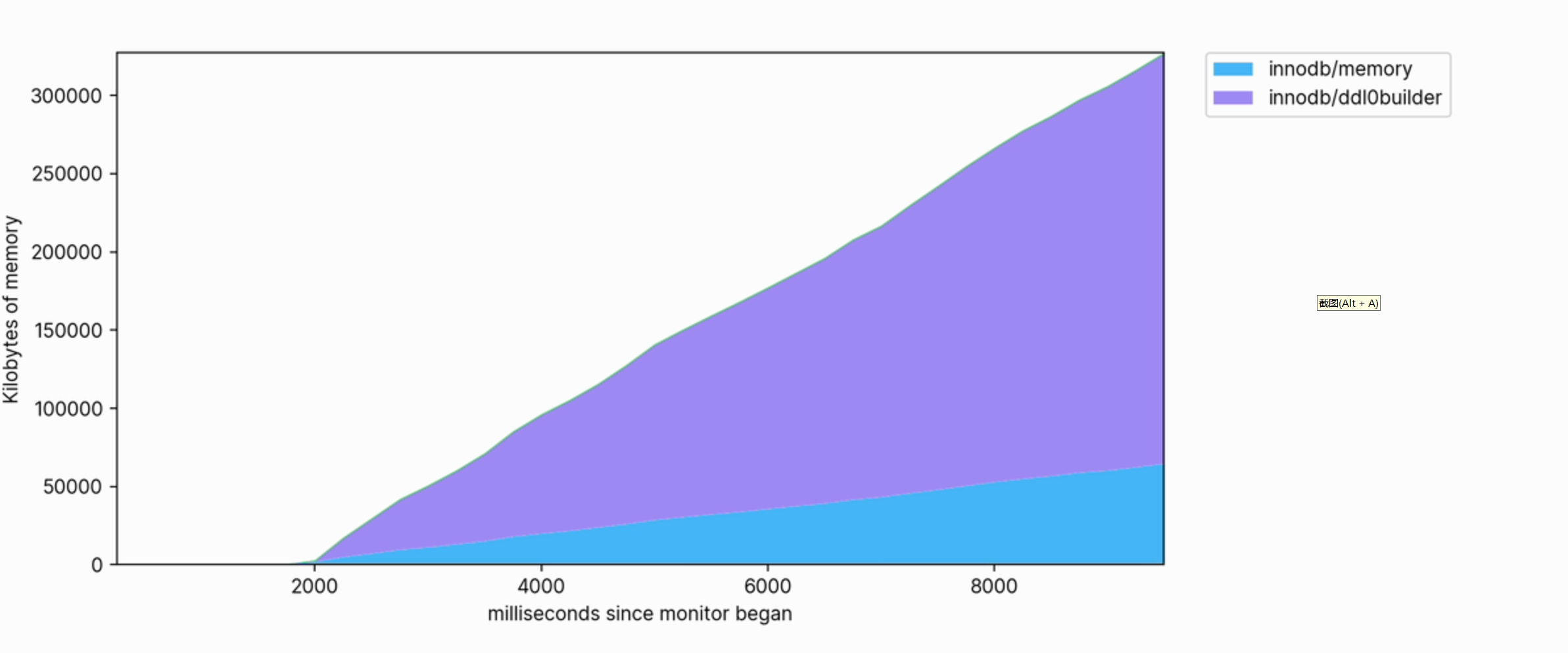
内存使用量很大,并且在执行时会继续增长到使用数百兆字节。
结论
尽管可能并不经常需要,但当需要详细的查询优化时,获取详细的内存使用信息的能力可能非常有价值。 这样做可以揭示 MySQL 何时以及为何会对系统造成内存压力,或者是否需要对数据库服务器进行内存升级。 MySQL 提供了许多原语,您可以在这些原语的基础上为您的查询和工作负载开发分析工具。
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。